大模型的"推理能力"能讓機器具備與人類相似的認知和行為能力,能像人一樣理解、思考、學習並解決複雜問題。而在眾多推理能力評測場景中,數學推理任務是當前衡量和追蹤模型推理能力進展的 "黃金標尺"。與此同時,主流數學推理評測體系正面臨關鍵瓶頸:部分頂尖模型在常用的數學推理評測任務中,如 AIME24/25 的正確率已突破 90%,評測區分度大幅下降,難以再有效牽引模型向更高階推理能力進化;此外,現有基準大多源於公開競賽題庫,存在數據穿越風險。

在此背景下,美團 LongCat 團隊發佈數學推理評測基準------ AMO-Bench 。該評測集共包含 50 道競賽專家原創試題, 所有題目均對標甚至超越 IMO 競賽難度。目前,頭部大模型在 AMO-Bench 上的最好表現也尚未及格,SOTA 性能僅為 52.4%,絕大多數模型正確率低於 40%。AMO-Bench 既揭示出當前大語言模型在處理複雜推理任務上的侷限性,同時也為模型推理能力的進一步提升樹立了新的的標杆。
AMO-Bench 的評測榜單將保持更新,歡迎持續關注:
- 項目主頁 :http://amo-bench.github.io/
- Github 地址 :https://github.com/meituan-longcat/AMO-Bench
- Hugging Face 地址 :https://huggingface.co/datasets/meituan-longcat/AMO-Bench
一、評測現狀:老題庫 "失效",行業亟需高難度原創基準
現有數學評測 benchmark 因出現嚴重的性能飽和問題,已無法有效指引頭部大語言模型推理能力的進一步提升。一方面,隨着 AIME、HMMT 等競賽題庫的公開,模型有可能通過訓練數據 "背誦答案",成績可信度存疑;另一方面,隨着模型的快速迭代升級,現有評測榜單上頭部模型的得分趨同,因此逐漸失去鑑別模型能力差異的價值。為進一步提升評測集的難度,已有工作考慮直接使用 IMO 等等有挑戰性的競賽原題對模型進行評測。然而,現有 IMO 題目仍以證明題為主,極度依賴人工批改模型的複雜證明過程,單題批改需 30 分鐘以上,評測效率低下且易受主觀因素影響。
當前行業迫切需要一套 "高難度 + 原創 + 可自動化" 的評測方案。在這一背景下,AMO-Bench 的推出直擊行業痛點------ 50 道競賽專家原創題目、對標甚至超越 IMO 的試題難度、配套高效高準確率的自動化打分算法,為大模型推理能力評測提供了可落地的新標杆。
二、AMO-Bench:高難度數學推理評測的 "行業新標杆"
AMO-Bench 擁有一套系統化的數據構建邏輯、清晰的數據難度特徵與針對性的模型打分算法,為行業提供了一套可信賴且置信的評測方案。
2.1 AMO-Bench 的構建
為打造兼具高質量、強原創性與高挑戰性的數據集,LongCat 團隊構建了一套 "數據創建 - 質量審查 - 原創性審查 - 難度審查" 全鏈路流程。
數據創建:專家原創,自帶 "解題説明書"
- 題目由具備數學奧林匹克競賽獲獎經歷或相關競賽出題經驗的頂尖專家獨立設計,每道試題不僅提供最終答案,還詳細撰寫了 step-by-step 解題路徑 ------ 從關鍵定理應用到邏輯推導節點,每一步都清晰標註,既為後續審查提供依據,也為模型錯誤分析預留 "參考座標"。
質量審查:三重盲審,杜絕 "題不對標"
- 每道題需經 3 位以上專家 "盲審"質檢,重點核查兩大核心:一是題目表述與解題邏輯是否無歧義,避免因題幹模糊導致的模型誤判;二是所需數學知識是否嚴格匹配數學奧賽考察的知識範圍(如代數、幾何、數論等核心領域),確保不超綱、不偏題,真正考驗模型的推理能力。
原創性審查:題庫匹配 + 人工核驗,切斷 "數據穿越"
- 採用 "技術核驗 + 專家經驗" 雙重保障:通過 n-gram 文本匹配與互聯網檢索等方式,與 AIME24/25 等主流競賽數據集和在線數據庫進行比對,排除與現有數據資源中高度相似的題目;同時依靠專家經驗進行人工核驗,確保與過往競賽題無高度重合,杜絕模型 "背答案" 的可能。
難度審查:雙標篩選,確保 "夠硬核"
- 採用雙重難度篩選標準來保證每一道題目都具備足夠挑戰性:首先使用國內外最頂尖模型進行篩選,要求至少 2 款模型在 3 次獨立測試中無法全部答對;其次候選題目需要經過第三方專家進行二次審核題目難度,確保題目難度不低於 IMO 標準。
2.2 數據集:覆蓋核心領域,推理複雜度顯著升級
AMO-Bench 的 50 道題目覆蓋數學奧賽核心領域,且從解題複雜度上實現對現有基準的全面超越。
題目分類:覆蓋五大核心領域
參照國際數學競賽官方競賽大綱,題目被劃分為五大類:代數方程與不等式(11 題,佔比 22%)、函數與數列(13 題,佔比 26%)、幾何(5 題,佔比 10%)、數論(9 題,佔比 18%)、組合數學(12 題,佔比 24%),覆蓋數學奧賽核心知識點,考察模型在不同領域是否存在能力短板。

解題複雜度:答案長度遠超傳統基準
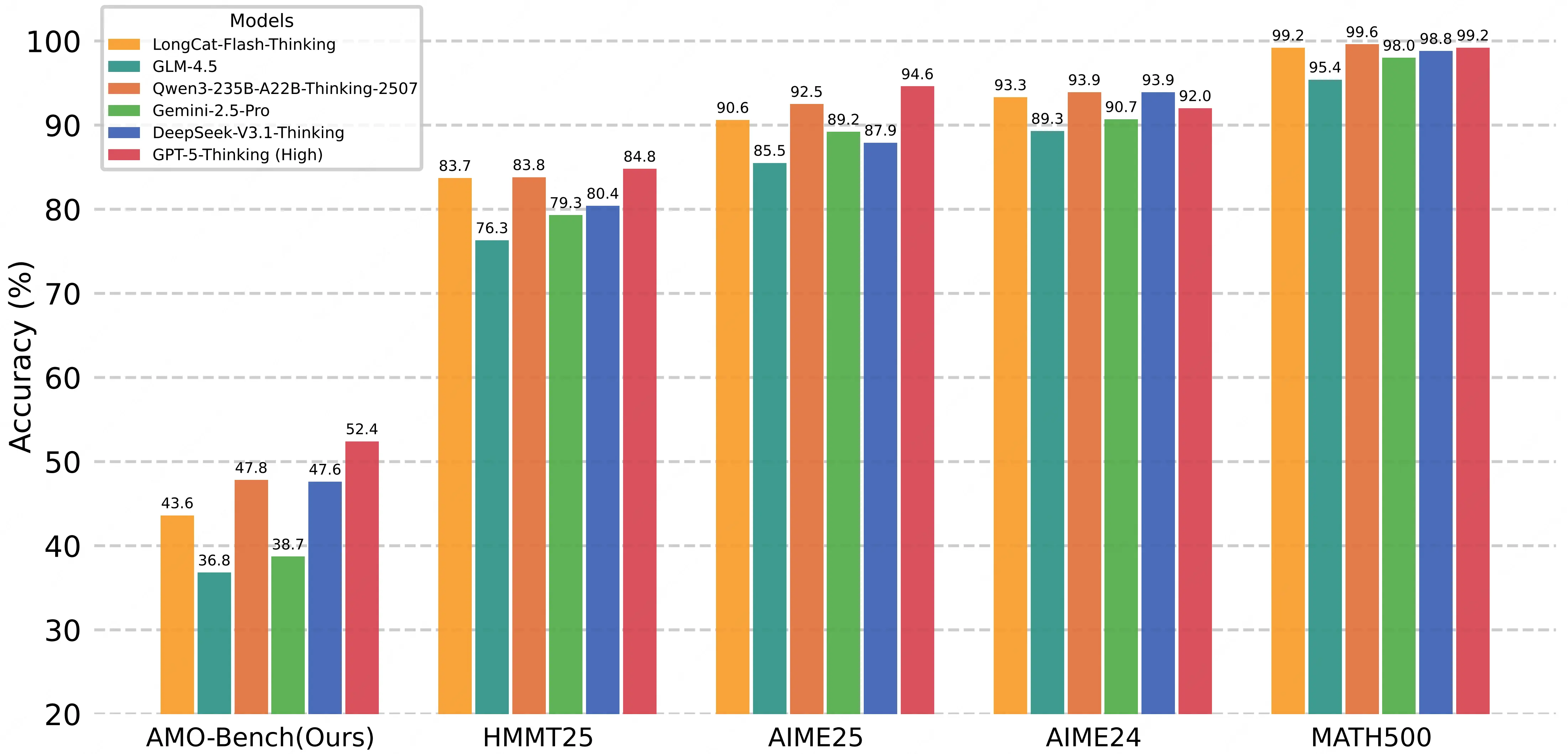
通過對比大模型在 AMO-Bench 和現有數學評測集上的輸出長度,可以看到,隨着數據集難度的提升,模型表現在逐漸走低的同時,其輸出 token 數量也會大幅增加。
大模型在 AMO-Bench 上的解題步驟長度顯著長於現有 AIME/HMMT 等評測集,這意味着 AMO-Bench 的題目需要模型構建更長、更復雜的邏輯鏈才能解答,本質上更具挑戰性,能更精準地檢驗大模型的深度數學推理能力。
2.3 評分方法:兼顧 "自動化" 與 "準確性"
AMO-Bench 的問題答案類型可以概括為四種類型,為兼顧打分準確率和打分效率,我們針對不同的答案類型匹配相應的評分方式:
-
數值 / 集合 / 變量表達式類(39 題):採用 "parser-based 自動評分",要求模型將答案按指定格式(答案)輸出,使用 Math-Verify 工具核驗模型結果與標準答案的等價性;
-
描述性答案(11 題):採用 "LLM 評分 + Majority Voting",在實驗中使用了 o4-mini(Low)為評分模型,對同一答案進行 5 次獨立評分採樣,取多數結果作為最終得分,以減小打分模型採樣的波動性。
為了驗證打分方案的準確率,我們隨機抽取了 10 款不同模型生成的 1000 組答案打分結果進行人工檢查,結果顯示 AMO-Bench 的評分方案准確率高達 99.2%,為大規模自動化評測提供了堅實保障。




三、實驗與分析:AMO-Bench 揭示大模型數學推理的能力邊界
為全面揭示當前大模型數學推理的能力邊界,LongCat 團隊分別從 "開源 / 閉源"和"推理 / 非推理" 兩方面共篩選了 26 個頭部大語言模型,真實的反應了當前主流模型在數學推理能力上的實際表現。
3.1 整體能力格局:頂尖模型仍 "不及格",能力梯度差異顯著
從核心指標來看,當前大部分大模型在 AMO-Bench 上的表現遠未達及格水平,且不同類型模型間呈現明顯能力分層:
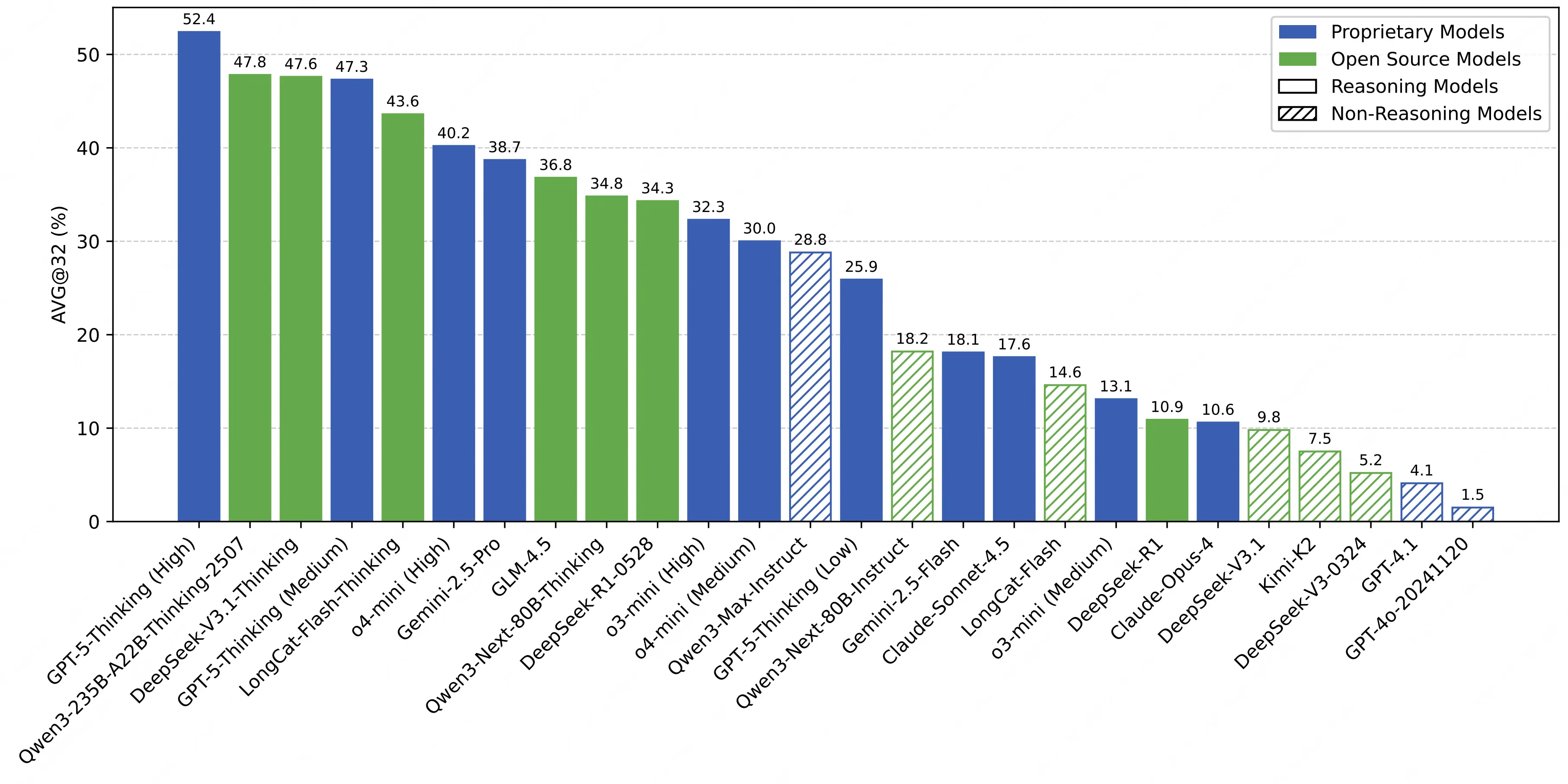
- 閉源推理模型領跑,仍有巨大提升空間:表現最優的 GPT-5-Thinking(High)正確率僅 52.4%,且大部分模型表現低於 40%,即便頭部閉源模型,也未突破 "及格線",凸顯 IMO 級難度的原創題對當前 AI 的挑戰性;
- 開源模型仍有差距,但已在全力追趕:開源模型中 Qwen3-235B-A22B-Thinking-2507 正確率為 47.8%,DeepSeek-V3.1-Thinking 為 47.6%,距離最好表現的 GPT-5 仍有一定差距,但已明顯超越 o4-mini 和 Gemini-2.5-Pro,展示出開源模型奮起直追的勢頭。
3.2 推理效率關聯:Test-Time Scaling 效果顯著
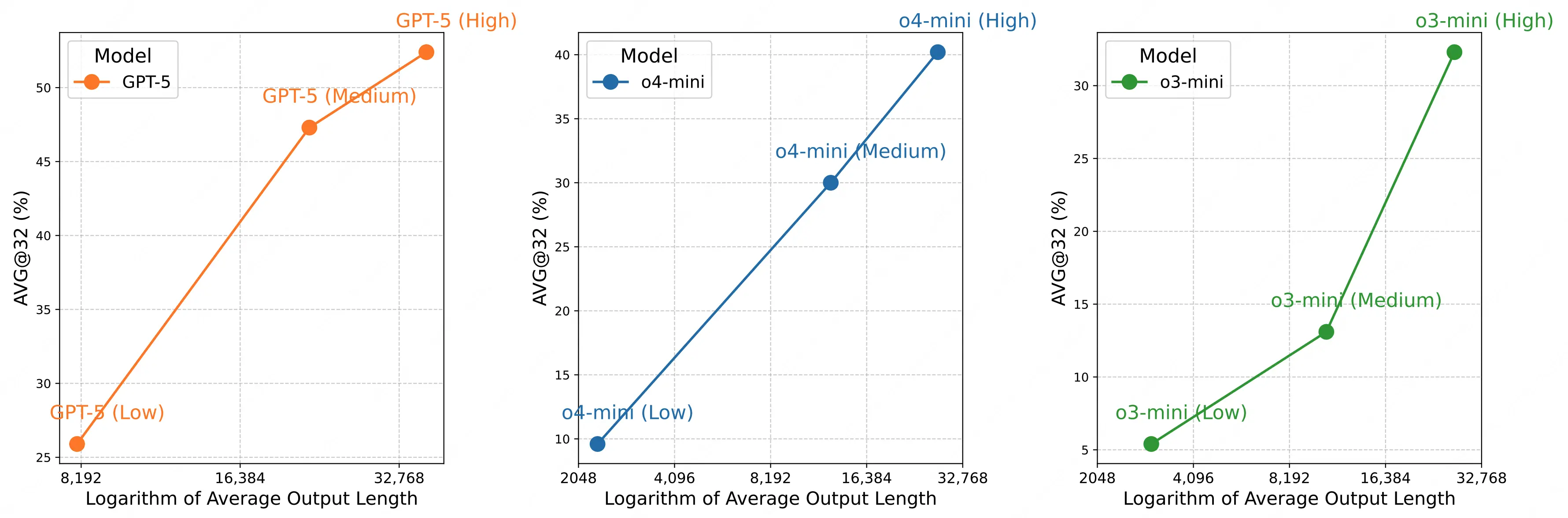
通過分析模型在 AMO-Bench 上輸出長度與模型表現的關係,LongCat 團隊指出,當前 test-time scaling 仍然是提升模型推理表現的有效手段。
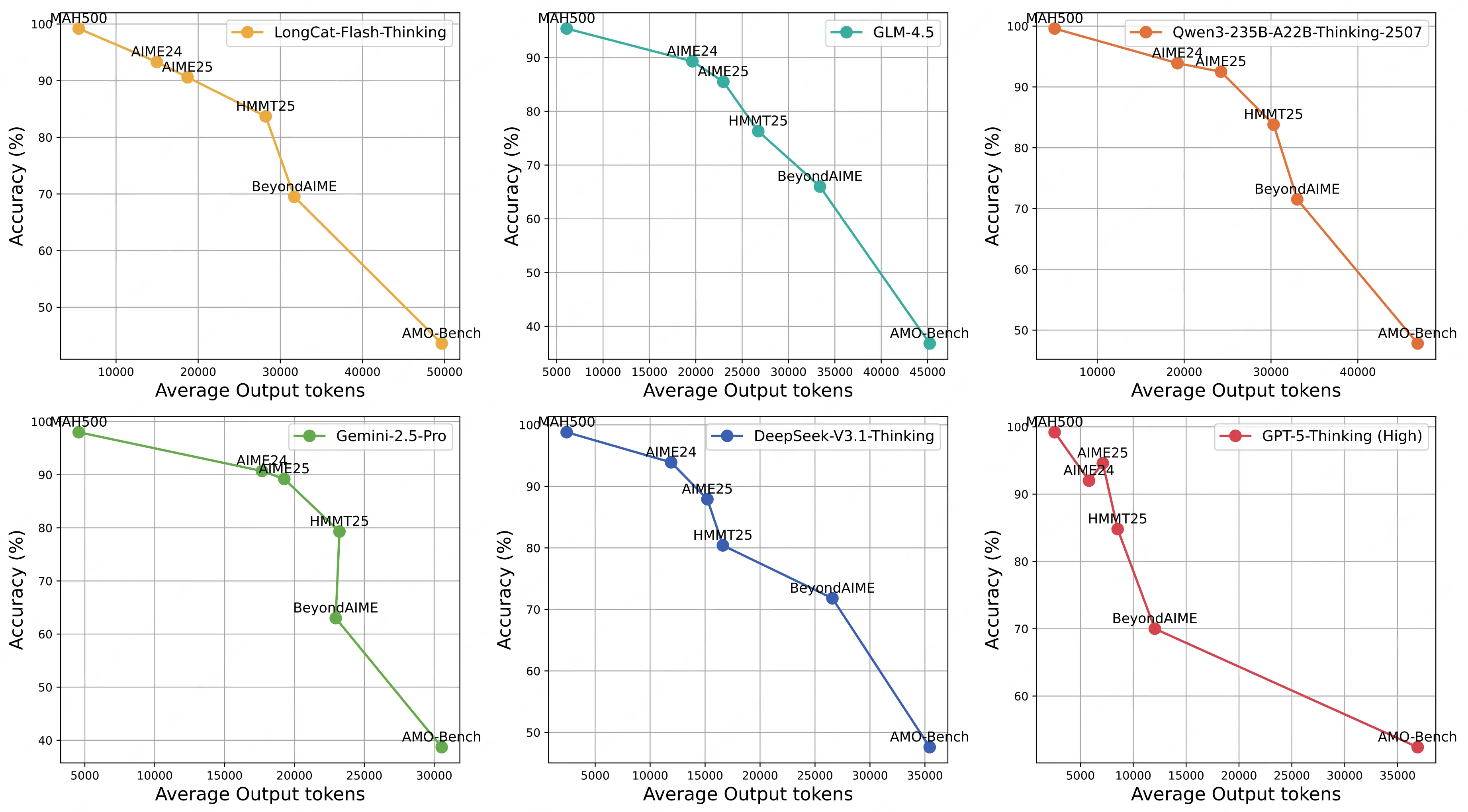
- 高得分模型依賴更多 token 輸出 :AVG@32 超 40% 的模型(如 GPT-5-Thinking、DeepSeek-V3.1-Thinking),平均輸出 token 量均超 35K,意味着當前的頭部推理模型能通過構建顯著更長的邏輯鏈來達到更好的解題表現。
- 同系列模型迭代體現效率提升:以 o 系列模型為例,o4-mini(High)在相近 token 量下,正確率(40.2%)顯著高於 o3-mini(High)(32.3%);DeepSeek-V3.1-Thinking 較前代 DeepSeek-R1-0528,則進一步用更少 token(32K vs 38K)實現了更高正確率(47.6% vs 34.3%),證明新一代模型可以用更高的效率獲取更強的推理性能。
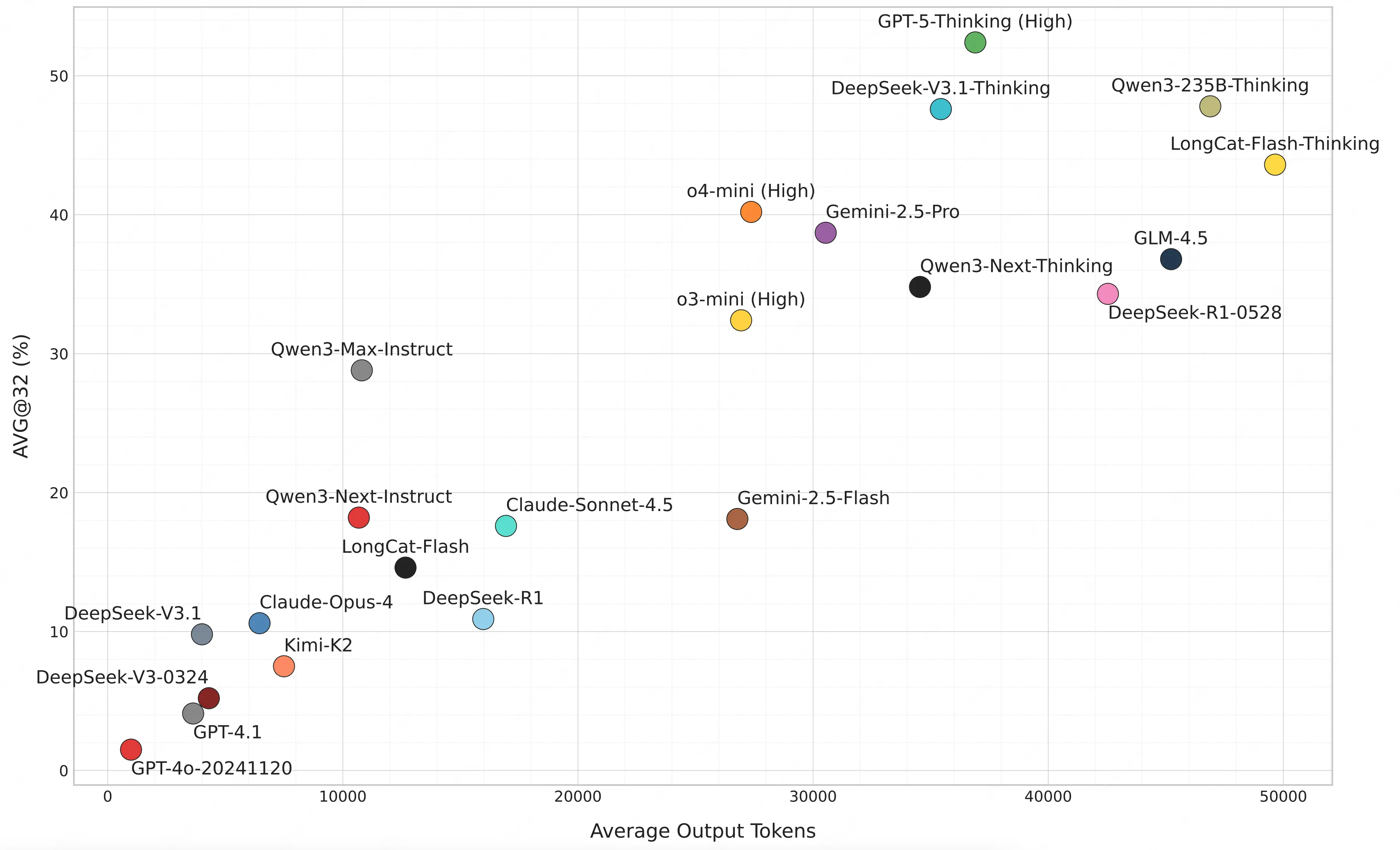
- 推理投入與得分呈對數線性增長:同一模型正確率與輸出長度對數呈近線性正相關,且這一趨勢與現有工作在 MATH500、AIME24 等基準上的實驗觀察一致,證明增加推理計算投入仍是提升模型解決複雜任務能力的有效路徑。
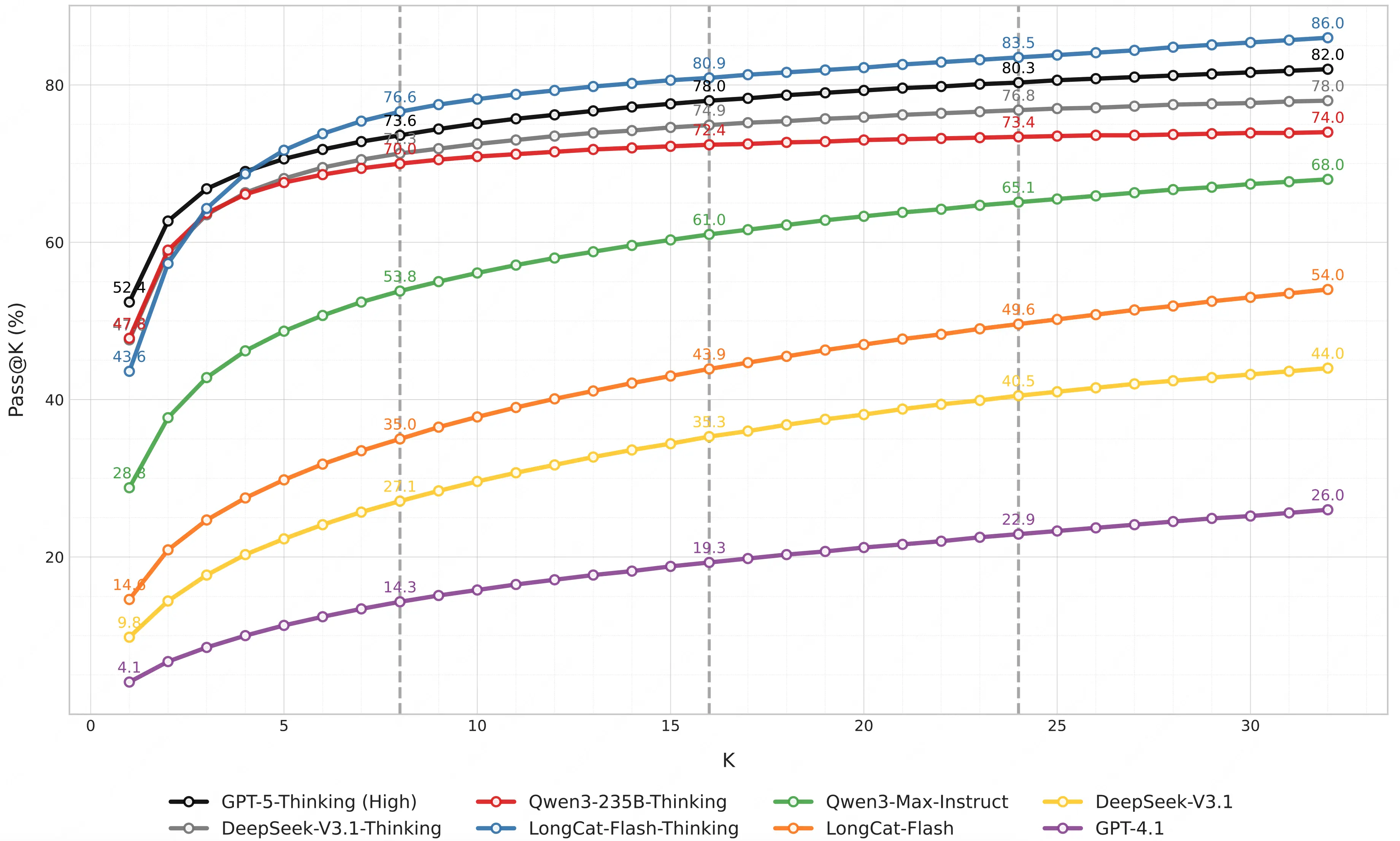
3.3 潛在能力挖掘:模型多次嘗試下的探索潛力
通過進一步分析模型的 "Pass@k" 表現(k 次嘗試至少答對 1 次),LongCat 團隊指出,前沿推理模型如 GPT-5-Thinking(High)、DeepSeek-V3.1-Thinking 等在 AMO-Bench 上能達到 Pass@32 超 70%,表明當前大模型暗含解決難題的潛力,其性能仍有巨大提升空間。
四、總結與展望
綜上,AMO-Bench 相比 AIME24/25 等主流數學評測集具備了更好的區分度和模型提升空間,同時通過 IMO 級別的原創題解決了因數據泄露的潛在風險造成的評估失真問題,以及憑藉 99.2% 的高打分準確率保證了自動化評測的準確性。未來,美團 LongCat 團隊將持續更新 AMO-Bench 評測集,擴大題目覆蓋類型與優化評測方案,同時會進一步探索包括通用和學科推理在內的高難度評測集建設,助力業界大模型在推理能力上的持續提升。
閲讀更多
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明"內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
