https://thomwolf.substack.com/p/what-jobs-are-made-of
工作的本質 ---- 判斷力、主體性,以及 AI 評測指標的侷限性
Thomas Wolf 2025年12月22日
十五年前,也就是 2010 年的冬天,我正處於博士階段的最後衝刺期,開始探索學術界以外的世界。我記得在一個創紀錄嚴寒的巴黎冬日,參加完一場研發崗位的面試後乘車返回。到處都是積雪,我坐在寒冷的區域通勤火車上,感到既失望又有些困惑。
我熟悉該行業研發團隊使用的大部分工具,並有信心能輕鬆學會剩下的部分。然而,這似乎並不夠,面試官一直告訴我,他們正在尋找“更有經驗”的人。
當時,我並不真正理解這句話的含義。相比我能展示的具體知識,他們更看重工作年限,這讓我感到極度不公。在我二十出頭的時候,“經驗”聽起來更像是一個模糊的藉口,用來拒絕像我這樣既有明確能力又渴望學習的申請者。
這種久違的感覺最近又回來困擾我了。
看到近期關於初級崗位招聘萎縮的數據(尤其是軟件開發領域),我不禁想起了當年的自己。
斯坦福大學在 2025 年夏季進行的一項分析顯示,在 AI 暴露程度最高的職業中,22-25 歲的員工就業人數在 2022 年底至 2025 年中期下降了約 6%。而在同一時期,這些職業中資深員工的就業人數卻增加了約 6-9%。
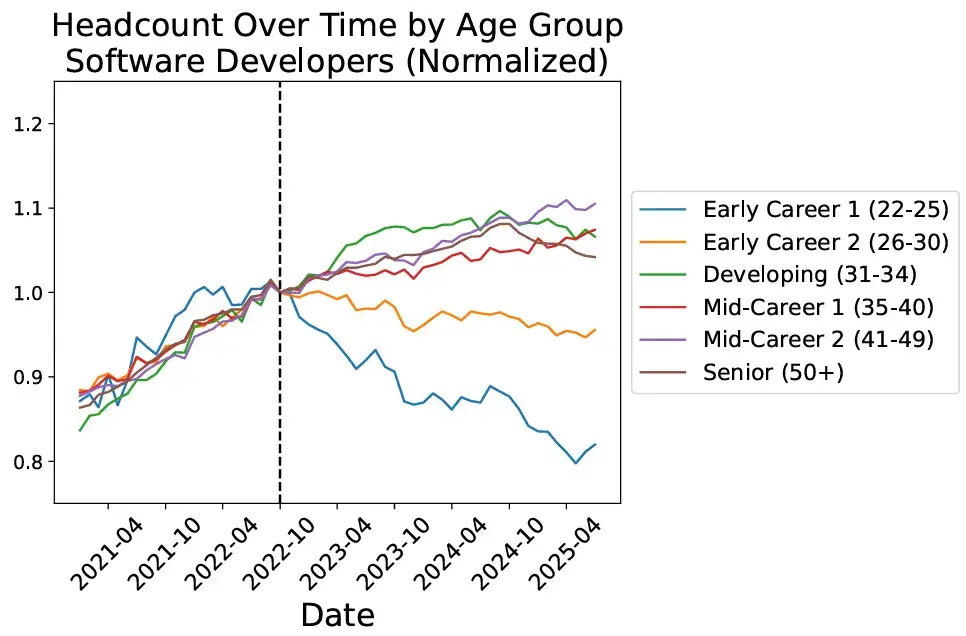
在這個圖表上,轉折點清晰可見。
無論是因為相關性還是因果關係,2022 年秋季標誌着 ChatGPT 的發佈——那是公眾發現 AI 模型真實能力的時刻,也是 AI 性能競賽真正點燃的時刻。這場競賽最初由 OpenAI 和 Anthropic 驅動,隨後 Google 以及 xAI、阿里巴巴 (Qwen)、DeepSeek、Mistral 等越來越多的公司也加入了第一梯隊。
在過去的三年裏,AI 評測指標(Benchmarks)的進步令人驚歎。像 Claude Opus 4.5 這樣的模型現在能在 SWE-bench上解決約 75% 的真實世界編程任務;Gemini 3 和 GPT 5 在科學奧林匹克競賽中達到了金牌水平⁴。與此同時,ChatGPT 的周活躍用户已接近 10 億⁵。
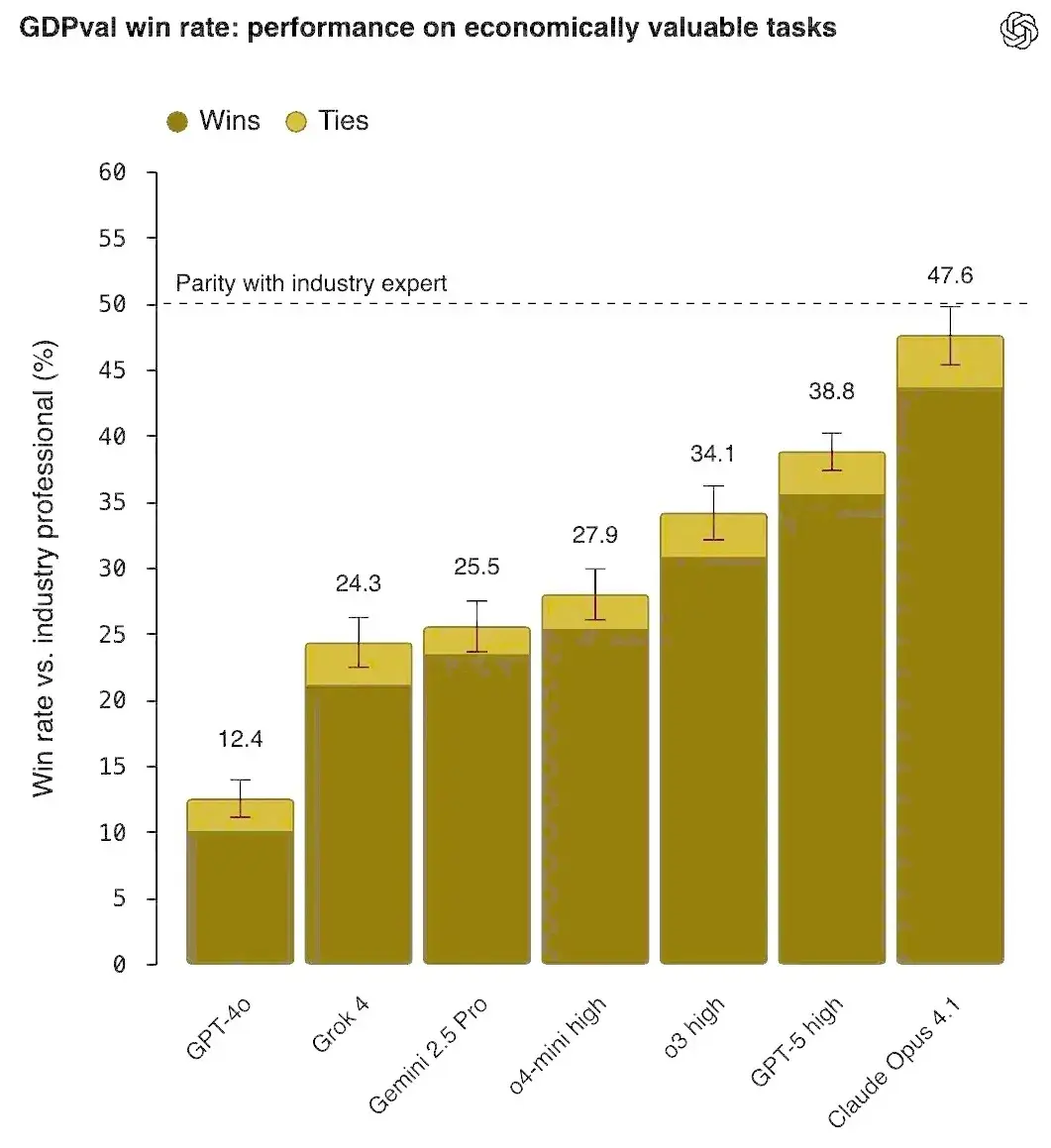
從許多技術指標來看,AI 的能力和普及率都以驚人的速度增長,往往預示着它已達到行業專家或人類專家的水平。
然而,儘管拿了獎牌、儘管初級招聘在下降,宏觀經濟的表現卻顯得平淡得多。
在全球和行業層面,AI 的影響依然有限,對 GDP 的拉動作用微乎其微。近期有説法稱,在那些光鮮的公告背後,許多(如果不是大多數)生成式 AI 的試點項目都未能為公司產生持續的價值⁷。此外,在一些模擬真實環境的測試中——例如評估 AI Agent 在真實兼職項目上表現的“遠程勞動指數”(Remote Labor Index),即使是目前最強大的系統(如 ManusAI),成功率也僅為 2.5% 左右。
模型在評測指標上展示的能力,似乎很難與組織內部正在發生的情況相調和。
對於這種“理論與實踐”之間的差距,通常有幾種解釋:一種是組織慣性,大公司反應慢,遺留系統混亂,部署困難;另一種可能性是,我們還沒跨過正確的能力閾值。也許在與人類智能相比的 AGI 定義和量化嘗試中,拿到接近 60% 的分數還是不夠的。
這些因素可能都發揮了作用。但它們往往傾向於將“工作”僅僅視為一種“任務執行”。
這種定義在我看來是不完整的。在實踐中,一份工作很少只是待執行任務的列表,一個同事也極少能被簡化為一捆技術技能的集合。
作為一名初創公司創始人,我有近 50% 的時間花在公司不同階段的招聘上,這可能是我人生中教訓最深的部分。其中一個教訓是:在面對大多數申請者和崗位時,我傾向於尋找三種品質的結合:
🌟執行力或技術技能:正確完成任務、掌握相關工具和方法的能力。
🌟常識或判斷力:理解任務為什麼重要,以及任務如何適應更廣泛的目標、公司價值觀、文化和方向。
🌟主體性(Agency)或品味:預判下一步該做什麼,該提議什麼,不該做什麼,什麼時候改變方向;有時,理解為什麼徹底停止任務才是最佳決策。
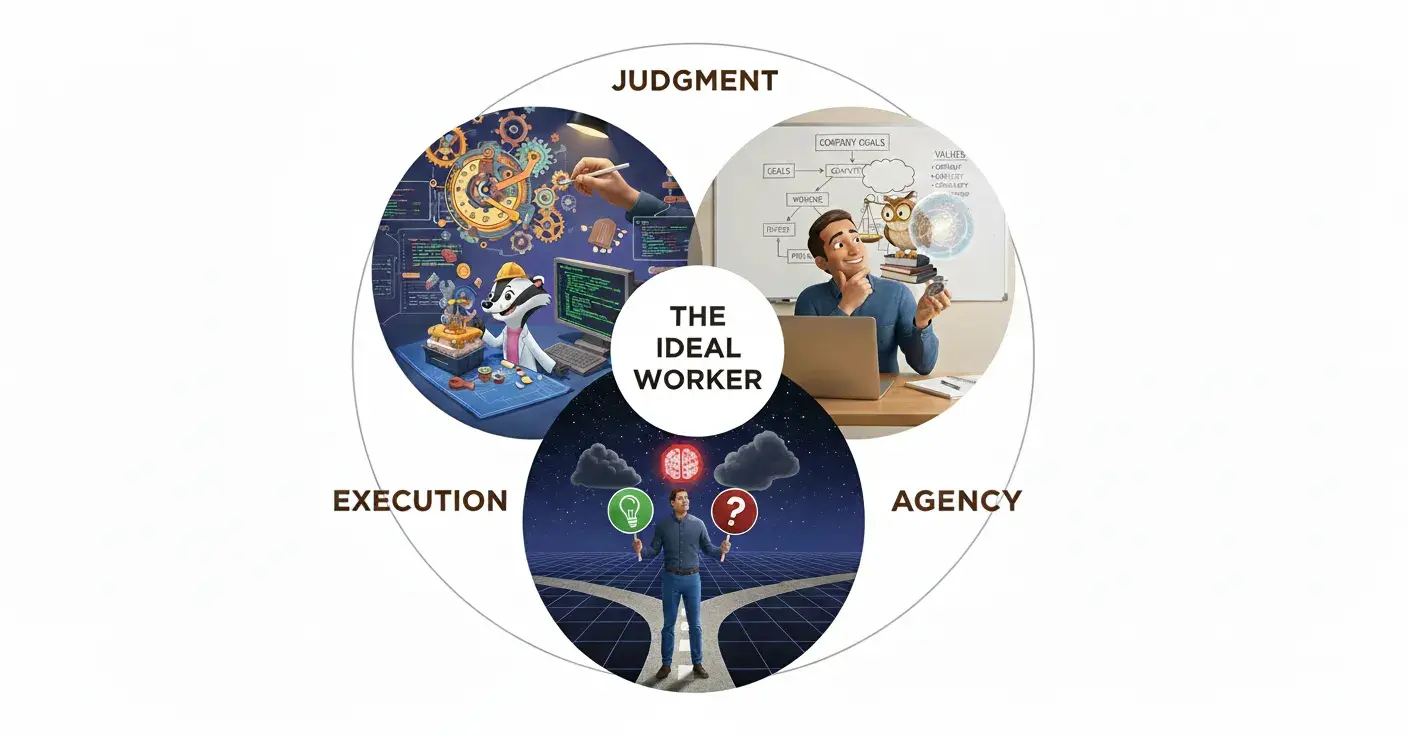
執行力和技術知識在評測指標中相對容易觀察、測試和衡量。一旦給定任務,核心就是解決它。
判斷力和主體性則極難評估。它們往往在非穩態或非衡平的情況下才顯現價值——當問題定義不明確、優先級發生轉移,或者正確的做法是質疑任務本身時。這通常是優秀的團隊成員開始脱穎而出的地方,也日益成為當今企業所處的常態。
通過這個視角,我終於理解了我 2010 年的那場面試。
我的面試官不僅在評估我是否會使用他們的工具和方法,他們還在隱性地評估:一旦問題不再被清晰定義時,我會如何表現。
這種對“勞動者”的定義,解釋了為什麼初級職位首先受到衝擊。職業生涯早期的角色傳統上更側重於執行。隨着時間的推移,隨着人們經驗的增長,他們的貢獻往往會轉向判斷力和主體性:定義問題、選擇工作內容以及應對模糊性。
AI 系統在“執行”方面的進步遠快於其他維度。結果是,執行層的成本變得更低、更薄,從而不成比例地影響了初級崗位的招聘。
從長期來看,這是令人擔憂的。判斷力和主體性部分源於天賦,但更多時候是在執行密集型的工作經驗中習得的。如果入門層流失太快,將會削弱產生未來資深人才的培養管道。
同樣的框架也有助於理解為什麼 AI 的經濟影響依然有限,以及自動化更長週期、更廣泛任務所面臨的挑戰。
AI 能力的限制因素通常不是孤立生成文本或代碼的能力,而是難以兼顧大局:將指令適應公司/團隊範圍的語境、解讀模糊的需求、排列優先級、進行基於常識的權衡,以及決定什麼才是重要的,甚至決定何時停止任務。
執行力顯然很重要。但它幾乎從來不是工作的全部。或者,正如 Cursor 的 Ryo Lu 最近寫的,執行並不是我們曾經認為的工作中最重要的部分:
----Ryo Lu (@ ryolu_ ) 傳統的團隊擴張方式已經過時了:
----我們過去習慣於聘請專家——設計師、工程師、產品經理——各司其職,通過增加人手來擴大規模。但當 Cursor 能讓你在幾分鐘內將想法變成代碼時,執行力就不再是瓶頸了。品味和判斷力才是。
挑戰在於,判斷力和主體性要難衡量得多。通常,它們只有在更廣泛的、非靜態的背景下才有意義,這解釋了為什麼它們在評測指標中受到的關注較少。
然而,它們通常是一個員工在組織中創造價值的核心。如果我們想真正理解 AI 的經濟潛力,我們最終需要超越技術執行的評估方式,去反映真實工作中跨團隊和縱向協作的本質,並承認:極少有工作是僅僅在一個完全靜態的環境中遵循一套預設的固定規則。
AI 時代最終可能會讓判斷力、品味和主體性佔據更高的權重——而這些恰恰是工作中最難量化、最難評測、也最難被取代的部分。
回過頭看,AI 評測性能與經濟影響之間的這種差距,對於 20 歲時的我來説,其實是有一種似曾相識的熟悉感的。
來源:https://weibo.com/2194035935/QjH4Fh95o
