今年 8 月的 2025 年世界機器人大會上,宇樹科技 CEO 王興興表示,當下火熱的 VLA 模型(視覺-語言-動作)是相對比較傻瓜式的架構,並表示保持比較懷疑的態度。
針對王興興的質疑,理想自動駕駛負責人郎鹹朋昨日發文迴應。

郎鹹朋表示,8 月沒有及時提出自己觀點,是因為理想 VLA 司機大模型還沒正式發佈,空口無憑,並且其對具身機器人行業,還處於密切關注階段。
郎鹹朋指出,自己與王興興觀點最不一樣的地方在於,王興興認為模型架構更重要,但自己認為模型的關鍵是要與整個具身智能系統適配,在此基礎上,數據是起決定意義的。
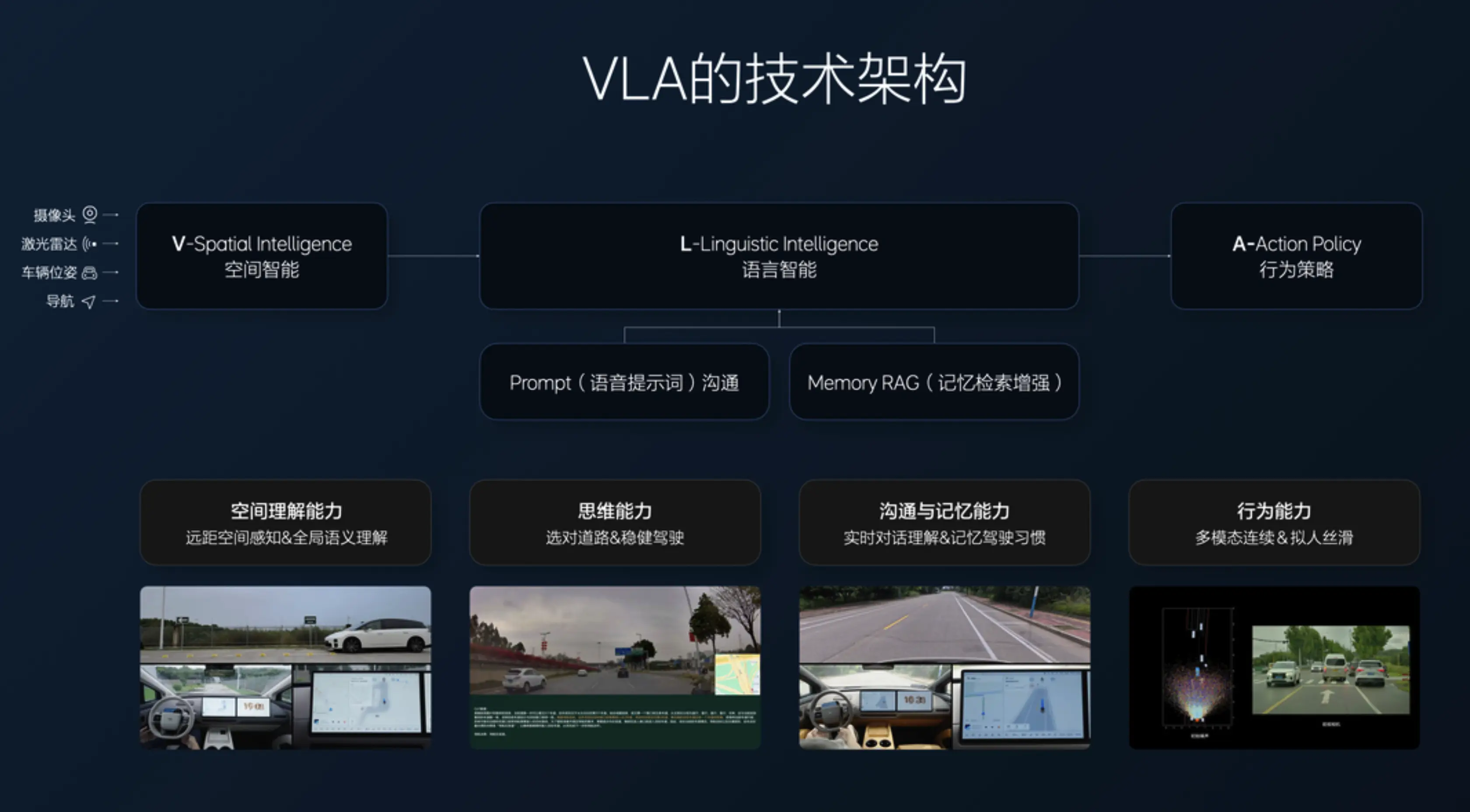
郎鹹朋通過 VLA 以及具身智能兩個方面進行解釋:
VLA:
- 在某些場景下理想的 VLA 已經具備了對物理世界的認知涌現,具體表現是用户會越來越多的發現之前端到端沒有的擬人行為。
- 世界模型更適合做「考場」而不是「考生」。世界模型的高算力需求(訓練和推理都是)決定了它更適合在雲端做數據生成和極度逼真的仿真測試和強化訓練。
- 在自動駕駛領域,脱離了海量真實數據談模型架構都是空中樓閣。理想之所以堅持 VLA,是因為擁有數百萬輛車構建的數據閉環,這讓理想能在當前算力下,把駕駛水平做到接近人類。
具身智能:
- 要想做好自動駕駛,必須先把自動駕駛當作完整的具身智能系統對待,每一部分在研發過程中要相互配合才能將價值發揮出來。需要做到全棧自研,不僅僅是軟件棧,而是整體軟硬全棧。
- 模型的關鍵是要與整個具身智能系統適配,在此基礎上,數據是起決定意義的。在機器人領域獲取數據相對困難,但在自動駕駛領域,特別是建立起數據閉環能力的車企來説並不是大問題。
郎鹹朋還提到,理想 CEO 李想近期提到,未來五到十年,具身機器人核心將有兩種形態:汽車類的具身機器人、人形類的具身機器人。而理想的 VLA 不僅服務於現在的理想各類汽車產品形態,也將服務於未來的汽車類具身機器人。
