編者按: LLM 的上下文窗口一直在不斷擴大,我們現在是否能"將一切內容塞進上下文",卻依然得到高質量的模型輸出?
我們今天為大家帶來的這篇文章,作者的核心觀點是:上下文不是免費的,信息必須被主動管理,否則"Garbage in, garbage out"的老問題將以更隱蔽的方式重現。
文章系統剖析了長上下文常見的四大失效模式------上下文污染、干擾、混淆與衝突,並提出了六種行之有效的上下文管理策略:RAG(檢索增強生成)、工具選配、上下文隔離、修剪、摘要與卸載。這些方法不僅有助於提升模型輸出質量,還能顯著降低能耗、加快響應速度,尤其在邊緣設備或複雜智能體系統中價值突出。作者還結合 Anthropic、DeepSeek、Gemini 的實踐經驗分享,展示瞭如何在真實場景中拆解任務、隔離線程、動態篩選工具,從而讓大模型"輕裝上陣、精準發力"。
作者 | Drew Breunig
編譯 | 嶽揚
01 緩解與避免上下文失效問題

早前發佈我們發佈過《How Long Contexts Fail》[1],本文我們再來系統探討能夠減輕或完全避免這些失效問題的解決方案。
但在開始之前,先簡要回顧一下長上下文可能失效的幾種方式:
- 上下文污染(Context Poisoning) :當幻覺信息或其他錯誤內容混入上下文並被持續引用時發生
- 上下文干擾(Context Distraction) :因上下文過長導致模型過度關注當前文本,而忽略了訓練階段習得的知識
- 上下文混淆(Context Confusion) :模型使用上下文中存在的冗餘信息生成低質量響應
- 上下文衝突(Context Clash) :當新增的上下文信息及工具與提示詞中既有內容產生矛盾時觸發
以上所有問題,歸根結底都是信息管理的問題。上下文中的每一條信息都會影響最終的回答。這又回到了那句古老的編程格言:"垃圾進,垃圾出(Garbage in, garbage out)。"[2]
幸運的是,針對上述問題,我們有大量可行的應對方案。
上下文管理策略
- RAG:選擇性地添加相關信息,助力大語言模型生成更優的回答
- 工具選配(Tool Loadout):僅選擇相關的工具定義加入上下文
- 上下文隔離(Context Quarantine):在各獨立線程中隔離不同上下文
- 上下文修剪(Context Pruning):從上下文中移除無關的或不必要的信息
- 上下文摘要(Context Summarization):將累積的上下文提煉為簡明的摘要信息
- 上下文卸載(Context Offloading):將信息存儲在大語言模型上下文之外,通常通過一個負責存儲和管理數據的工具實現
02 RAG

檢索增強生成(Retrieval-Augmented Generation,RAG)是指選擇性地添加相關信息,來助力大語言模型生成更優的回答。
關於 RAG 的討論早已汗牛充棟,今天我們不會深入展開,只想強調一點:它依然非常有效。
每當模型將上下文窗口的上限再度拉高,就會有人掀起新一輪"RAG 已死"的論戰。上次引發大規模討論是 Llama 4 Scout 發佈,帶來了 1000 萬 token 的上下文窗口。面對如此龐大的容量,人們很容易產生"乾脆把所有內容都塞進去,這多省事"的想法。
但正如我們之前的文章[1]所講:如果你把上下文當成一個雜物抽屜,那這些雜物就會直接影響你的輸出結果。若您想深入瞭解,這裏有一門新課程[3]值得推薦。
03 工具選配(Tool Loadout)

工具選配是指僅選擇與當前任務相關的工具定義加入上下文。
"選配"(loadout)原為遊戲術語,指在關卡/對戰/回合開始前對技能、武器與裝備進行的特定組合配置。通常需要根據角色特性、關卡難度、團隊構成及個人操作習慣進行針對性調整。
在此我們借用該術語,來描述為特定任務篩選最適用工具的過程。
最簡單的工具篩選方式莫過於對工具描述實施 RAG 檢索。這正是 Tiantian Gan 與 Qiyao Sun 在論文《RAG MCP》[4]中採用的方法 ------ 通過將工具描述存儲於向量數據庫,實現根據輸入提示詞精準匹配最相關工具。
DeepSeek-v3 團隊發現,當工具數量超過 30 個時,精準選配就變得至關重要。超過這個閾值,工具描述會出現重疊混淆;超過 100 個時,模型在測試中幾乎必然失敗。 而採用 RAG 技術將工具篩選至 30 個以內,不僅能大幅縮短提示詞長度,更能將工具選擇準確率提升高達 3 倍。
對於小型模型而言,問題在工具數遠未達 30 時便會顯現。我們在上一篇文章中提到的論文《Less is More》[5]就指出:Llama 3.1 8B 在提供 46 個工具時無法通過基準測試,但當工具數量減少到 19 個時卻能成功。問題根源在於上下文混淆,而非上下文窗口的容量限制。
為解決這一問題,《Less is More》團隊開發了一種動態工具選擇機制:利用一個由大語言模型驅動的工具推薦器。該模型會先推理"它認為回答用户查詢所需工具的數量和類型",然後通過語義搜索(即再次使用工具 RAG)確定最終的工具配置。他們在 Berkeley Function Calling Leaderboard[6] 上測試了該方法,發現 Llama 3.1 8B 的性能提升了 44%。
該研究還指出精簡上下文的兩大額外優勢:更低的功耗和更快的響應速度 ------ 這在邊緣計算場景(即在手機或 PC 端而非專業服務器上運行大模型)中尤為關鍵。即使動態選配未能提升模型效果,其帶來的能效與響應速度收益也值得投入:分別實現了 18% 的能耗節省和 77% 的速度提升。
幸運的是,大多數智能體(agent)的應用場景較為聚焦,通常只需少量人工精心挑選的工具。但若需擴展功能範圍或集成規模,請務必重視工具選配策略。
04 上下文隔離(Context Quarantine)

上下文隔離是指將上下文分別置於各自獨立的線程中,每個線程由一個或多個大語言模型單獨使用。
當上下文長度適中且不含無關內容時,我們通常能獲得更好的結果。實現這一點的方法之一,是將任務拆解為多個更小、彼此隔離的子任務 ------ 每個子任務擁有自己專屬的上下文。
這種策略有許多應用實例[7-8],其中一篇通俗易懂的説明來自 Anthropic 的博客文章[9],詳細介紹了他們的多智能體研究系統。文中寫道:
搜索的本質是壓縮:從海量語料中提煉關鍵洞見。子智能體通過並行運作,各自使用獨立的上下文窗口同時探索問題的不同維度,最終將最重要的信息壓縮後傳遞給主研究智能體。每個子智能體還實現了關注點分離 ------ 各自配備不同的工具、提示詞和探索路徑 ------ 從而減少路徑依賴,支持更徹底、更獨立的研究。
這類設計模式特別適用於研究類任務。面對一個複雜問題時,可以將其拆解為若干子問題或探索方向,並分別交由多個智能體處理。這不僅能加速信息的收集與提煉(前提是具備足夠的計算資源),還能避免單個上下文積累過多或不相關的信息,從而提升輸出質量:
我們的內部評估表明,多智能體研究系統在"廣度優先型"查詢中表現尤為突出 ------ 這類查詢需要同時推進多個獨立的研究方向。我們發現,以 Claude Opus 4 為主智能體、Claude Sonnet 4 為子智能體的多智能體系統,在內部研究評估中比單智能體的 Claude Opus 4 性能提升 90.2%。例如,在要求列出標普 500 信息技術板塊所有公司的董事會成員時,多智能體系統通過任務分解交由子智能體並行處理,成功找到正確答案;而單智能體系統則因緩慢、串行的搜索未能完成任務。
這種方法也有助於優化工具選配(tool loadout):智能體設計者可以創建多種智能體原型,每種都配備專屬的工具組合及使用説明。
對智能體開發者而言,關鍵挑戰在於識別出哪些任務可以拆解並分配到獨立線程中執行。 那些需要多個智能體頻繁共享上下文的問題,並不太適合採用此策略。
若您的智能體應用場景適合並行處理,強烈推薦閲讀 Anthropic 的完整文章[9],其內容極為精彩。
05 上下文修剪(Context Pruning)
上下文修剪是指從上下文中移除無關的或冗餘的信息。
智能體在調用工具和整合文檔的過程中會不斷積累上下文。有時,需要暫停操作,評估已收集的內容並清除冗餘信息。你可以將這項任務交給主大語言模型處理,也可以專門設計一個由大語言模型驅動的工具來審查並編輯上下文,或選擇更專業的修剪方案。
上下文修剪在自然語言處理(NLP)領域其實已有(相對)較長的歷史 ------ 在 ChatGPT 出現之前,上下文長度曾是一個更為棘手的瓶頸。在此基礎上,當前一種實用的修剪方法是 Provence[10],這是一個"面向問答場景的高效穩健上下文修剪器"。
Provence 速度快、準確率高、使用簡單,且體積相對小巧 ------ 僅 1.75 GB。你只需幾行代碼即可調用它,例如:
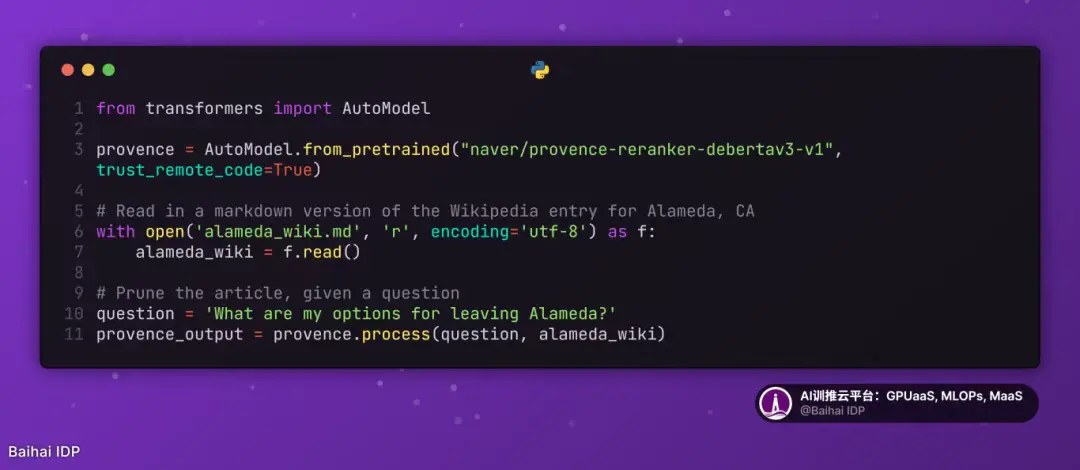
Provence 對文章進行精簡處理,刪減 95% 的內容後僅保留相關核心段落[11],效果令人驚歎。
你可以使用 Provence 或類似功能來裁剪單個文檔,甚至整個上下文。此外,這種做法也有力地支持了以下設計模式:將上下文以結構化的形式(例如字典或其他數據結構)進行維護,並在每次調用大語言模型前動態拼接成最終的字符串。這種結構在進行修剪時尤為有用,既能確保核心指令與目標完整保留,又允許對文檔或歷史記錄段進行刪減或摘要處理。
06 上下文摘要(Context Summarization)

上下文摘要是將累積的上下文提煉為簡潔摘要的過程。
上下文摘要最初是為應對有限上下文窗口而引入的一種手段。當聊天會話即將超出最大上下文長度時,系統會生成一份摘要,並開啓一個新線程。用户在 ChatGPT 或 Claude 等聊天機器人中可以手動執行這一操作:要求模型生成簡短摘要,然後將該摘要粘貼到新會話中。
然而,隨着上下文窗口不斷擴展,智能體開發者發現,摘要的價值已不僅限於避免超出上下文容量限制。隨着上下文的增長,模型容易分心,更少依賴其在訓練中學到的知識 ------ 我們稱之為"上下文分心"(Context Distraction)。 開發《寶可夢》遊戲智能體的 Gemini 團隊發現,一旦上下文超過 10 萬個 token,就會觸發這一現象:
儘管 Gemini 2.5 Pro 支持超百萬 token 的上下文,但在智能體場景中有效利用如此長的上下文仍是一個新興研究領域。在該智能體場景中,當上下文大幅超過 10 萬 token 時,智能體傾向於重複其操作歷史中的已有動作,不再靈活思考、主動規劃。儘管這一現象尚屬個案,但卻揭示了這樣一個現象:用於檢索任務的長上下文,與用於多步生成式推理的長上下文,有着根本不同的要求和挑戰。
對上下文進行摘要操作本身並不難,但為特定智能體實現精準摘要卻充滿挑戰性。開發者必須明確哪些信息需要保留,並將這一要求清晰傳達給執行壓縮的大語言模型。 因此,值得將此功能單獨拆解為一個由大語言模型驅動的處理階段或獨立應用 ------ 這樣便於收集評估數據,從而直接指導並優化該任務的執行效果。
07 上下文卸載(Context Offloading)

上下文卸載是指將信息存儲在大語言模型上下文之外的技術,通常通過專門的數據存儲管理工具實現。
這可能是我最鍾愛的策略 ------ 簡單到令人懷疑它是否真的有效。
Anthropic 曾專門撰文介紹這一技巧[12],文中詳細説明了他們的 "think" 工具,本質上就是一塊草稿板:
藉助"think"工具,我們讓 Claude 在給出最終答案前,額外增加一個思考步驟,併為其劃出獨立空間......在需要連續調用工具或與用户進行長對話時,這一點尤為實用。
我很欣賞 Anthropic 發佈的研究成果,但對此工具的命名持保留意見。倘若它叫"scratchpad(草稿板)",功能一目瞭然:給模型一個記筆記的地方,既不污染上下文,又可供後續查閲。而"think"一詞容易與"extended thinking"[13]混淆,還無端把模型擬人化......扯遠了。
有一塊能記錄進度與筆記要點的地方,確實行之有效。Anthropic 研究表明,將 "think" 工具與領域專屬提示詞(這本就是智能體的標準配置)結合使用,能在專業智能體基準測試中實現高達 54% 的性能提升。
Anthropic 總結了上下文卸載模式適用的三大場景:
- 當 Claude 需要仔細分析前期工具的執行結果,並可能因此調整後續行動路徑時。
- 在需要嚴格遵守複雜規則體系,並確保每一步操作都符合規定的情境下。
- 在環環相扣的任務中,每一個後續步驟都依賴於前一步的正確結果,且任何失誤都會導致付出高昂代價。
上下文管理往往是打造智能體時最棘手的環節。正如 Karpathy 所説,設計者得"恰到好處地填充上下文窗口[14]",巧妙地調度多種工具與各種信息,還要定期做上下文清理。
貫穿所有上述策略的關鍵洞察在於:context is not free,不能隨意、無節制地向上下文裏填充信息。上下文中的每一個 token,無論相關與否、正確與否,都在左右模型的行為。 現代大語言模型提供的超大上下文窗口固然是一種強大的能力,但這絕不能成為我們疏於信息管理的藉口。
下次構建或優化智能體時,不妨問問自己:當前上下文裏的每一條信息,真的都在"幹活"嗎? 如果有些內容只是佔位置、沒貢獻,那你就該用前面提到的六種方法,把它們清理掉或挪出去。
END
本期互動內容 🍻
❓在你的項目裏,是否曾因上下文管理不當(如信息污染、工具混淆)而踩過"坑"?您最終是如何發現並解決這個問題的?
文中鏈接
[1]https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
[2]https://en.wikipedia.org/wiki/Garbage_in,_garbage_out
[3]https://maven.com/p/569540/i-don-t-use-rag-i-just-retrieve-documents
[4]https://arxiv.org/abs/2505.03275
[5]https://arxiv.org/abs/2411.15399
[6]https://gorilla.cs.berkeley.edu/leaderboard.html
[7]https://arxiv.org/abs/2402.14207
[8]https://www.microsoft.com/en-us/research/articles/magentic-one-a-generalist-multi-agent-system-for-solving-complex-tasks/
[9]https://www.anthropic.com/engineering/built-multi-agent-research-system
[10]https://arxiv.org/abs/2501.16214
[11]https://gist.github.com/dbreunig/b3bdd9eb34bc264574954b2b954ebe83
[12]https://www.anthropic.com/engineering/claude-think-tool
[13]https://www.anthropic.com/news/visible-extended-thinking
[14]https://x.com/karpathy/status/1937902205765607626
原文鏈接:
https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html
