導讀
AI 編碼工具正在從"智能補全"演進為能自主完成複雜任務的 Coding Agent。本文基於開源項目源碼研究與實踐經驗,系統性地拆解 Coding Agent 的工作原理。旨在幫助開發者在瞭解Coding Agent後,與AI夥伴更好的協作配合,更高效的提問和拿到有效結果。
01 背景
AI 編碼工具的發展速度快得有點"離譜"。從開始使用 GitHub Copilot 的代碼補全,到使用Claude Code、Cursor、Comate IDE等完成複雜編程任務,AI 不再只是個「智能補全工具」,它能讀懂你的代碼庫、執行終端命令、甚至幫你調試問題,成為你的“編碼夥伴”。
我自己在團隊裏推 AI 編碼工具的時候,發現一個很有意思的現象:大家都在用,但很少有人真正理解它是怎麼工作的。有人覺得它"很神奇",有人吐槽它"經常亂來",還有人擔心"會不會把代碼搞亂"。這些困惑的背後,其實都指向同一個問題:我們對這個"夥伴"還不夠了解。
就像你不會無腦信任一個新來的同事一樣,要和 AI 編碼夥伴配合好,你得知道它的工作方式、能力邊界、以及怎麼"溝通"才更有效。
在經過多次的實踐嘗試後,我嘗試探索它的底層原理,並寫下了這篇文章記錄,主要圍繞了這些內容展開:
-
Coding Agent 的核心工作機制,包括身份定義、工具調用、環境感知等基礎組成。
-
從零實現一個最小化 Coding Agent 的完整過程,以建立對 Agent 工作流程的直觀理解。
-
上下文管理、成本控制、衝突管控等生產環境中的關鍵技術問題及其解決方案。
-
Rule、MCP、Skill 等能力擴展機制的原理與應用場景。
在瞭解原理後,我和夥伴的協作更佳順暢,讓夥伴更清晰的瞭解我的意圖,我拿到有效的回答。
02 概念
2.1 從Workflow到Agent
取一個實際的例子:休假申請。
如果我們的需求非常簡單:
一鍵申請明天的休假。

這個需求可以被簡化為一個固定的工作流:
-
打開網頁。
-
填寫起始時間。
-
填寫結束時間。
-
填寫休假原因。
-
提交表單。
全過程沒有任何模糊的輸入,使用程序化即可完成,是最原始的工作流形態。
如果需求再模糊一些:
申請後天開始3天休假。
這個需求的特點是沒有明確的起始和截止時間,需要從語義上分析出來:
-
起始時間:後天。
-
休假時長:3天。
-
轉換日期:10.14 - 10.16。
-
執行申請:提交表單。
這是一個工作流中使用大模型提取部分參數的典型案例,是模型與工作流的結合。
如果需求更加模糊:
國慶後休假連上下個週末。
這樣的需求幾乎沒有任何直接確定日期的信息,同時由於年份、休假安排等動態因素,大模型不具備直接提取參數的能力。將它進一步分解,需要一個動態決策、逐步分析的過程:
-
知道當前年份。
-
知道對應年份的國慶休假和調休安排。
-
知道國慶後第一天是星期幾。
-
國慶後第一天到下個週末設為休假日期。
-
額外補充調休的日期。
-
填寫並提交表單。
可以看出來,其中1-5步都是用來最終確定休假日期的,且需要外部信息輸入,單獨的大模型無法直接完成工作。這是一個典型的Agent流程,通過大模型的智能與工具訪問外部信息結合實現用户需求。
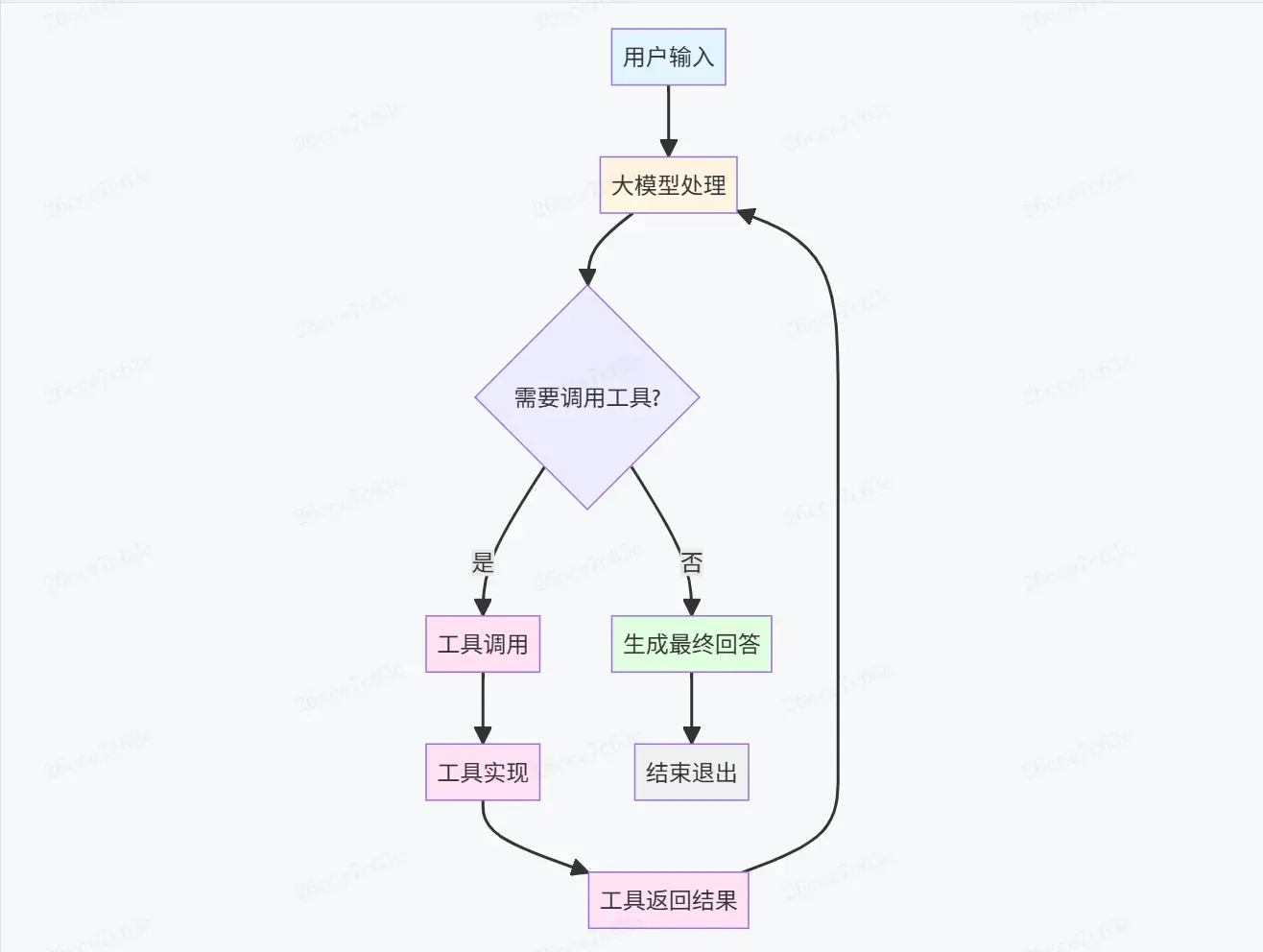
2.2 什麼是Agent
Agent是以大模型為核心,為滿足用户的需求,使用一個或多個工具,自動進行多輪模型推理,最終得到結果的工作機制。
2.3 什麼是Coding Agent
在Agent的基本定義的基礎上,通過提示詞、上下文、工具等元素強化“編碼”這一目的,所製作的特化的Agent即為Coding Agent。
Coding Agent的最大特徵是在工具的選取上,模擬工程師進行代碼編寫的環境,提供一套完整的編碼能力,包括:
-
閲讀和查詢代碼:
-
讀取文件,對應
cat命令。 -
查看目錄結構,對應
tree命令。 -
通配符查找,對應
ls命令(如**/*.test.ts、src/components/**/use*.ts)。 -
正則查找,對應
grep命令(如function print\(.+\)可以找函數定義)。 -
LSP(Language Server Protocol),用於提供查找定義、查找引用、檢查代碼錯誤等能力。
-
-
編寫或修改代碼:
-
寫入文件。
-
局部編輯文件。
-
刪除文件。
-
-
執行或交互命令:
-
執行終端命令。
-
查看終端命令
stdout輸出。 -
向終端命令
stdin輸入內容。
-
除此之外,通常Coding Agent還具備一些強化效果而設定的工具,通常表現為與Agent自身或外部環境進行交互,例如經常能見到的TODO、MCP、Subagent等等。
03 內部組成
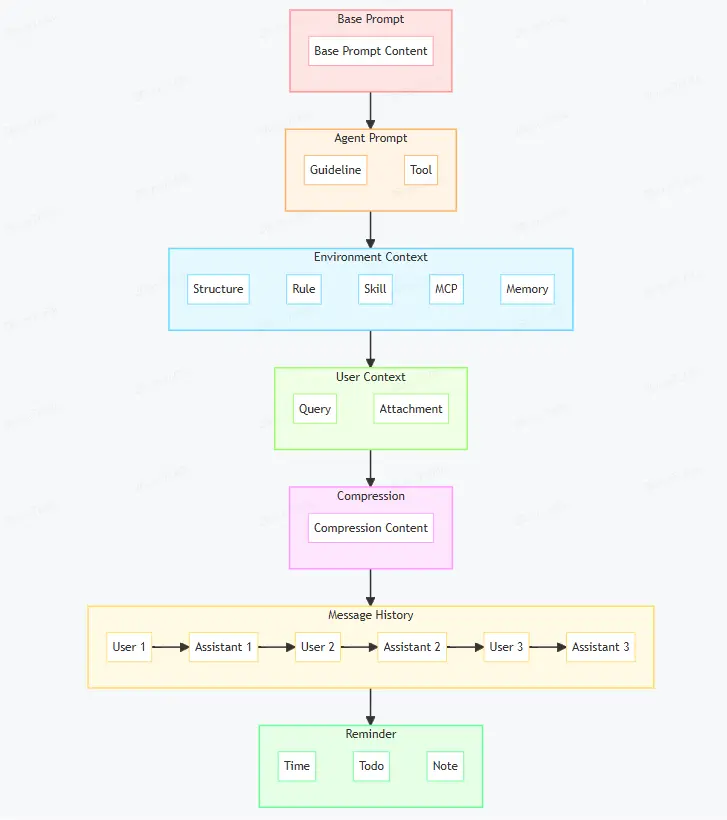
3.1 上下文結構
3.2 身份定義
一個Agent首先會將模型定義成一個具體的身份(紅色與橙色部分),例如在社區裏常見的這樣的説法:
You are a Senior Front-End Developer and an Expert in React, Nexts, JavaScript, TypeScript, HTML, CSS and modern UI/UX frameworks.
在身份的基礎上,再附加工作的目標和步驟拆解,比如Cline有類似這樣的內容:
https://github.com/cline/cline/blob/4b9dbf11a0816f792f0b3229a08bbb17667f4b73/src/core/prompts/system-prompt/components/objective.ts
-
Analyze the user's task and set clear, achievable goals to accomplish it. Prioritize these goals in a logical order.
-
Work through these goals sequentially, utilizing available tools one at a time as necessary. Each goal should correspond to a distinct step in your problem-solving process. You will be informed on the work completed and what's remaining as you go.
-
Remember, you have extensive capabilities with access to a wide range of tools that can be used in powerful and clever ways as necessary to accomplish each goal. Before calling a tool, do some analysis within
<thinking></thinking>tags. First, analyze the file structure provided inenvironment_detailsto gain context and insights for proceeding effectively. Then, think about which of the provided tools is the most relevant tool to accomplish the user's task. Next, go through each of the required parameters of the relevant tool and determine if the user has directly provided or given enough information to infer a value. When deciding if the parameter can be inferred, carefully consider all the context to see if it supports a specific value. If all of the required parameters are present or can be reasonably inferred, close the thinking tag and proceed with the tool use. BUT, if one of the values for a required parameter is missing, DO NOT invoke the tool (not even with fillers for the missing params). DO NOT ask for more information on optional parameters if it is not provided. -
Once you've completed the user's task, you must use the attempt_completion tool to present the result of the task to the user. You may also provide a CLI command to showcase the result of your task; this can be particularly useful for web development tasks, where you can run e.g.
open index.htmlto show the website you've built. -
The user may provide feedback, which you can use to make improvements and try again. But DO NOT continue in pointless back and forth conversations, i.e. don't end your responses with questions or offers for further assistance.
不用特別仔細地看每一句話,多數Coding Agent會提供一些詳實的行動準則、目標要求,這部分稱為“Guideline”。
有一些Coding Agent可以在多種模式(或者説智能體)之間進行切換,例如Cursor有Edit、Ask、Plan等,RooCode有Architect、Orchestrator等,有些產品還支持自定義模式。
Cursor
RooCode
選擇不同的模式時,實際上會產生不同的目標要求、行為準則,即不同的Guideline環節。因此係統提示詞中的身份部分,通常會分成不變的Base Prompt(紅色)和可變的Agent Prompt(橙色)兩個部分來管理,實際開始任務時再拼裝起來。
3.3 工具調用
Agent的另一個最重要的組成部分是工具,沒有工具就無法稱之為一個Agent。讓Agent能夠使用工具,就必須要有2部分信息:
-
有哪些工具可以用,分別是什麼作用。
-
如何指定使用一個工具。
對於第一點(哪些工具),在Agent開發過程中,一般視一個工具為一個函數,即由以下幾部分組成一個工具的定義:
-
名稱。
-
參數結構。
-
輸出結構。
實際在調用模型時,“輸了結構”往往是不需要提供給模型的,但在Agent的實現上,它依然會被預先定義好。而“名稱”和“參數結構”會統一組合成一個結構化的定義,通常所有工具都只接收1個參數(對象類型),用JSON Schema表示參數結構。
一個典型的工具定義:
{
"name": "read",
"description": "Read the contents of a file. Optionally specify line range to read only a portion of the file.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "The file path to read from"
},
"lineStart": {
"type": "integer",
"description": "The starting line number (1-indexed). If not specified, reads from the beginning of the file."
},
"lineEnd": {
"type": "integer",
"description": "The ending line number (1-indexed). If not specified, reads to the end of the file."
}
},
"required": ["path"]
}
}可以簡單地把這個工具理解成對應的TypeScript代碼:
interface ReadToolParameter {
path: string;
lineStart?: number;
lineEnd?: number;
}
async function read(parameters: ReadToolParameter) {
// 工具實現
}對於第2點(指定使用工具),則是要讓大模型知道工具調用的具體格式。這在業界通常有2種做法。
第1種以Claud Code、Codex等為典型,使用大模型提供的Function Calling格式調用,分為以下幾步:
-
在調用大模型時,通過一個
tools字段傳遞所有的工具定義。 -
模型會返回一個消息中包含
tool_calls字段,裏面每一個對象是一個工具的調用,使用id作為唯一標識。 -
工具產生的結果,以一條
role: 'tool'的消息返回,其中tool_call_id與調用的id對應,content是工具的結果(這裏各家模型廠商的實現略有不同,其中Anthropic要求role: user,但content字段中傳遞toolResult,其結構是[{type: 'tool_result',tool_use_id: toolBlock.id, content: toolResultContent}],tool_use_id與調用的id對應)。
第2種方式是以Cline、RooCode為典型,使用一種自定義的文本格式來表示工具調用,通常選擇XML的結構,例如對於Cline,讀取一個文件的結構如下:
<read_file>
<path>src/index.ts</path>
</read_file>
只要在模型返回的消息中出現這樣的結構,就會被解析為一個工具調用,得到的結果以普通的role: 'user' 的消息返回,包括實際內容和一些提示相關的信息。
Content of src/index.ts:
Note:
- this file is truncated to line 1000, file has a total 2333 lines.
- use read_file with line_start and line_end parameters to read more content.
- use seach_in_files tool searching for specific patterns in this file.
...
3.4 環境感知
Coding Agent之所以可以在一個代碼庫上執行任務,除了通過工具來遍歷、檢索代碼外,另一個因素是Agent實現會在調用模型時主動地提供一部分與項目有關的信息。
其中對Coding Agent工作最有用的信息之一是代碼庫的結構,即一個表達出目錄、文件結構的樹型區塊。這部分信息通常會符合以下特徵:
-
儘可能地保留目錄的層級結構,使用換行、縮進的形式表達。
-
遵循
.gitignore等項目配置,被忽略的文件不會表現在樹結構中。 -
當內容過多時,有一定的裁剪的策略,但同時儘可能多地保留信息。
以Cursor為例,這部分的內容大致如下:
<project_layout>
Below is a snapshot of the current workspace's file structure at the start of the conversation. This snapshot will NOT update during the conversation. It skips over .gitignore patterns.
codex-cursor/
- AGENTS.md
- CHANGELOG.md
- cliff.toml
- codex-cli/
- bin/
- codex.js
- rg
- Dockerfile
- package-lock.json
- package.json
- scripts/
- build_container.sh
- build_npm_package.py
- init_firewall.sh
- [+4 files (1 *.js, 1 *.md, 1 *.py, ...) & 0 dirs]
- codex-rs/
- ansi-escape/
- Cargo.toml
- README.md
- src/
- lib.rs
</project_layout>
當內容數量超過閾值時,會採用廣度優先的保留策略(即儘可能地保留上層目錄結構),同時對於被隱藏的文件或子目錄,會形如 [+4 files (1 *.js, 1 *.md, 1 *.py, ...) & 0 dirs]這樣保留一個不同文件後綴的數量信息。
除了目錄結構外,還有一系列默認需要模型感知的信息,在一個Coding Agent的工作環境中,它通常分為2大類,各自又有一系列的細項:
-
系統信息:
-
操作系統(Windows、macOS、Linux,具體版本)。
-
命令行語言(Shell、Powershell、ZSH)。
-
常見的終端命令是否已經安裝(
python3、node、jq、awk等,包含具體版本)。 -
代碼庫目錄全路徑。
-
-
為Agent擴展能力的信息:
-
Rule(自動激活的部分)。
-
Skill(摘要描述部分)。
-
MCP(需要的Server和Tool列表)。
-
Memory(通常是全量)。
-
需要注意的是,環境信息這部分,一般不出現在系統提示詞中,而是和用户提問的消息放置在一起。
3.5 簡單實現
在身份定義、工具調用、環境感知這3部分最基礎的Agent組成都達成後,簡單地使用大模型的API,進行自動化的工具調用解析、執行、發送新一輪模型調用,可以非常簡單地實現一個最小化的Coding Agent。
可以嘗試用以下的提示詞,使用任意現有的Coding Agent產品,為你編寫一個實現,並自己調試一下,感受Coding Agent的最基礎的邏輯:
我希望基於大模型實現一個Coding Agent,以下是我的具體要求:
1. 使用Claude作為模型服務商,使用環境變量管理我的API Key。
2. 默認使用Claude Sonnet 4.5模型。
3. 使用Anthropic's Client SDK調用模型。
4. 不需要支持流式輸出。
5. 使用TypeScript編寫。
以下是Agent提供的工具:
1. read({path: string}):讀取一個文件的內容
2. list({directory: string}):列出一個目錄下的一層內容,其中目錄以`/`結尾
3. write({path: string, content: string}):向文件寫入內容
4. edit({path: string, search: string, replace: string}):提供文件中的一塊內容
以下是交互要求:
1. 通過NodeJS CLI調用,支持`query`和`model`兩個參數,可以使用`yargs`解析參數。
2. 在System消息中,簡短地説明Coding Agent的角色定義、目標和行為準則等。
3. 在第一條User消息中,向模型提供當前的操作系統、Shell語言、當前目錄絕對路徑信息,同時包含跟隨`query`參數的內容,組織成一條模型易於理解的消息。
4. 對每一次模型的工具調用,在控制枱打印工具名稱和標識性參數,其中標識性參數為`path`或`directory`,根據工具不同來決定。
5. 如果模型未調用工具,則將文本打印到控制枱。
請在當前目錄下建立一個`package.json`,並開始實現全部的功能。
04 優質上下文工程
4.1 成本控制
大模型是一個非常昂貴的工具,以Claude為例,它的官方API價格如下:
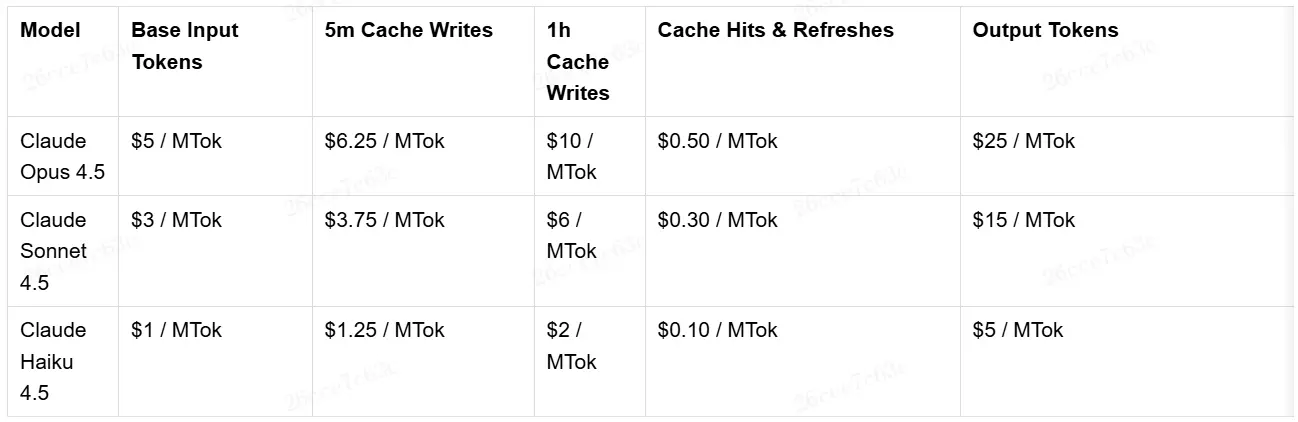
我們可以觀察到一些特徵:
-
輸出的價格是輸入的5倍(但實際考慮到輸出與輸出的數量比例,輸出的價格根本不值一提)。
-
緩存輸入(Cache Writes)比正常輸入(Base Input)更貴一些,約1.25倍。
-
緩存命中(Cache Hits)的價格比正常輸入(Base Input)要便宜很多,為1/10的價格。
這就意味着,一個良好使用緩存的Agent實現,其成本會比不用緩存降低8-10倍。因此所有的Coding Agent一定會細緻地梳理內容結構,最大化利用緩存。
在大模型的API中,緩存通常以“塊”為單位控制,例如:
-
系統提示詞中不變的部分。
-
系統提示詞中可變部分。
-
工具定義。
-
每一條消息,單條消息也可以拆成多個塊。
繼續觀察Claude對於緩存控制的文檔:
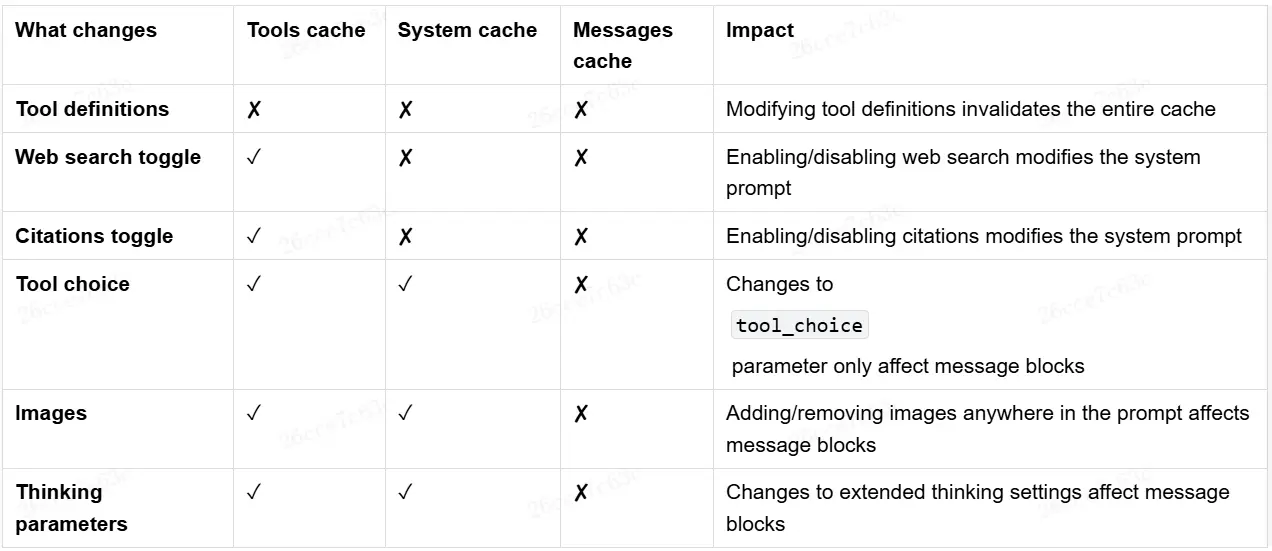
可以看到,在大模型API中各種參數一但有所變動,緩存都會大量失效(至少消息緩存全部失效,大概率系統緩成失效),這就會造成成本的極大提升。因此,在Coding Agent實現中,都會從一開始就確定所有參數,整個任務不做任何變更。一些很經典的實例:
-
一次任務不會一部分消息開思考模式,一部分不開,因為思考參數會讓全部的消息緩存失效。
-
切換不同模式(如Edit、Ask、Plan)時,雖然能使用的工具不同,但只是在消息中增加説明,而不會真的將
tools字段改變。
另外,Coding Agent會儘可能保持歷史消息內容完全不變,以最大化地緩存消息。例如對於一個進行了10輪模型調用的任務,理論上第10次調用中,前9輪的消息內容都會命中緩存。但如果此時擅自去修改了第1輪的工具調用結果(例如試圖刪除讀取的文件內容),看似可能消息的長度減少了,但實際因為緩存被破壞,造成的是10倍的成本提升。
總而言之,緩存是一個至關重要的因素,Coding Agent的策略優化通常以確保緩存有效為前提,僅在非常必要的情況下破壞緩存。
4.2 空間管理
Coding Agent因為會自動地與大模型進行多輪的交互,隨着不斷地讀入文件、終端命令輸出等信息,上下文的長度會變得非常的大,而大模型通常只具備128K左右的總長度,因此如何將大量內容“適配”到有限的長度中,是一個巨大的挑戰。
控制上下文長度的第一種方式是“裁剪”,即在整個上下文中,將沒用的信息刪除掉。試想如下的場景:
-
模型讀取了一個文件的內容。
-
模型將文件中
foo這一行改成了bar。 -
模型又將文件中
eat這一行改成了drink。
假設我們對模型每一次修改文件,都返回最新的文件內容,如果這個文件有1000行,那麼1次讀取、2次修改,就會產生3000行的空間佔用。
一種優化方式就是,在這種連續的讀-改的場景下,只保留最後一條消息中有全文內容,即上述3次模型調用後,出現在上下文中的內容實際是這樣的:
<!-- Assistant -->
read(file)
<!-- User -->
[This file has been updated later, outdated contents are purged from here]
<!-- Assistant -->
edit(file, foo -> bar)
<!-- User -->
The edit has been applied successfully.
--- a/file
+++ b/file
@@ -23,1 +23,1 @@
-foo
+bar
[This file has been updated later, outdated contents are purged from here]
<!-- Assistant -->
edit(file, eat -> drink)
<!-- User -->
The edit has been applied successfully, the new file content is as below:
```
{content of file}
```
可以看到,通過將連續對同一文件的修改進行裁剪,可以只保留最新的內容,同時又使用unidiff 之類的形式保留中間編輯的差異信息,最大限度地降低空間佔用,又能保留模型的推理邏輯。
但裁剪不能使用在非連續的消息中,隨意地使用剪裁邏輯,很有可能破壞消息緩存結構,進而使模型調用的輸入無法通過緩存處理,幾倍地增加模型的調用成本。
即便裁剪有一定效果,但隨着更多的內容進入到上下文中,始終會有將上下文佔滿的時候,此時模型將完全無法進行推理。為了避免這種情況出現,Coding Agent通常會使用“壓縮”這一技術,即將前文通過模型摘要成少量的文字,同時又保留比較關鍵的推理鏈路。
通常,壓縮在上下文即將用完的時候觸發,如已經使用了90%的上下文則啓動壓縮,壓縮的目標是將90%的內容變為10%的長度,即省出80%的空間供後續推理。
壓縮本身是一個模型的任務,即將所有的上下文(可以選擇性地保留最新的1-2對消息)交給模型,同時附帶一個壓縮的要求,讓模型完成工作。這個壓縮的要求的質量將決定壓縮的最終結果,一個比較典型的實現是Claude Code的“八段式摘要”法:
const COMPRESSION_SECTIONS = [
"1. Primary Request and Intent", // 主要請求和意圖
"2. Key Technical Concepts", // 關鍵技術概念
"3. Files and Code Sections", // 文件和代碼段
"4. Errors and fixes", // 錯誤和修復
"5. Problem Solving", // 問題解決
"6. All user messages", // 所有用户消息
"7. Pending Tasks", // 待處理任務
"8. Current Work" // 當前工作
];
通過將信息壓縮成8部分內容,能夠最大限度地保留工作目標、進度、待辦的內容。
4.3 獨立上下文
在實際的應用中,其實大概率是不需要128K上下文用滿的,但真實表現又往往是上下文不夠用。這中間存在的差異,在於2類情況:
-
為了滿足一個任務,需要收集大量的信息,但收集到正常信息的過程中,會引入無效的、錯誤的內容,佔用上下文。
-
一個任務足夠複雜,分解為多個小任務後各自佔用部分上下文,但加起來以後會超出限制。
試想一下,對於一個這樣的任務:
修改我的Webpack配置,調整文件拆分邏輯,讓最終產出的各個JS文件大小盡可能平均。
但是很“不幸”地,這個項目中存在6個 webpack.config.ts文件,且最終splitChunks 配置在一個名為 optimization.ts 的文件中管理,那麼對於Coding Agent來説,這個任務中就可能存在大量無意義的上下文佔用:
-
讀取了6個
webpack.config.ts,一共2000行的配置內容,但沒有任何splitChunks的配置,包含了大量import其它模塊。 -
又讀取了10個被
import的模塊,最終找到了optimization.ts文件。 -
經過修改後,執行了一次
npm run build來分析產出,發現JS的體積不夠平均。 -
又修改
optimization.ts,再次編譯,再看產出。 -
循環往復了8次,終於在最後一次實現了合理的
splitChunks配置。
這裏面的“6個 webpack.config.ts ”、“10個其它模塊”、“8次優化和編譯”都是對任務最終目標並不有效的內容,如果它們佔用150K的上下文,這個任務就不得不在中途進行1-2次的壓縮,才能夠最終完成。
為了解決這個問題,當前多數的Coding Agent都會有一個稱為“Subagent”的概念。就好比一個進程如果只能使用4GB的內存,而要做完一件事需要16GB,最好的辦法就是開5個進程。Subagent是一種類似子進程的,在獨立的上下文空間中運行,與主任務僅進行必要信息交換的工作機制。
再回到上面的案例,在Subagent的加持下,我們可以將它變成以下的過程:
-
啓動一個Subagent,給定目標“找到Webpack文件拆分的代碼”。
-
讀取6個
webpack.config.ts。 -
讀取10個被
import的模塊。 -
確定目標文件
optimization.ts。 -
返回總結:在
optimization.ts中有文件拆分的配置,當前配置為……。
-
-
啓動一個Subagent,給定目標“修改
optimization.ts,使產出的JS體積平均,執行npm run build並返回不平均的文件“。-
修改
optimization.ts。 -
執行
npm run build,得到命令輸出。 -
分析輸出,找到特別大的JS文件,返回總結:配置已經修改,當前
xxx.js體積為平均值的3倍(723KB),其它文件體積正常。
-
-
啓動一個Subagent,給寶目標“分析
dist/stats.json,檢查xxx.js中的模塊,修改optimization.ts使其分為3個250KB左右的文件,執行npm run build並返回不平均的文件”。-
……
-
……
-
-
繼續啓動6次Subagent,直到結果滿意。
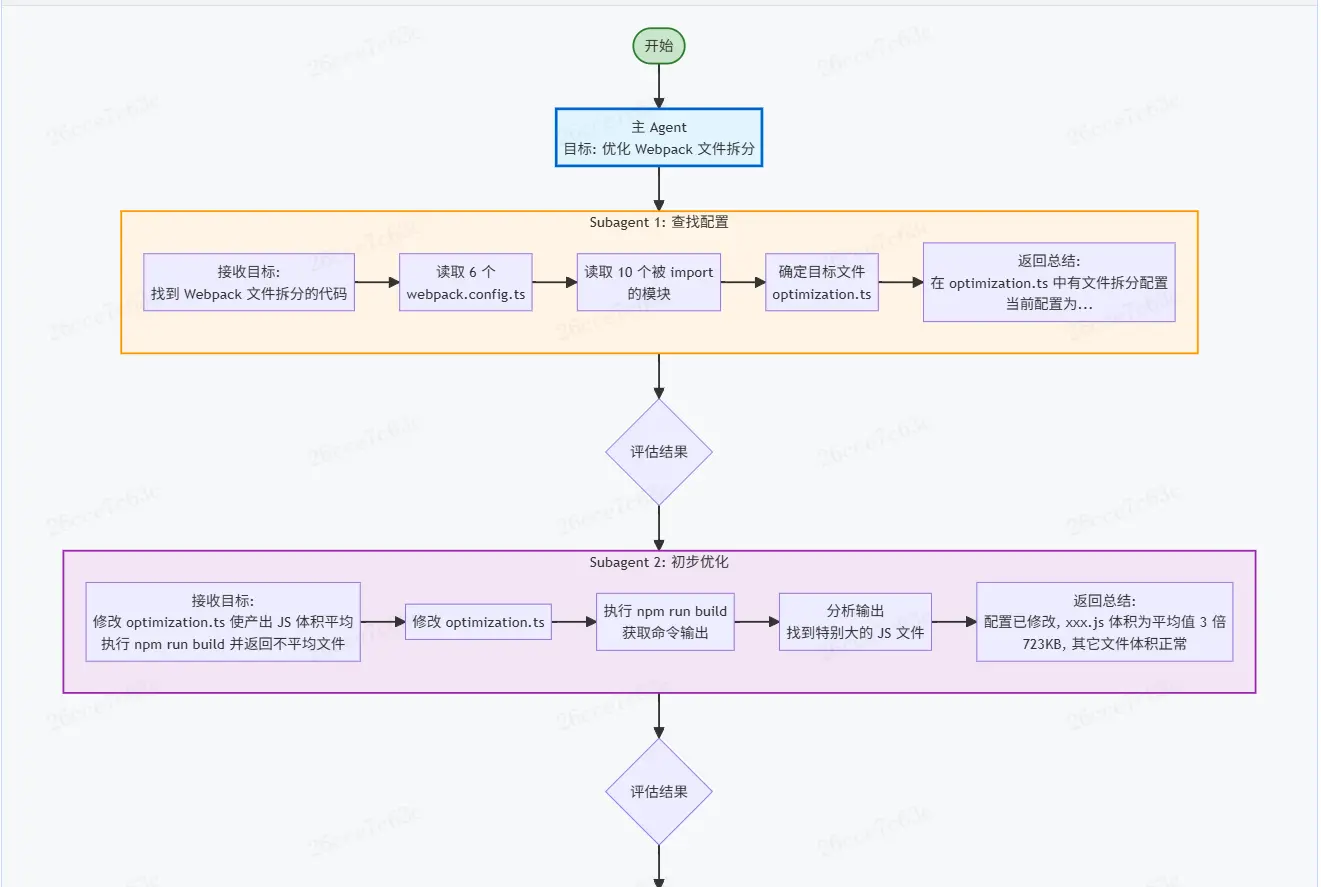
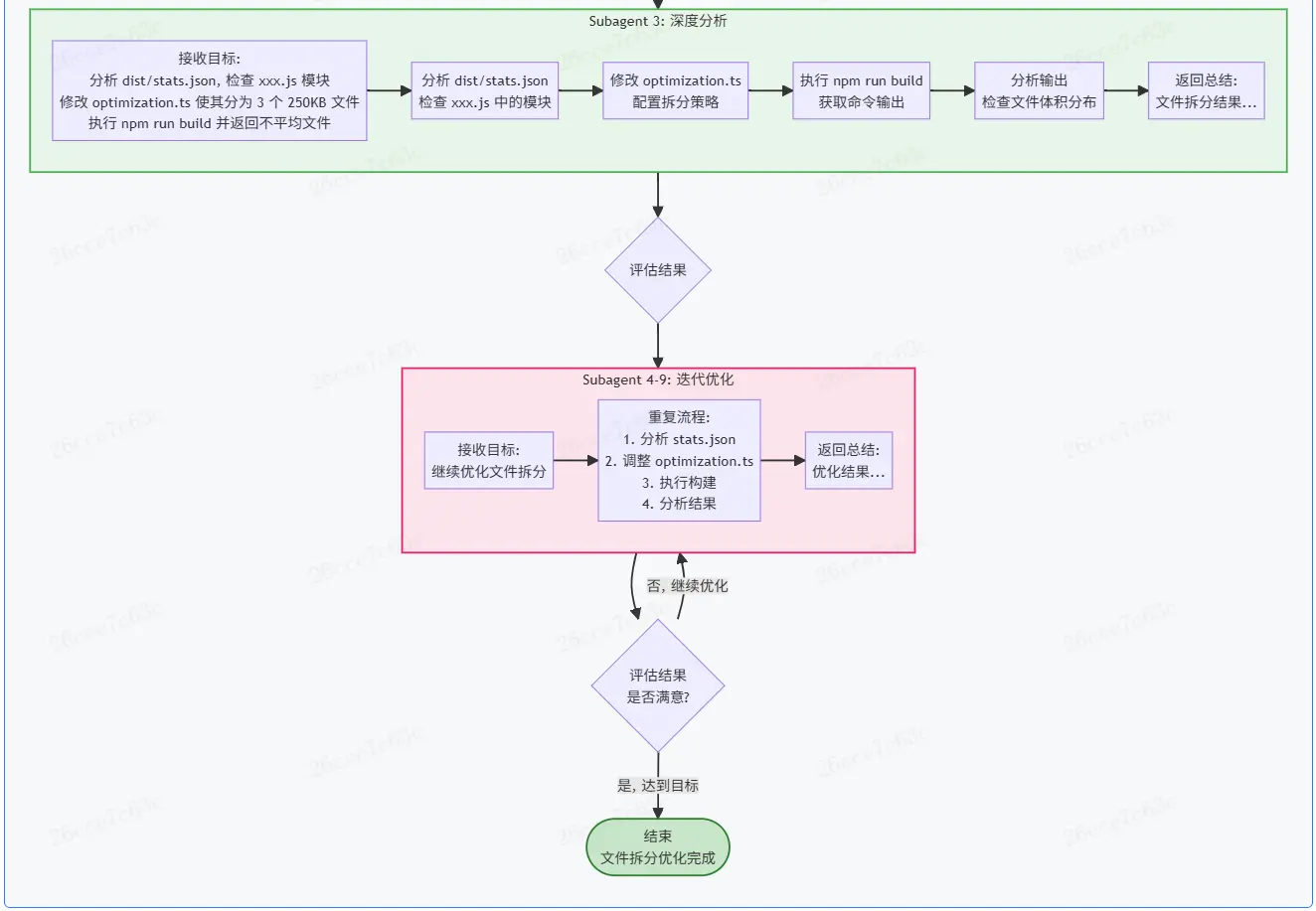
不難看出來,這種模式下主體的Coding Agent實際是在"指揮"Subagent做事,自身的上下文佔用是非常有限的。而Subagent僅****“專注”於一個小目標****,也不需要太多的上下文,最終通過這類不斷開闢新上下文空間的方式,將一個複雜的任務完成。
4.4 注意力優化
如果你經常使用Coding Agent,或在業界早期有過比較多的使用經驗,你可能會發現這種情況:Coding Agent在完成一個任務到一半時,忘了自己要做什麼,草草地結束了任務,或偏離了既定目標產生很多隨機的行為。
會發生這樣的情況,有一定可能是裁剪、壓縮等策略使有效的上下文信息丟失了,但更多是因為簡單的一個用户需求被大量的代碼內容、命令輸出等推理過程所掩蓋,權重弱化到已經不被大模型“注意到”,因此最初的目標也就完全丟失了。
Coding Agent一個很重要的任務,就是在長時間運作的同時隨時調整大模型的注意力,使其始終聚焦在最終目標、關注當前最需要做的工作,不要偏離預先設定的路線。為了實現這一效果,Coding Agent產品提出了2個常見的概念。
第一稱為TODO,在很多的產品中,你會看到Agent先將任務分解成幾個步驟,轉為一個待辦列表。這個列表在界面上始終處於固定的位置,隨着任務的推進會逐步標記為完成。這個TODO實際上並不是給用户看的,而是給模型看的。
在實際的實現中,每一次調用模型時,在最後一條消息(一般就是工具調用的結果)上,除了原始消息內容外,會增加一個稱為“Reminder”的區域。這個區域因為始終出現在所有消息的最後,通常來説在模型的注意力中優先級更高,而且絕對不會受其它因素影響而消失。
Reminder中可以放置任意內容,比較經典的有:
- TODO及進度。用於模型時刻理解目標、進展、待辦。
<reminders>
- Planned todos:
- [x] Explore for code related to "print" function
- [x] Add "flush" parameter to function
- [ ] Refactor all "print" function calls to relect the new parameter
</reminders>- 工具子集。如前面《緩存》相關的描述,因為修改工具定義會使緩存失效,因此當切換模式使得可用的工具減少時,一般僅在Reminder中説明部分工具不可用,由模型來遵循這一約束,而不是直接刪除部分工具。
<!-- 切換至Ask模式 -->
<reminders>
- You can ONLY use these tools from now on:
- read
- list
- grep
- bash
</reminders>
- 行為指示。例如當模型連續多次給出名稱、參數都一模一樣的工具調用時,説明模型處在一種不合理的行為表現上,此時在Reminder中增加提示,讓模型感知到當前狀態的錯誤,就有可能調整並脱離錯誤的路線。
<!-- Assistant -->
read(file)
<!-- User -->
The file content: ...
<!-- Assistant -->
read(file)
<!-- User -->
The file content: ...
<reminders>
- Your are using read tool the second time with exactly the same parameters, this usually means an unexpected situation, you should not use this tool again in your response.
</reminders>
- 狀態提示。例如激活某一個Skill時,Reminder中可以提示“當前正在使用名為X的Skill“,這種提示可以讓模型更加專注於完成一個局部的工作。
<reminders>
- You are currently working with the skill "ppt" active, be focused on this task until you quit with exit_skill tool.
</reminders>
需要額外注意的是,Reminder僅在最後一條消息中出現,當有新的消息時,舊消息上的Reminder會被移除。基於這一特徵,我們知道Reminder是永遠無法命中緩存的,因此Reminder部分的內容長度要有控制,避免造成過多的成本消耗。
4.5 衝突管控
隨着Coding Agent能力的發展,當下執行的任務時間越來越長、編輯的文件越來越多,同時更多的用户也習慣於在Agent工作的同時自己也進行編碼工作,甚至讓多個Agent任務併發執行。這種“協同”形態下,不少用户曾經遇到過這樣的問題:
自己將Agent生成的代碼做了一些修正,但之後Agent又把代碼改了回去。
這個現象的基本原因也很清楚,就是Agent並不知道你改動過代碼。例如以下的過程使Agent讀取並編輯了一個文件:
<!-- Assistant -->
read(file)
<!-- User -->
The file content:
...
console.log('hello');
...
<!-- Assistant -->
edit(file, hello -> Hello)
<!-- User -->
Edit has been applied successfully.
這個時候,在模型見到的上下文中,這個文件中的代碼顯然是console.log('Hello'); 。假設乃又將它改成了console.trace('Hello'); ,後面模型依然會基於.log 來修改代碼,用户看起來就是代碼“改了回去”。
解決這種共同編輯文件的衝突,實際上有多種方法:
- 加鎖法。當Agent讀取、編輯一個文件時,更新模型認知的文件內容的快照。當這個Agent再一次編輯這個文件時,讀取文件當前的實際內容,和快照做比對,如果內容不一樣,拒絕這一次編輯,隨後要求Agent重新讀取文件(更新快照與實際內容一致)再進行編輯。這是一種主流的做法,不過Agent實現上的細節比較重。
<!-- Assistant -->
edit(file, console.log...)
<!-- User -->
This edit is rejected, the file has been modified since your last read or edit, you should read this file again before executing any write or edit actions.
<!-- Assistant -->
read(file)
<!-- User -->
The file content: ...
<!-- Assistant -->
edit(file, console.trace...);
- 推送法。監聽所有模型讀取、編輯過的文件的變更,當文件發生變更時,在下一次模型調用時,不斷通過Reminder區域追加這些變更,讓模型“實時”地知道文件有所變化,直到文件被下一次讀取。這種方式能讓模型更早地感知變化,但推送信息可能過多,影響成本和推理速度。
<!-- Assistant -->
run_command(ls)
<!-- User -->
The command output: ...
<reminders>
- These files have been modified since your last read or edit, you should read before write or edit to them:
- file
- file
- ...
</reminders>
- 隔離法。使用Git Worktree方案,直接讓不同的Agent任務在文件系統上隔離,在一個獨立的Git分支上並行工作,相互不受干擾。在任務完成後,用户檢查一個任務的全部變更,在採納時再合併回實際的當前Git分支,有衝突的由用户解決衝突。這種方法讓Agent根本不需要考慮衝突問題,但缺點是系統資源佔用高,且有合併衝突風險。
文件編輯衝突只是一個比較常見的現象,實際上用户和Agent、多個Agent並行工作,可能造成的衝突還有很多種,例如:
用户敲了半行命令
ls -,Agent直接在終端裏敲新的命令grep "print" -r src執行,導致最後的命令是ls -grep "print" -r src,是一個不合法的命令。
終端的搶佔也是一種衝突,但相對更容易解決,只要讓每一個Agent任務獨佔自己的終端,永遠不與用户、其它Agent任務相交叉即可。
4.6 持久記憶
我們都知道,模型是沒有狀態的,所以每一次Agent執行任務,對整個項目、對用户的傾向,都是從零開始的過程。這相當於歷史經驗無法積累,很多曾經調整過的細節、優化過的方向都會被重置。雖然可以通過比如Rule這樣的方式去持久化這些“經驗”,但需要用户主動的介入,使用成本是相對比較高的。
因此當前很多Coding Agent產品都在探索“記憶”這一能力,爭取讓Agent變得用的越多越好用。記憶這個話題真正的難點在於:
-
如何觸發記憶。
-
如何消費記憶。
-
什麼東西算是記憶。
首先對於“如何觸發”這一問題,常見於2種做法:
-
工具型。定義一個
update_memory工具,將記憶作為一個字符串數組看待,工具能夠對其進行增、刪改,模型在任務過程中實時地決定調用。往往模型並不怎麼喜歡使用這類工具,經常見於用户有強烈情感的描述時才出現,比如“記住這一點”、“不要再……”。 -
總結型。在每一次對話結束後,將對話全部內容發送給模型,並配上提示詞進行記憶的提取,提取後的內容補充到原本記憶中。總結型的方案往往又會過度地提取記憶,將沒必要的信息進行持久化,干擾未來的推理。
-
存儲型。不進行任何的記憶整理和提取,而是將所有任務的原始過程當作記憶,只在後續“消費”的環節做精細的處理。
然後在“如何消費”的問題下,也常見有幾種做法:
-
始終附帶。記憶內容記錄在文件中,Agent實現中將文件內容附帶在每一次的模型請求中。即模型始終能看到所有的記憶,這無疑會加重模型的認知負擔,也佔用相當多的上下文空間,因為很多記憶可能是與當前任務無關的。
-
漸進檢索。本身不帶記憶內容到模型,但將記憶以文件系統的形式存放,Agent可以通過
read、list、grep等工具來檢索記憶。配合“存儲型”的觸發方式,能讓全量的歷史任務都成為可被檢索的記憶。但這種方式要求模型有比較強的對記憶的認知,在正確的時刻去找相關的記憶。但往往因為根本不知道記憶裏有什麼,進而無法知道什麼時候應該檢索,最終幾乎不觸發檢索。
而最終的問題,“什麼東西是記憶”,是當下Coding Agent最難以解決的問題之一。錯誤的、不必要的記憶甚至可能造成實際任務效果的下降,因此精確地定義記憶是Agent實現的首要任務。
通常來説,記憶會分為2種大的方向:
-
事實型。如“使用4個空格作為縮進”、“不要使用
any類型“,這些都是事實。事實是無關任何情感、不帶主觀情緒的。 -
畫像型。如”用户更喜歡簡短的任務總結“就是一種對用户的畫像。畫像是單個用户的特徵,並不一定與項目、代碼、架構相關。
在Coding Agent上,往往更傾向於對”事實型“的內容進行記憶,而不考慮用户畫像型的記憶。
同時,從業界的發展,可以看到越來越多的模型廠商在從底層進行記憶能力的開發,如最近Google的Titan架構就是一種記憶相關的技術。可能未來某一天,Agent實現上已經不需要再關注記憶的邏輯與實現,模型自身將帶有持久化的記憶能力。
05 能力擴展
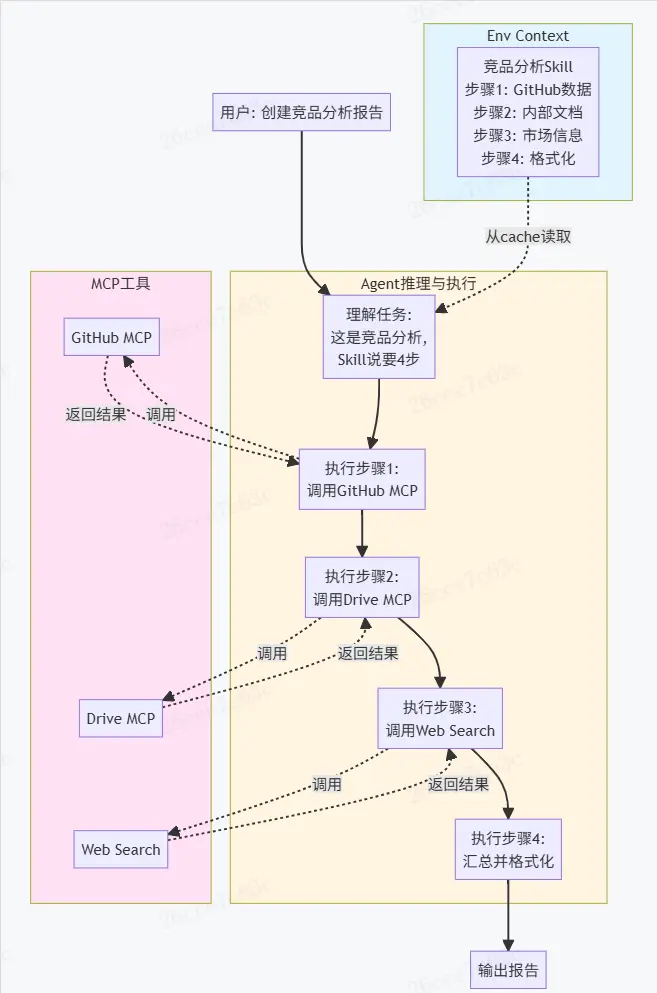
在實際應用中,還需要一些機制來讓Agent更好地適應特定的項目、團隊和個人習慣。當前主流的Coding Agent產品都提供了Rule、MCP、Skill這三種擴展能力,它們各有側重,共同構成了Agent的能力增強體系。
5.1 Rule
當面對業務的repo往往存在一些領域相關的知識而非模型的知識庫中已有的內容,這些往往需要憑藉老員工的經驗或者讀取大量代碼庫的信息進行總結後才能明白,這些內容便適合放到Rule中,作為靜態的不會頻繁改動的內容放入Environment Context中長期Cache。
好的Rule應當足夠精簡、可操作且範圍明確,人看不懂的規則或者描述不清的規則模型是一定搞不定無法遵守的。
-
將Rule控制在 500 行以內。
-
將較大的規則拆分為多個可組合的規則,採取按需的方式,按照 文件路徑/關鍵場景 激活Rule;對於特定場景激活的Rule,採取編寫索引的方式創建Rule,讓模型漸進式激活,比如項目針對網絡請求和錯誤處理相關做了項目維度的封裝處理,但這種情況並不是每個文件ts/tsx文件都會遇到的訴求,比如在項目的rules目錄下創建index.mdr(curso是.mdc文件),編寫下面的激活的條件:
-
需要進行API調用獲取數據
-
處理異步操作的錯誤和加載狀態
-
當編碼涉及以下任一情況時,必須立刻閲讀 [08-api-error-handling.mdc](mdr:.cursor/rules/08-api-error-handling.mdc)
-
-
提供具體示例或參考文件,針對xx情況正確的方式是`code`。
-
避免模糊的指導,比如交互式的東西模型交互不了,不需要寫進去。
-
為了模型能夠積極驗證每次改動是否符合預期,告知模型改動後可以執行的正確的構建命令,以及某些自定義命令(比如自動化測試)引導模型在後台啓動命令,在xx秒後讀取日誌文件的內容進行結果的判斷。
5.2 MCP
MCP(Model Context Protocol)是Anthropic提出的一種標準化的工具擴展協議,它允許開發者以統一的方式為Coding Agent添加新的能力。
與Rule的"聲明式約束"不同,MCP是一種實時工具調用協議,即通過MCP server的方式進行連接,來擴展Agent可以做的事情。
一個典型的場景是集成外部服務。比如你的項目託管在GitHub上,可以讓Agent直接訪問GitHub實現創建Issue、查詢PR狀態、添加評論等功能:
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<your-github-token>"
}
}
}
}配置好後,Agent就能在代碼審查過程中自動創建Issue記錄問題、查詢相關PR的討論、甚至根據代碼變更自動生成commit message。
MCP的另一個優勢是實現門檻低。一個MCP Server本質上就是一個標準輸入輸出的程序,它通過JSON-RPC協議與Agent通信,當模型需要外部能力的時候,調用MCP Server,而模型無需關心其內部代碼實現,Agent只需要按照固定的協議去連接獲取內容。
5.3 Skill
5.3.1 什麼是Skill
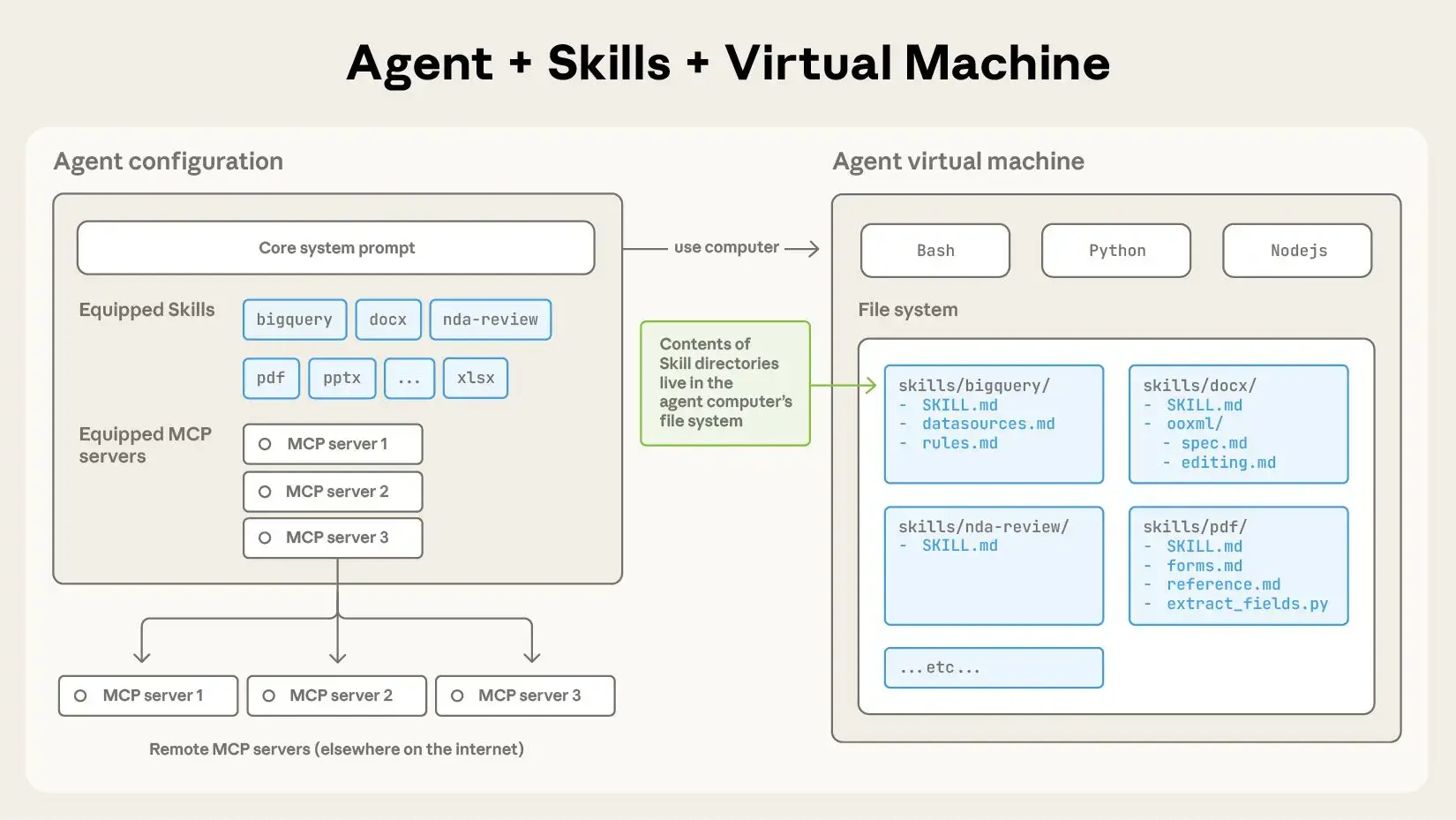
隨着模型能力的提升,使用Agent完成的任務複雜度逐漸增加,使用Coding Agent可以進行本地代碼執行和文件系統完成跨領域的複雜任務。但隨着這些Agent的功能越來越強大,我們需要更具可組合性、可擴展性和可移植性的方法,為它們配備特定領域的專業知識,因此Agent Skill作為一種為Agent擴展能力的標準誕生。Skill 將指令、腳本和資源的文件夾打包,形成專業領域的知識,Agent在初始化的時候會獲取可用的Skills列表,並在需要的時候動態加載這些內容來執行特定任務。
隨着 Skill 複雜性的增加,它們可能包含過多的上下文信息,無法放入單個配置文件中 SKILL.md,或者某些上下文信息僅在特定場景下才相關。在這種情況下,Skill可以在當前目錄中bundle額外的文件,並通過文件名引用這些文件,這些額外的文件提供了更多詳細信息,Coding Agent 可以根據需要選擇瀏覽和查找這些信息。Skill 是漸進式觸發的, 因此 SKILL.md中 name和 description很關鍵,這會始終存在於Agent的環境上下文中提供給模型,模型會根據這些描述信息來決定是否在當前任務中觸發該Skill,當你明確希望使用某個Skill完成任務,可以在prompt中指定“使用xxxx Skill完成xx任務”。
5.3.2 Skill和代碼執行
LLM在很多任務上表現出色,但許多操作需要使用編寫代碼 -> 代碼執行的方式,帶來更高效的操作、確定性的以及可靠性的結果。生成式的模型常常通過生成可執行代碼的方式去驗證/計算結果。
代碼既可以作為可執行工具,也可以作為文檔。Skill中應該明確讓模型是應該直接運行腳本,還是應該將其作為參考信息讀取到上下文中。
5.3.3 如何創建Skill
每個Skill由一個必需的 SKILL.md 文件和可選的bundle資源組成,Skill 應該只包含完成任務所需的信息。
skill-name/
├── SKILL.md (必需)
│ ├── YAML frontmatter 元數據 (必需)
│ │ ├── name: (必需)
│ │ ├── description: (必需,這是 skill 的主要觸發機制,幫助模型理解何時使用該 skil)
│ │ └── compatibility: (可選)
│ └── Markdown 説明 (必需)
└── bundle的資源 (可選)
├── scripts/ - 可執行代碼 (Python/Bash/等)
├── references/ - 需要時加載到上下文的文檔
└── assets/ - 用於輸出的文件 (模板、圖標、字體等)
舉一個具體的例子,比如當我們需要進行批量項目的技術棧migrate,比如將less遷移postcss,中間涉及一系列的複雜步驟,比如:
-
安裝postcss以及postcss plugin的依賴
-
配置postcss的config
-
分析項目用到了哪些less varibale替換成css vars
-
刪除mixin並替換
-
一系列的其他兼容less的語法轉換...
-
替換文件後綴
上面的工作可以通過清晰的流程描述,並配合腳本實現,因此可以作為一個Skill將經驗變成可複製的,一個less-to-postcss的skill的結構:
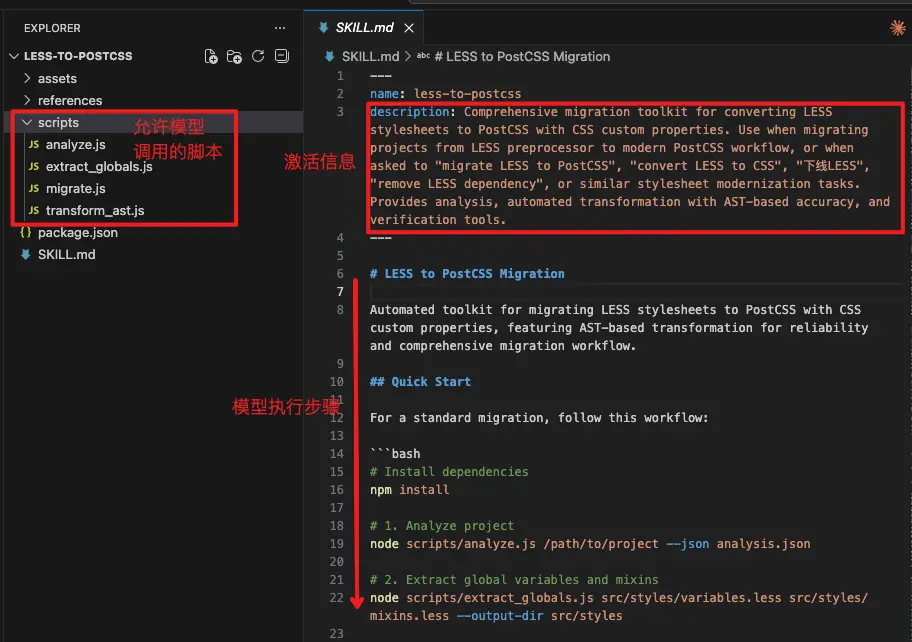
5.3.4 Skill的使用
人人都可以創建Skill,也可以讓Agent來編寫Skill,這是Skill非常便捷的地方。Skill通過instructions和code賦予Coding Agent新的能力。雖然這使其功能強大並有很高的自由度,但也意味着惡意SKill可能會在其使用環境中引入漏洞,誘使模型竊取數據並執行非預期操作。僅從可信來源安裝Skill,如果無法確信來源可信,在使用前請務必進行徹底審核。
Skill的出現並不是替代MCP的出現,而是相互配合,在合適的場景下選取Skill或是MCP。某些任務Skill和MCP Server均可完成,但Skill通過執行代碼的方式可以一次性加載完整流程,但MCP Server要經歷多次查詢和多輪對話往返,這種情況下Skill更為合適,但這不意味着絕對的優勢,比如標準化文檔創建這個典型的場景,創建PPT/Word/Excel在本地使用Skill即可完成,但數據的提供則需要藉助MCP Server進行查詢。因此Skill擅長的是在本地通過執行 code的方式完成複雜任務,在用户私有數據、動態數據查詢這些情況下Skill就無法搞定了,這和用户的數據庫以及隱私強關聯,需要讓模型無法感知在執行過程中的隱私信息,Skill能夠與MCP Server互補完成更為複雜的流程。