本文整理自 2024 Apache Pulsar 歐洲峯會,由來自 Flipkart 的工程師安尼爾·戈達帶來的《Flipkart 異步總線實現不停機從 Kafka 遷移到 Pulsar》的演講視頻。
背景介紹
Flipkart 是印度領先的電子商務平台之一。我們基於 Kafka 打造的異步總線承接了公司海量的 HTTP 調用和消息傳輸。但隨着業務的發展,Kafka 已經不能跟上公司快速變化的業務發展要求。隨着調研和測試,我們最終決定使用 Pulsar 替換 Kafka。
我們選擇Pulsar 的主要原因,包括:
- Pulsar 原生支持多租户模型:這使得它能夠在同一實例中為多個租户服務,而每個租户可以獨立管理自己的命名空間和權限。這對於需要隔離不同客户數據的大型系統來説非常重要。
- Pulsar 原生支持的 Geo 跨域傳輸能力:這使得我們可以直接使用 Geo 打造自己的跨域、多機房業務。
- Pulsar 提供存儲和計算的分離架構:這意味着系統可以分別擴展存儲和計算資源,根據需要優化性能和成本。
從 Kafka 遷移到 Pulsar 給我們帶來了諸多優勢。Pulsar 內置的企業級功能,減少了我們自行開發和維護的成本,也降低了系統的總體複雜性。在 Kafka 中,這些高級功能都需要額外構建和維護。
本文中,我們將分三個部分詳細討論 Flipkart 的異步總線如何實現從 Kafka 到 Pulsar 的實時遷移:
- 第一部分是介紹 Flipkart 異步總線的價值所在;
- 第二部分將討論我們在從 Kafka 遷移到 Pulsar 時面臨的挑戰;
- 第三部分是我們提出的解決方案,即為我們如何為用户實現實時遷移。
Flipkart 異步總線
同步 vs異步
在深入探討之前,我們需要回顧一下同步和異步的區別,以及我們為什麼選擇異步操作。
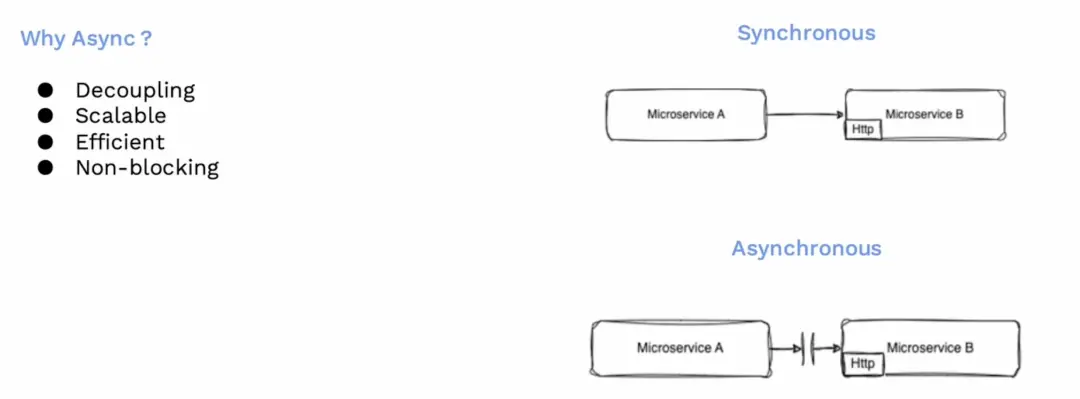
在同步操作中,服務 A 通過 HTTP 連接到服務 B,並等待其響應,直到服務 B 完成請求的處理。然而,這種方式並不可擴展,因為存在阻塞,並且與服務 B 緊耦合。這就是為什麼我們使用異步處理:在異步處理中,服務 A 將請求發往服務隊列,然後繼續執行自己的任務,不會等待服務 B 的響應。服務 B 可以自行決定處理時間,甚至可以延遲處理。這意味着兩個服務在職責上是解耦的,它們可以獨立地擴展,並且效率高,不會發生鎖定。
消息代理
我們通常使用可持久的消息隊列(消息代理Broker)來實現這一點。消息代理位於服務 A 和服務 B 之間。服務 A 向消息代理生產消息,而服務 B 則從消息代理中消費消息。當有多個消費者或多個服務對同一消息感興趣時,它們就也會消費相同的主題。
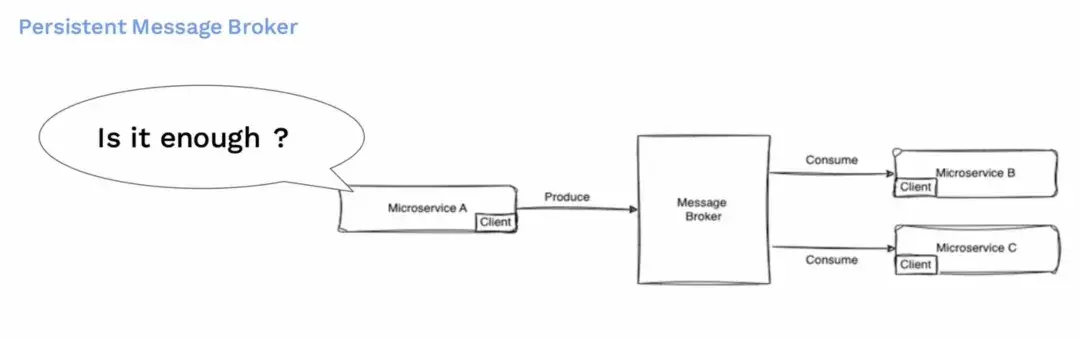
但問題是,這樣就足夠了嗎?
多樣化的需求
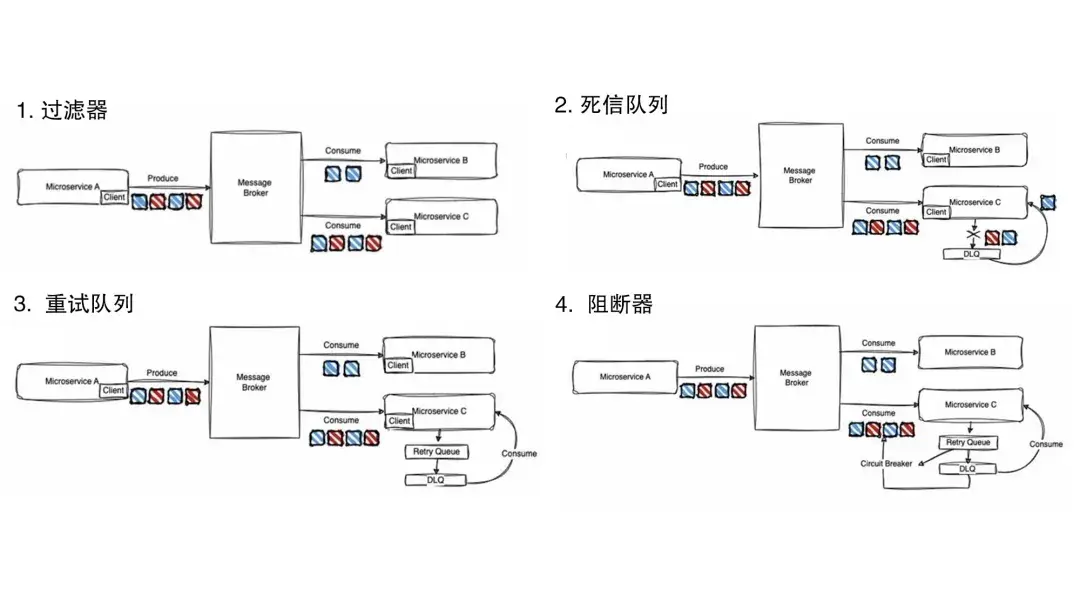
現在的微服務都會圍繞消息代理構建多種多樣的服務,以滿足其端到端的需求。而簡單的消息隊列,無法滿足這類多樣化的需求。複雜點的業務都需要考慮失敗管理。
- 過濾器需求:我們常見的過濾器,要求相當簡單。只是有些服務,需要全量消費,而有些服務又只需要部分消息,這些都是由業務特點決定的。他們同時存在,需要對應滿足。
- 死信隊列:對於處理失敗的消息,有可能需要存儲很長時間並稍後消費。你的消費模式,可能是選擇性消費,例如需要跳過某些消息甚至跳過所有消息。也可能想要消費所有消息。這完全取決於用例。但你都可能根據需要會需要從死信隊列中消費。
- 重試消息:在消息轉移到死信隊列存儲之前,如果你的消息因某些異常而失敗,而且該異常可以恢復,你會希望重試這些消息,而不是直接將其標記為失敗消息並移至死信隊列。
- 消息斷路器:對於可能存在的大面積處理失敗,你應該還需要準備斷路器。如果你的服務依賴於另一個服務,這些服務一旦出現不可用,例如數據存儲出現問題,那麼你就會知道,大多數消息都會將處理失敗。這時候你不會想要繼續從消息代理那裏拉取更多消息,而是根據失敗率控制你從消息代理拉取的消息數量。如果失敗率高,你會想減少拉取;如果失敗率低,你會想全速運行。
按組排序
組內有序(Group Ordering),這是用户會在消息隊列服務中尋找的一個重要特性。在許多消息隊列系統中,為了保證同一個組的消息被順序處理,系統會確保同一組的所有消息都進入到同一個分區。只不過,這時候在同個分區內,也可能有來自不同組的消息。在這種情況下,需要有一種機制來跟蹤每個組內的消息處理狀態,並確保按順序處理消息。例如,如果一個組的第一條消息在時間點T0被成功消費,然後同一組的第二條消息在時間點T1失敗了,那麼在時間點T3來自同一組的第三條消息就不應該被處理,直到問題得到解決。因此你需要維護一個狀態管理系統,來記錄每個消息的處理結果,並基於這些信息來決定是否處理後續的消息。

同樣,在一個訂單系統中,會有多個服務在彼此協同。比如當用户下單時,首先需要確認支付成功,然後再更新庫存,最後再由倉庫發貨。這三個服務雖然是獨立的,但實際是相互依賴的:沒有完成支付,你就不要更新你的庫存;如果庫存沒有更新,你就不要發貨。前一步驟失敗了,下一步驟就要中止。這就是用户通常尋求的組內順序性。同樣,這表明需要維護組內消息的狀態,需要根據前一個狀態,來決定如何處理後一條消息。
額外的複雜性
此外,有相當一部分用户,他們想讓微服務A 對微服務 B 進行一個簡單的 HTTP 調用,並希望這個過程是異步的,不需要等待響應的。

通常,我們實際上仍然會引入消息代理來提供異步通信和服務解耦。
不過這會導致客户端過於複雜,同時引入新的問題:
- 用户需要依賴一個消息客户端。
- 維護客户端會帶來額外開銷,包括集成、維護升級成本
- 用户需要更多消息隊列本身相關專業知識等。
Varadhi:Flipkart 異步總線
Flipkart需要的消息代理
因此,基於以上需求,Flipkart 需要的消息代理至少要滿足以下特點:
- 支持組內有序
- 支持過濾
- 支持重試隊列
- 支持死信隊列
- 可選擇性消費
- 支持斷路器模式
為了解決以上問題,我們推出了 Varadhi,這是 Flipkart 自研的異步總線。
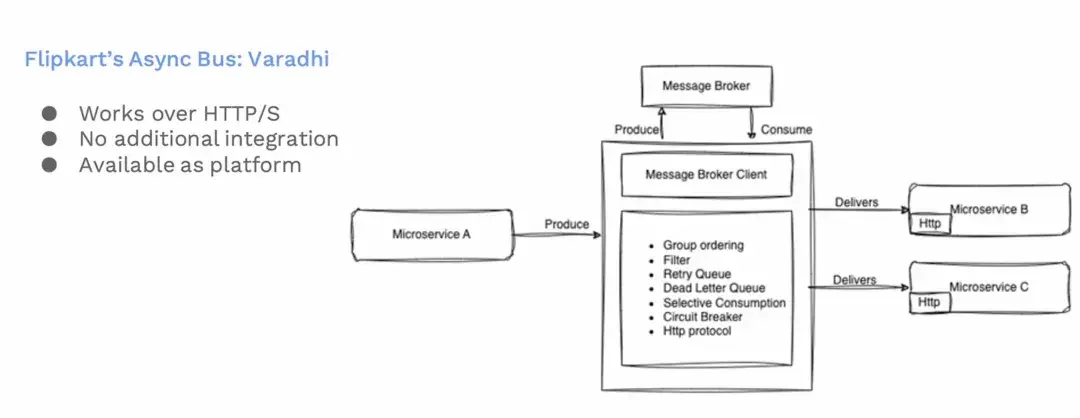
Varadhi 實現了我們上述需要的所有功能要求。Varadhi隱藏了內部的消息隊列的實現細節,對外給用户提供完整的平台服務。
目前 HTTP 或者 HTTPS 都是支持的。用户集成也沒有任何額外的負擔。
Varadhi平台規模
目前Pulsar Varadhi平台支持了:
- 180+ Tenants
- 3500+ Topics
- 9500+ Subscriptions
- ~0.5 Million provisioned QPS
- ~1 Billion messages produced
在 Varadhi平台,目前已經有180多個租户加入,3500多個Topic和9500多個訂閲。每天最多約能產生10億條消息,而且這些消息能在同一天被消費完。
Varadhi組件介紹
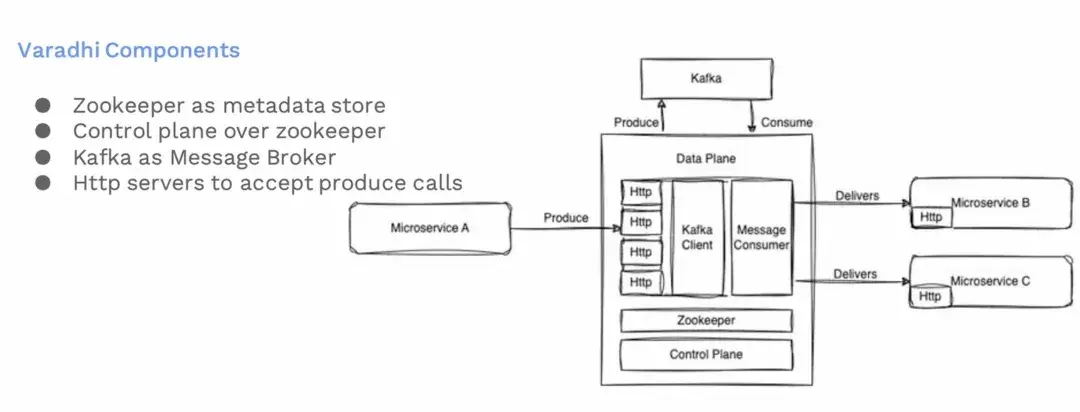
這是Varadhi的組件架構圖。其中ZooKeeper 維護元數據。我們有一個控制平面,允許用户配置他們的訂閲主題和端點,以及設置他們要從哪裏接收消息。我們還有個HTTP服務器,這些服務器處理來自用户的生產請求。這些生產請求隨後被持久化在消息代理中。
以下是每個組件的詳細説明:
- ZooKeeper:用於維護服務元數據(metadata)的組件。
- Control Plane:控制平面允許用户配置他們的訂閲主題和終端點(endpoints)。這是一個用户交互界面,用户可以在這裏設置他們要從哪裏接收消息。
- HTTP Servers:這些服務器處理來自用户服務的生產請求(produce requests)。這些請求是關於消息的生成和發送。
- Message Broker (Kafka):消息代理組件,之前使用的是Kafka,現在已經被 Pulsar 所取代。它負責存儲和管理傳入的消息。生產請求在這裏被持久化。
- Message Consumer Services:這些服務從Kafka消費消息,然後將消息傳遞到用户配置的微服務終端點。
這樣的架構設計分離了消息的生產、管理和消費過程,增強了系統的擴展性和可維護性,允許我們靈活地處理大量的消息生產和消費請求。同時,通過ZooKeeper確保系統的配置和同步,控制平面也可以為用户提供易於管理和配置的界面。
我們之前還是使用 Kafka 作為消息代理。而現在,裏面的 Kafka 系統已經被 Pulsar 取代了。因為我們想利用 Pulsar 原生自帶的多租户模型、GEO特性還有存儲和計算分離架構。使用這些功能使得我們的平台管理變得更加簡單和有效。而在 Kafka 中,需要額外構建這些功能,增加了開發和維護的複雜性。
遷移挑戰
遷移要求
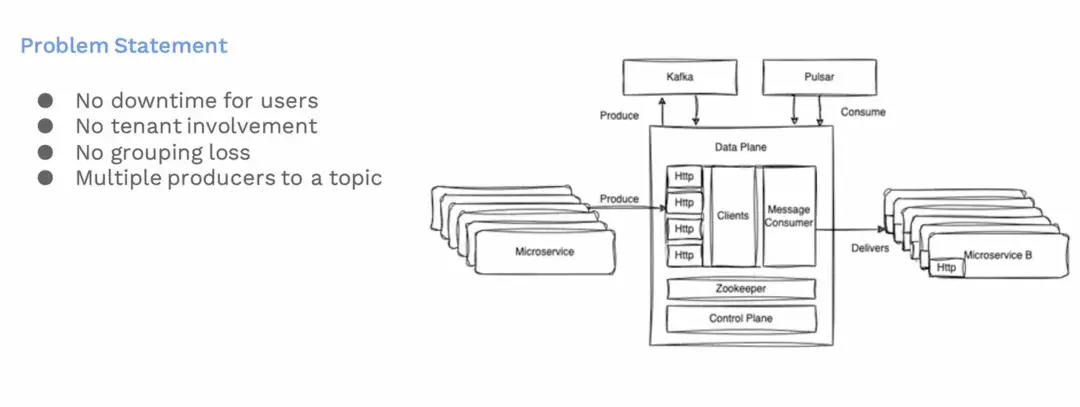
從 Kafka 遷移到 Pulsar 還是會面臨很多挑戰,我們有以下具體的遷移要求:
- 確保不停機:遷移過程中不能影響現有用户的服務可用性。
- 用户無感知:不希望讓用户參與到遷移過程中,以減少複雜性和避免長時間的遷移。
- 維持順序性:確保在Kafka和Pulsar之間遷移消息時,消息的順序能維持一致,這對於確保業務流程的連貫性至關重要。
- 支持多生產者模式: 我們需要支持多個生產者向同一主題發送消息的情況,這在我們多服務環境中很常見。
這些要求,體現了遷移的複雜性。對我們保持高可用和數據一致性方面提出了很大的挑戰。
Varadhi topic元數據
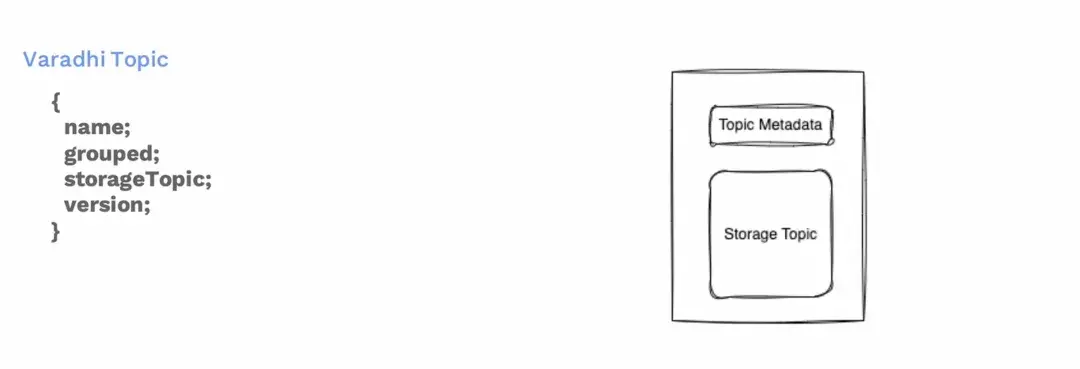
在介紹遷移方案之前,需要先説明下我們自定義了一個 Varadhi 版本的Topic。裏面包含 Topic名稱,是否分組還是有 Topic 的存儲位置,是基於Kafka的或是基於Pulsar的存儲。最後還有個 Topic 的配置版本。每次更新Topic時,版本號會遞增。
方案 1:整體替換
整體替換存儲 topic
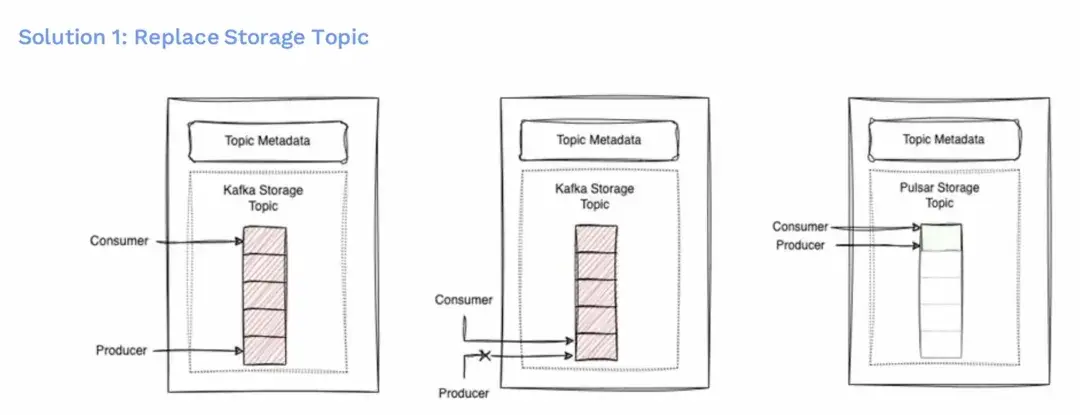
第一個方案是更換存儲 Topic,這是最簡單的方案。但是要從 Kafka 替換為 Pulsar 的存儲主題,我們得先暫停生產,等待消費者追上來。一旦完成同步,也就是説 Kafka 存儲主題中的所有消息都被消費了,然後我們就可以用 Pulsar 替換它了。同時生產者和消費者的指針都是切換到 Pulsar。這樣就可以從 Pulsar 主題上進行消費和生產了。
優劣勢分析

這個方案的優點是生產者和消費者可以同時進行,這意味着用户的順序性得到保留。任何生產出的消息將會以產生的順序被消費,因為遷移沒有帶來這方面的改變。而且方案很容易實現。然而,也有一些不利因素,由於這些原因,我們無法繼續採用這種方法。其中之一是,我們可能會有多個消費者對應一個生產者,一旦其中有消費出現延遲的,就會使我們的生產停機時間變得很長,這是我們不希望讓用户經歷的。另外,偏移重置不可用,你不能將你的消費指針回退到 Kafka,即使用户已經為該主題設置了某種保留策略。那時候,我們將不得不丟失那些信息,這對我們來説可能是不可接受的。
方案 2:分組替換
分組替換存儲 topic
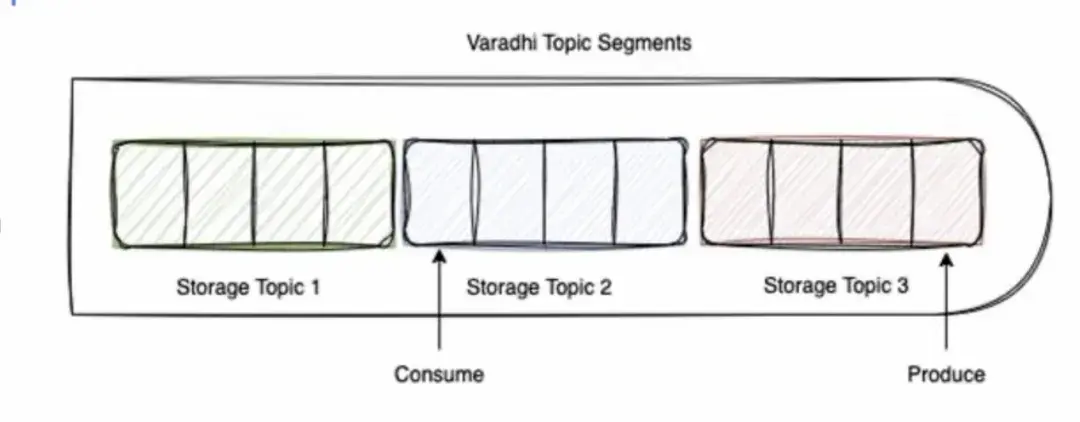
為了克服這個問題,我們決定採用一個分段的Varadhi主題方案。
- 現在一個Varadhi主題可以接入多種存儲主題,並且有一個指針指示我們應該生產到哪個主題。
- 單一主題被劃分為多個段,每個段被認為是一個新的存儲主題。當我們決定創建一個新的存儲主題時,前一個段結束,新的段開始。
- 生產和消費可以在不同的段同時進行。
這會出現一個現象:消費的指針總是落後於生產的指針。儘管消費者的指針可能位於不同的存儲主題中,但仍然落後於生產者所在的存儲主題。
替換示例
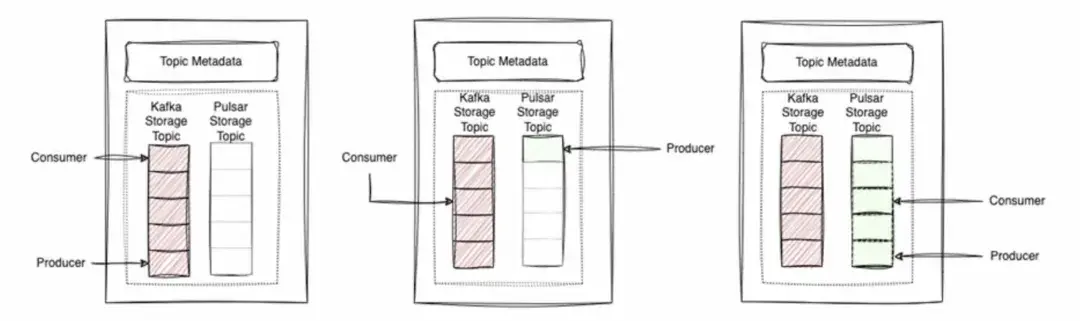
在這個例子中,我們可以看到存儲主題1存在了一段時間,然後我們增加了存儲主題2,消費仍然發生在存儲主題2中。我們將繼續生產並移動到存儲主題3進行生產。
所以,從一個主題到另一個主題的遷移過程會是這樣的:我們設立了一個目標主題,在某一特定時間點,我們嘗試更改開關,請求進行遷移,並會告訴生產者現在可以切換到目標主題進行生產。此時,生產者繼續前進,開始向目標主題生產,一旦消費者完成從前一個主題的消費,最終也會轉移到目標主題上來。
優劣勢分析

這個方案有一些優勢。
- 首先這裏的生產和消費是異步切換的
- 用户沒有停機時間
- 我們仍然可以支持偏移重置,支持用户將他的消費指針移動到特定點,並從 Kafka 開始再次消費。一旦消費滯後為零,消費者將再次轉移到目標主題。
然而,這裏也有一個挑戰,因為生產者和消費者是異步切換的,生產者之間沒有協調。記得我們有多個 HTTP 端口吧。這些異步切換,這會帶來一個風險,可能會導致我們組內的順序性出現問題。
協調生產者切換
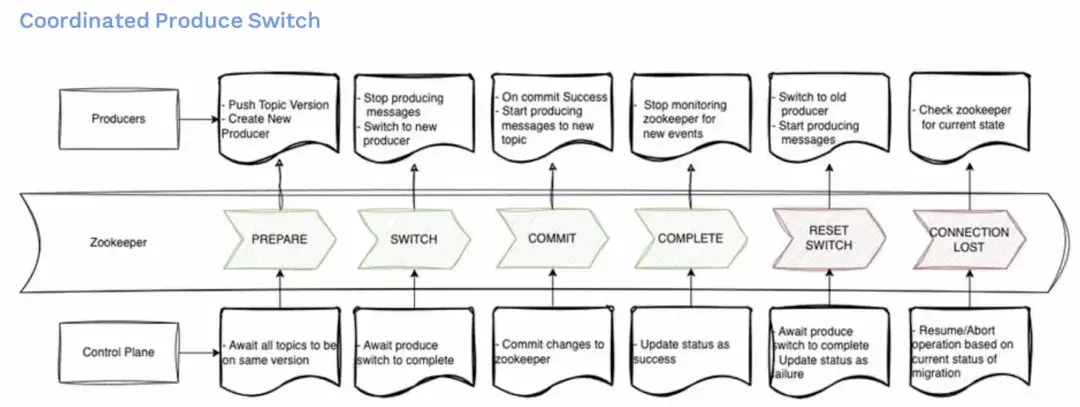
為了克服這一點,我們決定採用一個基於協調的生產切換方案。這裏面有兩部分非常重要。第一個是控制平面,負責協調整個切換過程。第二個是ZooKeeper ,用來維護遷移過程中的程序狀態。生產服務會監聽這些狀態,並根據獲取到的狀態做出對應的反應。
- 第一階段是準備階段,我們要求所有的生產者更新他們的主題版本,並創建新的生產者實例。這一階段不涉及停機。生產者在後台進行初始化和連接驗證。這時候生產仍在 Kafka 主題上進行。準備可能需要一定時間,因為需要讓控制平面等待所有生產者都準備完成。這包括使用最新版本並準備好連接實例對象。
- 然後我們進入切換階段。生產者將停止向舊主題發送消息,並準備切換到新主題。在得到控制面通知他們具體的切換指令之前,他們還不會向新主題發送消息。在此階段,實際的消息生產會暫停,導致短暫的系統停機。這個停機時間通常是非常短的,並且是可控的。
- 之後進入提交階段。控制面將指針從Kafka主題更改為到 Pulsar 主題,並在Zookeeper中更新狀態。生產者在確認更新成功後,將開始向新的主題發送消息。
- 接下來將來到完成階段。控制平面將狀態更新為成功,生產者將停止監控Zookeeper。
然而,如果在任何階段出現問題,如生產者無法停止發送消息或控制平面無法成功更新Zookeeper,或丟失連接等,系統將回滾到之前的狀態。在這些情況下,我們要做的是回滾到 Kafka 主題,限制生產的數量,並且停止遷移,並且將狀態更新為失敗。控制平面和生產者將根據當前遷移狀態決定是恢復還是中止操作。
生產者切換的細節
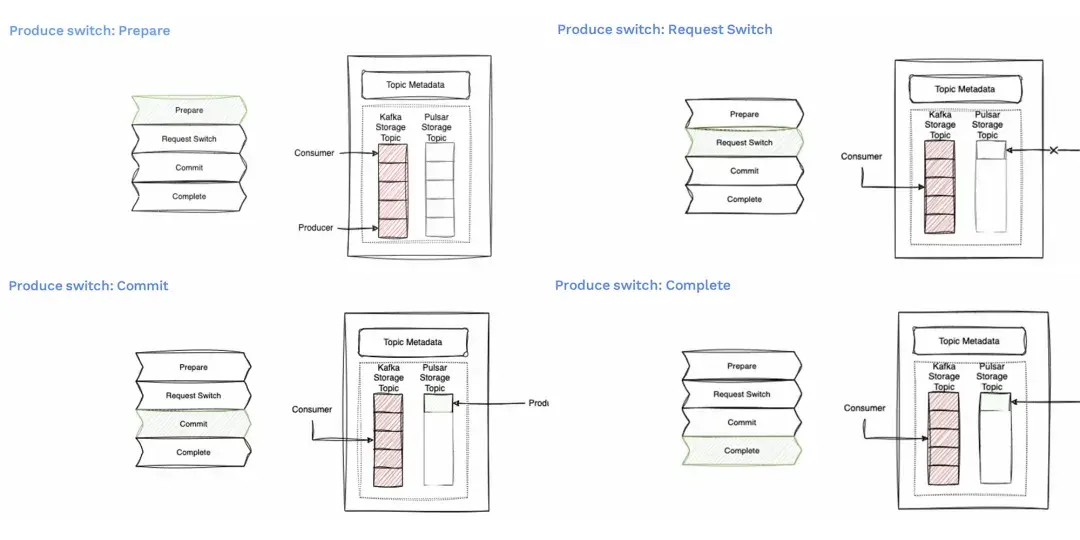
- 在準備階段我們的生產者仍然指向Kafka。
- 在請求切換的狀態時我們的生產者指針已經移動到Pulsar的主題,但生產還沒有開始,它在等待提交。
- 一旦提交成功,生產指針將會在 Pulsar 主題上開始向前移動並開始在生產。
- 整個操作將被標記為成功完成。
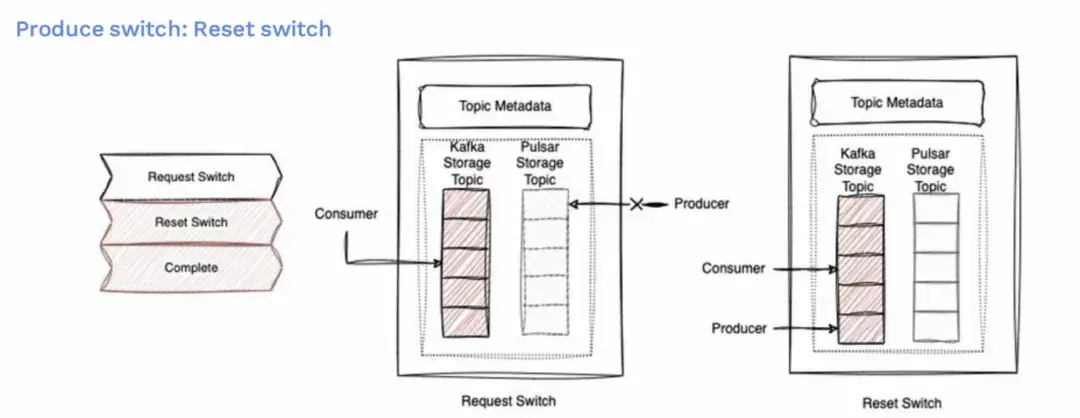
如果出現失敗,例如在請求步驟中,生產者指向了 Pulsar 上,但無法生產消息。這時候將重置切換,生產指針將回到 Kafka 主題,並開始只向 Kafka 發送消息。整個操作將被標記為完成,但狀態為失敗。
協調消費者切換

消費的切換是相當直接的。消費者由控制平面指定從哪裏消費消息。從指定的消費 ID 開始消費,或者消費主題裏面滯後的消息。一旦完成,控制平面將更新消費者主題 ID 並移至下一段,這個時候,消費者就可以發送切換了。
回滾策略
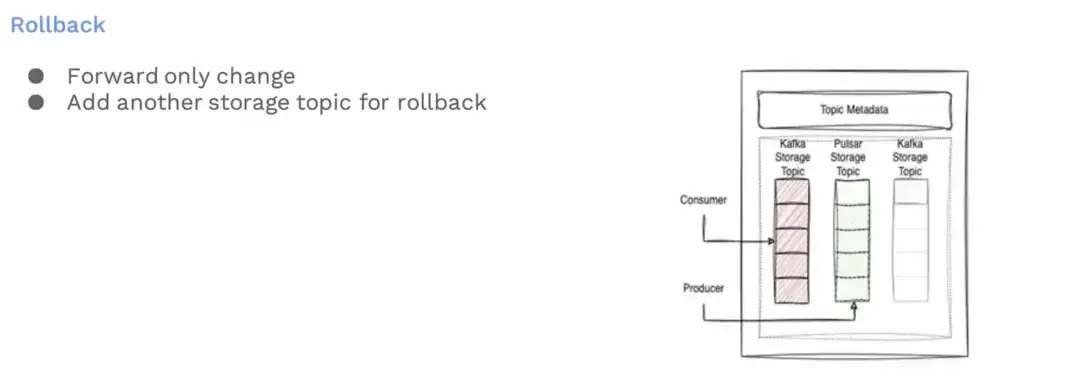
就故障回滾方面我們採取的策略,假設從 Pulsar 發現問題想要回滾到 Kafka,我們的策略規定不能回到之前的主題,而是必須添加一個新的 Kafka 存儲段,並且移動生產指針,或者從 Pulsar 重新遷移一次到 Kafka。這是必要的,我們不能重複使用同一主題。我們本可以將指針從 Pulsar 移回例子中的Kafka 主題一,但這意味着 Pulsar 主題中的消息將被錯誤錯亂,從而導致我們的用户遭受順序性方面的損失。
因此,即使是回滾也意味着另一次變相的遷移。
額外收益

我們通過這種遷移策略獲得了一些額外的好處。例如,我們現在可以更改主題的命名空間,這在 Pulsar 中本來是不可能的。我們甚至還可以利用這一特性,將主題從一個命名空間遷移到另一個命名空間。我們還可以在 Pulsar 中更新主題的分區數而不會失去消息的順序性。這是目前任何消息隊列都不能提供的。
我們還可以展示主題的使用情況,像一個時間軸一樣,畢竟每個段都是被記錄的。我們可以看到段1是在 Kafka 中,然後我們移動到 Pulsar,然後從 5 個分區擴容到 10 個分區等等。我們可以用它來看到主題在這段時間的自然演變。
最後,我們正在將 Varadhi 開源。我們現在正在重新審視 Varadhi,做一些徹底的改進。我們正在重寫所有的模型,以解決我們在初版 Varadhi 中發現的一些架構漏洞,並希望將其貢獻給開源社區。
- 代碼倉庫:https://github.com/flipkart-incubator/varadhi[1]
- 博客《Flipkart消息總線故障處理方法》:https://blog.flipkart.tech/effective-failure-handling-in-flipkarts-message-bus-436c36be76cc[2]
我們會很高興聽到來自您的反饋。如果您有任何問題,可以聯繫 Pulsar 社區,或者直接聯繫我們。感謝大家的時間。
