階躍星辰宣佈旗下語音模型 Step-Audio-R1.1 在大模型評測榜單 Artificial Analysis Speech Reasoning 中登頂全球榜首。
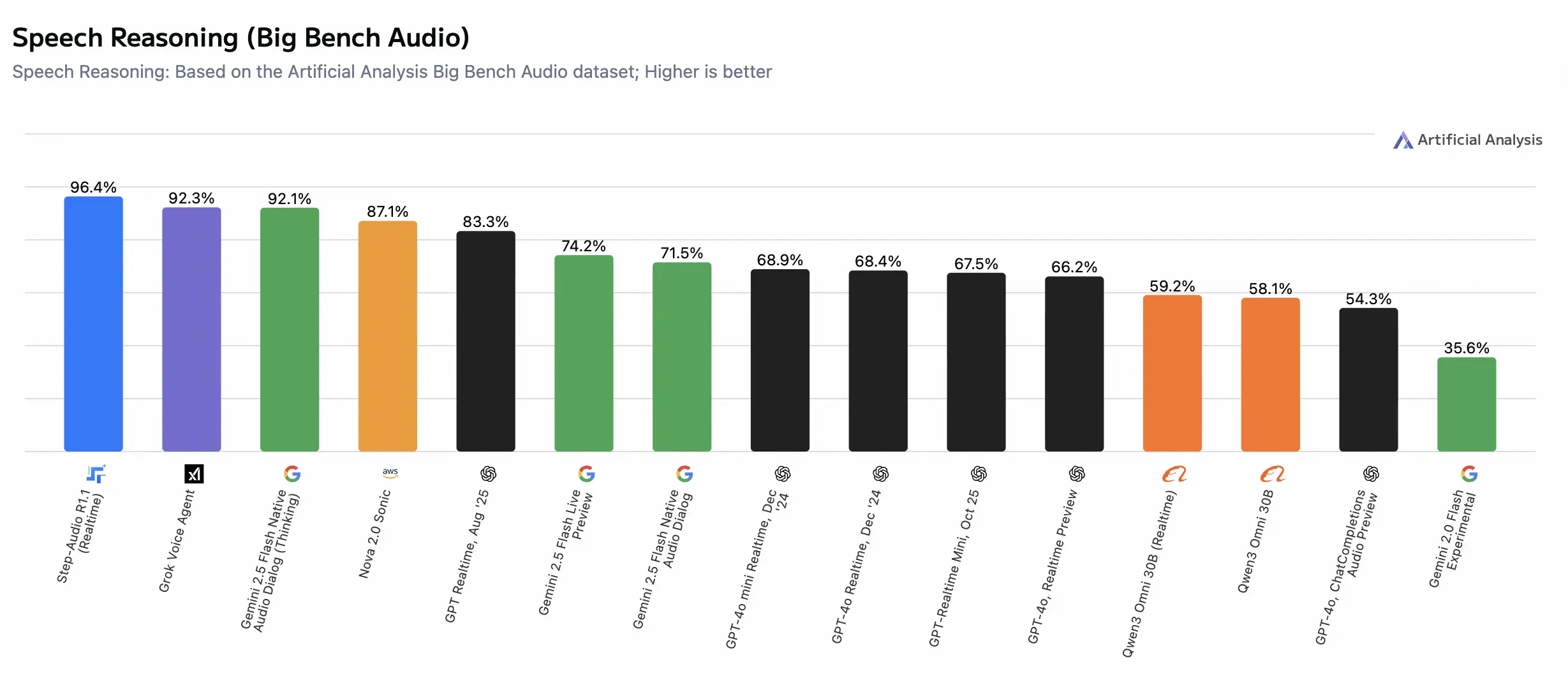
階躍星辰介紹稱,該榜單是目前業界評估“原生語音模型”(Native Audio Models)最權威的第三方基準之一。核心考量模型直接處理音頻並進行復雜邏輯推理的能力,主要考察維度包括準確率、首包延遲等。和大語言模型同理,語音模型同樣需要具備強大推理能力,才能提供更高階智能、更自然交互。
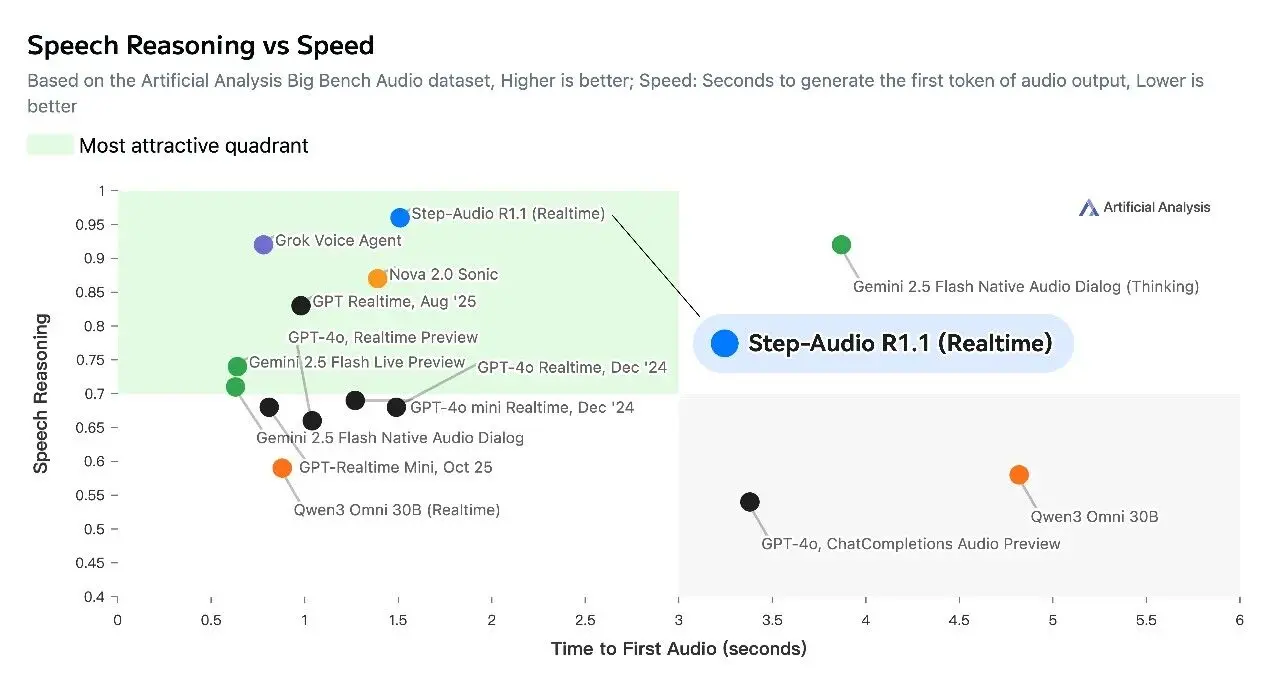
Step-Audio-R1.1 以 96.4% 準確率,超越 Grok、Gemini、GPT-Realtime 等主流一線模型,刷新歷史最好成績。在性能與速度的綜合權衡上,Step-Audio-R1.1 全面碾壓同類語音模型。
Step-Audio-R1 是由階躍星辰發佈的全球首個開源原生語音推理模型。它可以在不增加額外時延的情況下,端到端理解語音內容,“像人類一樣聽到對話即可思考”。
核心能力包括:
-
深度語音推理
-
實時響應能力
-
音頻領域的可擴展 CoT
Step-Audio-R1.1 是最新升級版本,兼顧更強實時對話和複雜語音推理能力。完整的實時語音 API 將在 2 月上線,目前開放的 chat 模式已搭載 R1.1 核心,支持邊想邊説的流式推理。
目前,Step-Audio-R1.1 權重已上傳至 HuggingFace:https://huggingface.co/stepfun-ai/Step-Audio-R1.1
體驗地址:https://www.stepfun.com/studio/audio?tab=conversation
GitHub 地址:https://github.com/stepfun-ai/Step-Audio-R1
魔搭 ModelScope:https://modelscope.cn/studios/stepfun-ai/Step-Audio-R1
