據 Hugging Face 頁面顯示,深度求索 DeepSeek 團隊發佈了大語言模型 DeepSeekMath-V2,聚焦可自驗證的數學定理證明能力,實現可自驗證的數學推理突破。
該模型通過訓練一個高精度、高保真的驗證器,並以其作為獎勵信號引導證明生成器自我修正,形成“生成—驗證—優化”閉環。為應對生成與驗證能力同步提升的挑戰,團隊提出擴展驗證計算資源以自動標註難驗證樣本,持續優化驗證器性能。

競賽表現:
- IMO 2025:解決5題(83.3%準確率),達金牌水平;
- CMO 2024:獲73.8%分數,達中國奧賽金牌線;
- Putnam 2024:118/120分,超越人類最高分(90分)。

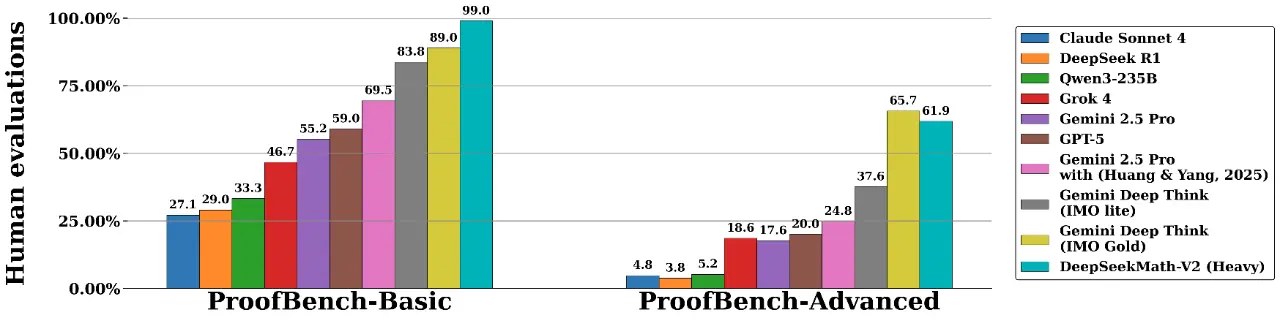
在 IMO 2025、CMO 2024 和 Putnam 2024 等權威賽事中,DeepSeekMath-V2 表現卓越,分別取得金牌水平及118/120的近滿分成績。團隊表示,該成果驗證了自驗證推理路徑的可行性,為構建可靠數學智能系統提供新方向。模型基於 DeepSeek-V3.2-Exp-Base 構建,已按 Apache 2.0 協議開源。
論文標題:DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
模型地址:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
論文地址:https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf
