OpenAI 發佈最新技術博客,披露了其如何將開源關係型數據庫 PostgreSQL 擴展到前所未有的規模,以支撐 ChatGPT 和 API 的全球業務,這一實踐刷新了業內對傳統數據庫可擴展性的認知。
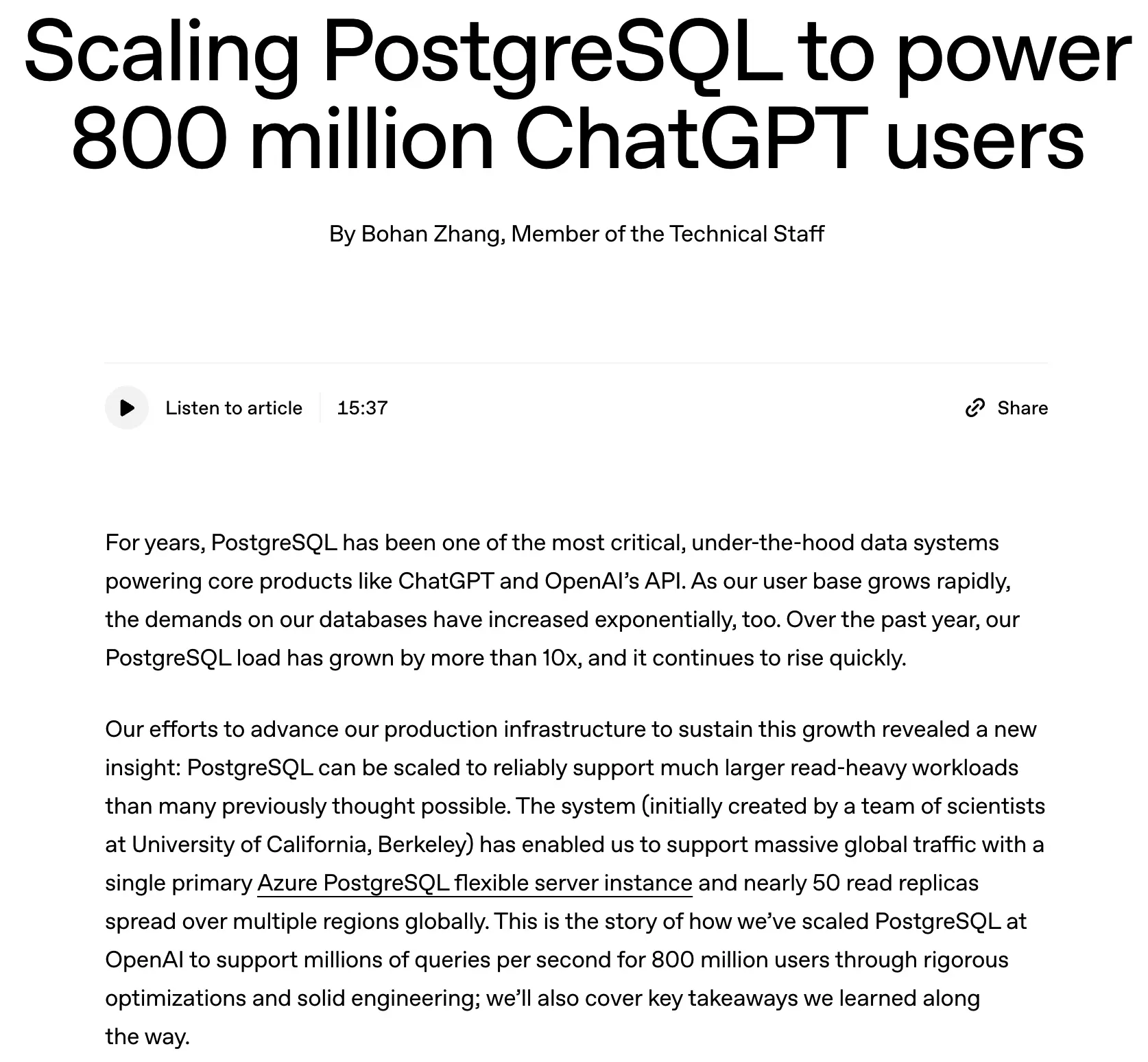
隨着 ChatGPT 用户數快速增長,OpenAI 過去一年裏 PostgreSQL 的數據庫負載激增超過 10 倍。為了滿足數百萬級查詢/秒(QPS)的請求並保持低延遲性能,他們在架構上進行了大量優化。
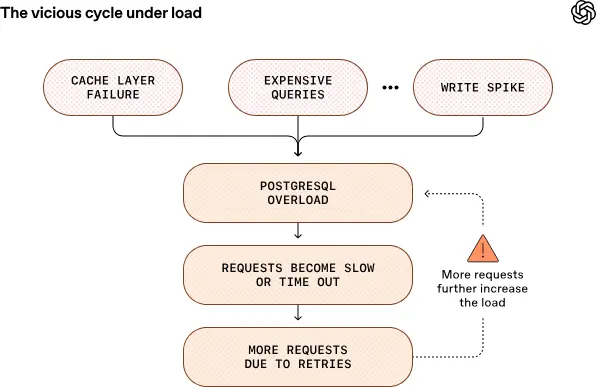
核心架構依舊採用單主庫(single-primary) + 多隻讀副本方案,主庫負責寫入工作,約 50 個只讀副本分佈全球多個區域用來處理讀取請求。這樣既避免了複雜的分片系統,又能支持大規模讀負載。
核心優化策略
1. 分離讀寫,並減少寫入壓力
為了防止主庫寫入瓶頸,OpenAI 將可拆分的寫密集型工作負載遷移到分片系統(如 Azure Cosmos DB),並在應用邏輯層儘量減少不必要的寫操作。
2. 讀查詢儘可能下放到副本
主庫僅保留必須在寫事務中運行的查詢,其他讀取由全球副本處理,大幅減少主節點負載。
3. 連接池與緩存策略
使用 PgBouncer 做連接池代理,把數據庫連接延遲從約 50ms 降到 5ms,並結合高效緩存策略避免緩存雪崩事件引發數據庫突發壓力。
4. 限制複雜查詢與優先級隔離
避免資源密集型的多表 JOIN,必要時將複雜邏輯移到應用層。使用資源隔離機制,將低優先級請求隔離到單獨實例,防止“吵鬧鄰居”影響高優先級流量。
5. 高可用性與故障緩解
主庫採用高可用 HA 模式,並配有熱備實例,在故障時能快速切換,保障服務連續性。
經過這些系統性優化,OpenAI 的 PostgreSQL 設計達成了:
-
幾百萬 QPS 的讀性能
-
全球低延遲訪問
-
99.999% 可靠性
-
極低的 p99 延遲(十幾毫秒級)
在過去 12 個月裏,只有一次嚴重數據庫級事件(SEV-0),發生在 ImageGen 功能爆發式增長時。
OpenAI 的案例表明,傳統的 PostgreSQL 在強工程實踐與架構優化下,能夠支持極大規模的生產級負載,這對於很多沒有充分理由提前採用複雜分佈式數據庫的團隊來説,具有重要的參考價值。
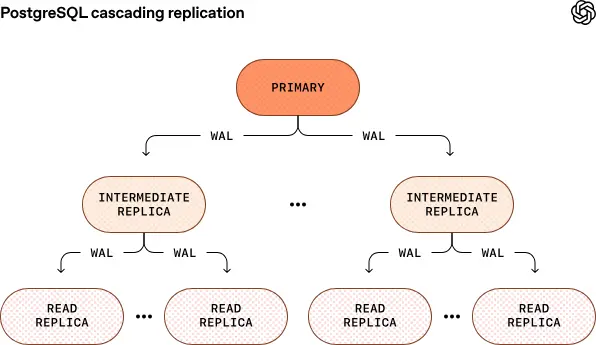
未來 OpenAI 也在探索更進一步的方案,例如 PostgreSQL 的分片或級聯複製等,以支撐更大規模的讀副本擴展需求。
