導讀
在這個高速發展的信息時代,數據洪流已經成為了企業在數字化轉型過程中遇到的核心挑戰,而流式計算正是應對無界數據流的利器。然而,隨着流式技術的普及與發展,其固有的複雜性也日益凸顯:
-
開發門檻高:需要開發者深入掌握事件時間處理、窗口機制、狀態管理等複雜概念;
-
運維成本高:實時系統的容錯保障、監控告警與性能調優,往往比離線系統耗費更多人力;
-
擴展性差:傳統流式架構僵化,難以靈活、高效地響應業務的快速迭代與規模增長。
面對這些挑戰,業界共識逐漸清晰:流式計算的未來,不應只屬於少數專家,而應成為每個團隊都能高效使用的通用能力。為此,一種新的破局思路正在興起——將流式計算與雲原生理念深度融合,構建以 Kubernetes 為底座、以開發者體驗為中心的 PaaS 化流式開發平台。
這樣的平台,不僅將底層基礎設施的複雜性封裝於服務之中,更通過配置化、模板化、自動化的手段,把專家經驗轉化為平台默認能力,真正實現“讓實時計算像搭積木一樣簡單”。這正是本文所要探討的核心命題:如何基於雲原生技術,打造一個高效、可靠、易用的新一代流式計算 PaaS 平台。
01 背景
1.1 流式計算簡介
流式計算(Stream Compute)是一種對無界數據流進行實時處理的計算模式。相比於傳統的批處理先存儲後計算的模型,流式計算會在數據生成時便持續不段的導入、處理和分析,並近乎實時地產出連續的結果。
如果將數據源看做一條奔流不息的“數據河流”:
-
批處理:修築水壩,先將河水攔截並蓄水至一定水位線(存儲),然後再開閘放水進行計算。這種方式延遲高,但是吞吐量大,適合對時效性不高的海量數據進行離線分析;
-
流式計算:在河牀上安裝一套實時監測和過濾系統,對流淌過的每一滴水進行即時分析處理。這種方式延遲極低,使業務能夠對瞬息萬變的業務場景做出及時反應。
因此,流式計算的核心價值就是時效性,將數據分析這個原本應該出現在“事後覆盤”的環節提前到“事中干預”甚至“事前預測”。這在例如實時監控、實時風控、實時推薦等關鍵業務場景中起到了重要的作用。
1.2 傳統流式計算核心挑戰
儘管流式計算憑藉其時效性高的優點,在企業的業務發展中越來越佔據了核心地位,但是由於其複雜性,成了制約企業發展的一個障礙,主要分為開發門檻高、運維成本高、擴展性差三個方面。
1.2.1 開發門檻高
當前市面上主流的流式計算框架(如Flink、Spark Streaming等)以及百度自研的流式計算框架TM,雖然功能強大,但是學習路徑異常陡峭。開發者不僅需要了解分佈式系統的基本原理,還需要了解:
-
事件時間與處理時間的處理:如何正確處理亂序事件、延遲數據到達時應該怎麼處理等等,這些問題是實現精確業務邏輯的前提,同時也是最容易出錯的部分;
-
複雜的窗口機制:窗口一般分為滾動窗口、滑動窗口和會話窗口,不同窗口的適用場景與配置差異有很大區別,如果選擇不當也將影響業務效果;
-
狀態管理機制:有狀態計算是流處理的核心問題,而狀態的容錯、恢復與一致性保障(如Exactly-Once)機制複雜,對開發者的要求也更高。
1.2.2 運維成本高
與離線的批處理不同,流式系統的運維是持續且動態的,這也導致了高昂的運維成本,主要體現在:
-
容錯:在節點故障、網絡抖動的情況下,如何保證不重不丟,這就需要複雜的檢查點(Checkpoint)機制和保存點(Savepoint)機制;
-
實時監控與告警:流式系統本身的秒級時效也要求運維團隊能夠秒級發現並響應問題 ,為了達到這個目標,需要針對於任務延遲、反壓(Backpressure)、資源使用率等關鍵指標配置複雜的監控和告警體系;
-
持續的性能調優:流式系統的特點是在運行起來之前,沒人知道應該怎麼樣配置資源參數,因為一點點數據量的波動或者業務邏輯變更都可能引發性能瓶頸,造成延遲或者反壓等問題。這就需要運維人員持續地針對於系統進行調參,包括並行度、內存資源參數等等。
1.2.3 擴展性差
早期的各類流式計算框架設計上相對僵化,而難以靈活應對當前快速發展的業務需求,其擴展性主要是受制於以下三個方面:
-
架構耦合度高:計算邏輯與底層資源、存儲強耦合,這就導致了升級或遷移時成本較高;
-
彈性伸縮能力弱:部分流式場景可能會面臨突如其來的熱點問題,如雙十一電商大促,面對可能到來的流量高峯,只能提前估算並擴容,同樣地當流量低谷到來時,也將造成資源浪費。在高速迭代的場景下,這樣不夠靈活的模式越來越捉襟見肘;
-
業務迭代不敏捷:實際企業業務場景中實時指標或者計算口徑的迭代是家常便飯,而現有框架下一個迭代的上線需要複雜的開發、測試、上線流程,無法滿足業務快速發展的要求。
1.3 破局之道——構建雲原生流式計算PaaS平台
面對開發複雜、運維繁重、擴展受限等痛點,單純依賴底層框架已難以為繼,我們需要一場開發與運維範式的根本性變革。而云原生與PaaS(平台即服務)理念的深度融合,正式引領這場變革的破局點:將流式計算能力封裝起來作為雲原生PaaS服務,通過平台化手段實現能力下沉、體驗上移。
具體而言,平台以Kubernetes為底座,融合配置化開發模型與智能化運行引擎,達成三大轉變:
-
從“寫代碼”到“配任務”:通過標準化的表單化配置,抽象事件時間、窗口、狀態等複雜概念,用户只需聲明數據源、處理邏輯與輸出目標,即可生成可運行的流式作業,大幅降低開發門檻;
-
從“人肉運維”到“自動治理”:依託 Kubernetes 的彈性調度、健康探針與 Operator 模式,平台自動完成任務部署、擴縮容、故障恢復與指標採集,將運維複雜度內化於平台;
-
從“煙囱式架構”到“服務化複用”:通過統一的元數據管理、連接器庫與模板市場,實現計算邏輯、數據源、監控策略的跨團隊複用,支撐業務敏捷迭代與規模化擴展。
這一 PaaS 化轉型,不僅繼承了雲原生技術在資源效率、可觀測性與自動化方面的優勢,更將流式計算從“專家專屬工具”轉變為“全員可用服務”,為企業實時數據能力建設提供了可持續、可複製的基礎設施。
02 平台架構總覽:雲原生PaaS的設計內核
雲原生技術(容器化、編排調度、微服務、可觀測性)流式計算與PaaS結合提供了 “物理基礎”,讓平台化能力有了落地的土壤。其核心價值在於實現了流式系統的 “標準化、彈性化、可感知”:
-
標準化部署:通過 Docker 容器化封裝流式任務及其依賴環境,消除 “開發環境與生產環境不一致” 的痛點,同時讓任務的部署、遷移、複製變得高效統一 —— 這是智能化調度和彈性擴縮容的前提,確保系統能對任務進行精準操作;
-
彈性編排調度:基於 Kubernetes(K8s)的編排能力,實現流式任務的自動化部署、調度與生命週期管理。K8s 的 Pod 調度、StatefulSet 狀態管理等特性,為流式任務的水平擴縮、故障轉移提供了底層支撐,讓資源調整變得靈活可控;
-
全鏈路可觀測:雲原生可觀測性技術(Prometheus、Grafana、Jaeger 等)構建了 Metrics(指標)、Logs(日誌)、Traces(鏈路追蹤)三維監控體系,讓流式系統的運行狀態 “可視化、可量化、可追溯”。
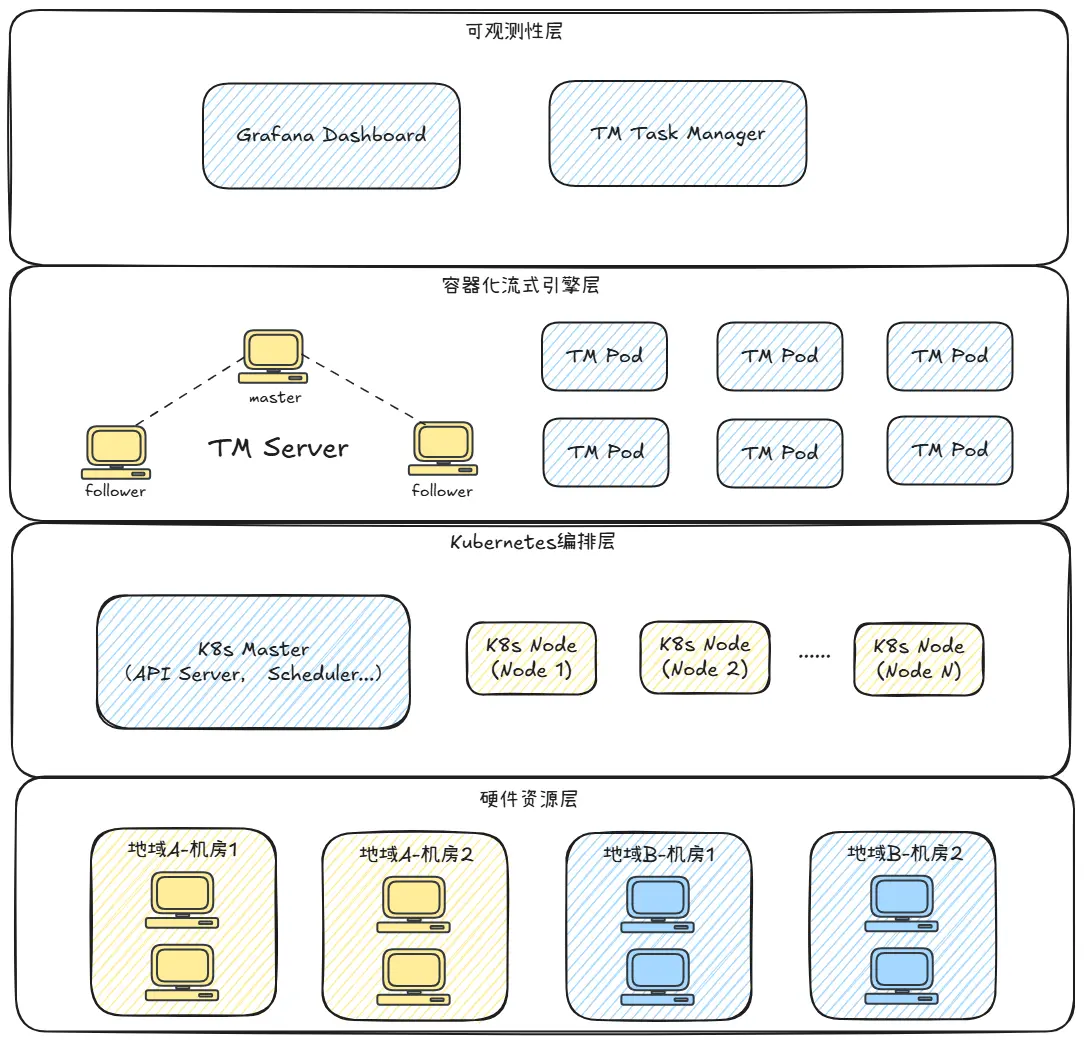
依託雲原生的技術,我們構建了四層架構的流式計算基礎設施架構,是PaaS落地的技術底座:
-
硬件資源層:以多地域、多機房的服務器集羣為物理支撐,通過分佈式部署實現資源規模化與容災能力,為上層提供算力基礎;
-
Kubernetes 編排層:由 K8s Master(集成 API Server、調度器等核心組件)和多節點 K8s Node 組成,承擔資源調度、任務編排、彈性擴縮的核心能力,實現流式任務的自動化部署、生命週期管理與資源動態分配;
-
容器化流式引擎層:以容器化 Pod 形式運行基於廠內自研流式框架TM的算子,通過容器標準化封裝消除環境差異,支持水平擴縮容,讓計算能力可根據業務流量彈性適配;
-
可觀測性層:通過 Grafana Dashboard 等工具構建全鏈路監控體系,覆蓋指標、日誌、鏈路追蹤,為用户實時感知系統狀態,及時決策提供了數據支撐。
四層架構的協同,最終實現了****“標準化部署、彈性資源調度、全鏈路可觀測”****的雲原生能力,為流式計算的 PaaS 化封裝提供了堅實技術底座 —— 將底層複雜的資源管理、引擎調度、監控採集能力下沉,向上層用户暴露 “簡單、易用、高效” 的配置化開發接口,完美承接 “降低門檻、簡化運維、提升彈性” 的核心目標,讓流式計算能力真正以 “服務” 形式交付。
2.1 基石:Kubernetes編排層——資源的智能大腦
Kubernetes 不僅是容器編排引擎,更是整個流式平台的“智能調度中樞”,它是整個平台彈性與自動化的基石。
我們基於K8s實現了流式任務的聲明式管理與智能調度。用户提交的任務需求(如所需CPU、內存)被抽象為K8s的定製化資源,而平台的流式任務算子則作為集羣內的“自動化運維機器人”,持續監聽這些資源狀態,並驅動底層執行。其核心價值體現在:
-
聲明式部署與自愈:平台將用户配置的流式任務,自動轉換為由Deployment(無狀態任務)或StatefulSet(有狀態任務,保障Pod名稱與存儲的穩定)管理的Pod組。當某個Pod因節點故障意外退出時,K8s的控制器會立即在健康節點上重建,通常在秒級內完成故障恢復,實現了從“人工響應”到“自動癒合”的質變。
-
高效運維與彈性基礎:Kubernetes的聲明式API與資源模型,為流式任務的高效運維與可控彈性提供了完美基礎。平台基於此定義了清晰的資源規格與副本數配置。當業務需要擴縮容時,運維人員只需通過平台更新一個配置值,K8s調度器便會自動、可靠地完成整個實例的擴容或優雅終止流程。這種模式將傳統的、易出錯的手工部署,轉變為一種可審計、可回滾、分鐘級內完成的標準化操作,為應對計劃內的流量洪峯(如大促)提供了敏捷且可靠的彈性能力。
-
資源隔離與高效利用:通過K8s的Namespace和Resource Quota,平台可以為不同部門或業務線創建邏輯上隔離的資源池,避免相互干擾。同時,K8s調度器能基於節點的實際資源利用率,進行智能裝箱(Bin Packing),顯著提升集羣整體的資源使用效率,降低成本。
綜上所述,Kubernetes 在此不僅是“運行環境”,更是實現了 資源調度、彈性控制、高可用保障 三位一體的智能大腦。
2.2 載體:容器化流式引擎層——應用的標準化封裝
流式計算的複雜性則很大程度上源於環境依賴於運行時差異,而容器化技術是連接用户邏輯與底層資源的“載體”,是徹底解決這一問題的有效方法:
-
統一鏡像規範:所有流式作業基於標準化基礎鏡像構建,預裝基礎環境配置、監控 Agent 和日誌採集器,確保“開發、測試、生產”三環境完全一致;
-
輕量級 Sidecar 模式:每個 Pod 包含主容器(運行流式算子)與 Sidecar 容器(負責日誌上報、指標暴露、配置熱更新),解耦業務邏輯與平台能力;
-
資源隔離與限制:通過 K8s 的
resources.requests/limits精確控制 CPU、內存分配,避免單個任務資源爭搶影響集羣穩定性。
容器在此不僅是“打包工具”,更是 標準化交付、安全隔離、敏捷迭代 的核心載體
2.3 視野:可觀測性層——系統的透明駕駛艙
對於一個持續運行的實時系統,可觀測性如同飛機的駕駛艙儀表盤,是保障其穩定、高效運行的“眼睛”和“直覺”。我們構建了三位一體的可觀測性體系:
-
Metrics(指標)- 系統的脈搏:平台深度集成Prometheus,自動採集每個流式任務Pod的核心性能指標,如****數據吞吐率(records/s)、處理延遲(process_latency)、背壓狀態(is_backpressured)****以及CPU/內存使用率。通過預置的Grafana儀表盤,運維人員可以一眼掌握全局健康狀態,將監控從“黑盒”變為“白盒”。
-
Logs(日誌)- 診斷的溯源:所有容器的標準輸出與錯誤日誌,通過DaemonSet方式被統一收集、索引(如存入Elasticsearch)。當指標出現異常時,運維人員可以快速關聯到對應時間點的詳細應用日誌,精準定位錯誤根源,將排障時間從小時級縮短至分鐘級。
-
Traces(分佈式鏈路追蹤)- 性能的脈絡:對於複雜的數據處理流水線,我們通過集成鏈路追蹤,還原一條數據在流式任務DAG中流經各個算子的完整路徑和耗時。這使得定位性能瓶頸(例如,是哪部分操作拖慢了整體速度)變得直觀而高效。
可觀測性在此不僅是“監控工具”,更是 智能決策的數據源泉,為彈性擴縮、用户及時調優提供實時反饋。
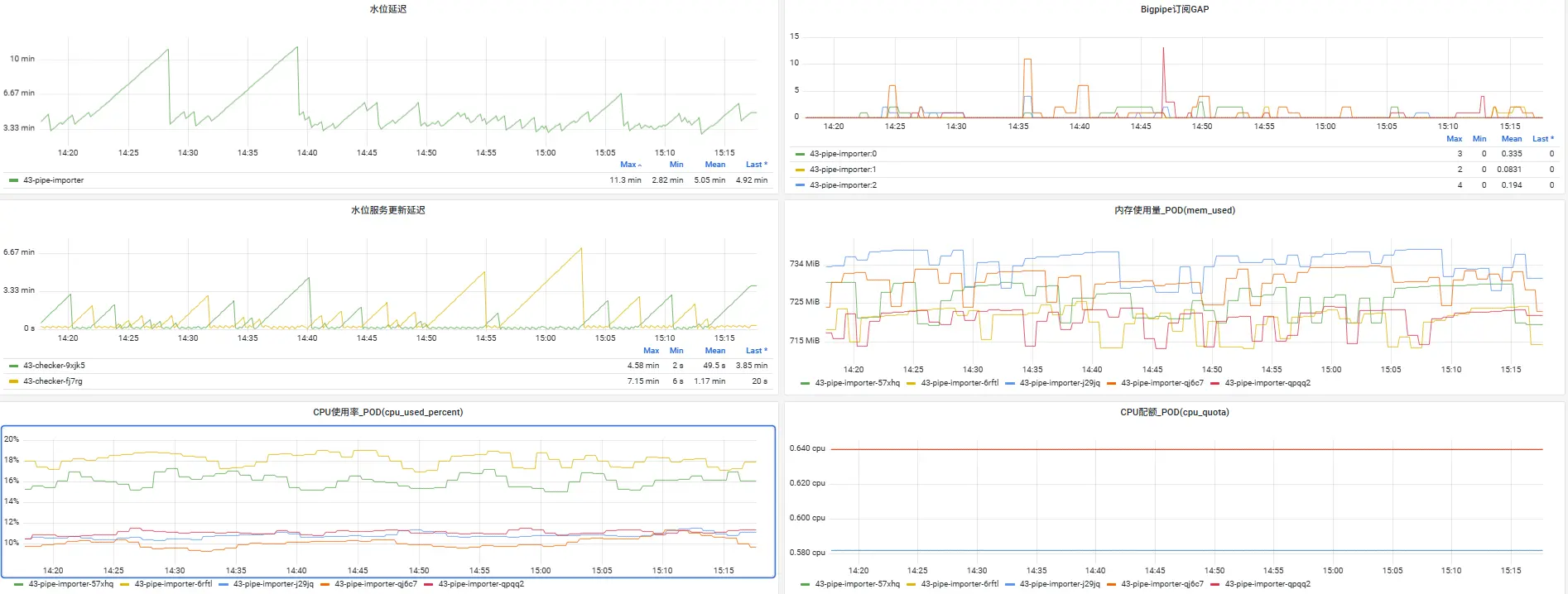
△ Grafana監控儀表盤
2.4 協同:架構驅動的核心價值閉環
上述三層並非孤立存在,而是通過 “聲明 → 執行 → 感知 → 優化” 的閉環緊密協同:
-
用户通過配置聲明業務意圖(如“每分鐘統計活躍用户”);
-
Kubernetes 編排層將其轉化為可調度的 Pod 拓撲,並由容器化引擎執行;
-
可觀測性層持續採集運行數據,形成系統“數字孿生”;
-
平台基於反饋自動觸發彈性擴縮、參數調優或故障恢復,最終兑現 SLA 承諾。
這一閉環,使得平台既能 向下充分利用雲原生基礎設施的能力,又能 向上為用户提供簡單、可靠、高效的流式服務體驗。開發門檻、運維成本、擴展性三大痛點,由此在架構層面被系統性化解。
03 配置化開發——從“編碼”到“裝配”
傳統開發模式下,工程師們需要用代碼手動地去處理流式計算任務的每一個細節,這是需要複雜和強依賴經驗的。而配置化的出現,恰如第一次工業革命的珍妮紡紗機,使工程師們從冗雜的重複工作中釋放出來,將“手工作坊”升級生成“現代化生產線”,使流式計算開發變得普惠和平民化。
3.1 從代碼到配置:開發模式的範式轉移
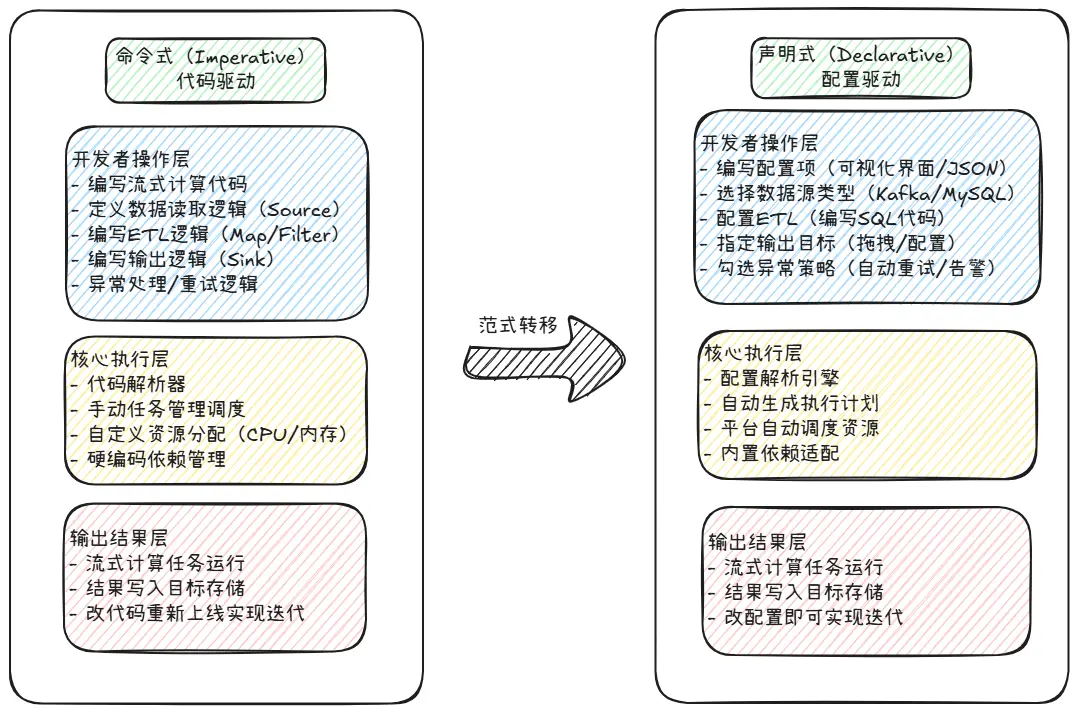
這場革命最初的表現是開發模式的根本性轉變:從****命令式(Imperative)轉變為聲明式(Declarative)****的範式轉移。
-
命令式(寫代碼):開發者需要告訴流式系統****“怎麼做”(How)****,這帶來了極大的靈活性,但是同時也伴隨着極高的複雜度和學習成本;
-
聲明式(寫配置):開發者需要聲明****“做什麼”(What)****,而“怎麼做”則交由底層引擎去完成。
3.2 隱藏的複雜性:從“專家調優”到“配置默認”
常見的流式系統主要由數據源層、核心計算層、時間容錯層、結果輸出層這四部分:
數據源層和結果輸出層,即數據採集和輸出的過程,不在我們此次重點討論的範圍內;
3.2.1 核心計算層
對於核心計算層來説,這裏負責了流式作業的主要業務邏輯計算,其中
-
Import算子——數據接入的“第一入口”
-
算子特點:作為流式數據進入核心計算層的“門户”,核心職責是實現多種類型數據源的接入和初步格式解析,為後續計算環節提供標準化的數據輸入,是保障數據接入穩定性和兼容性的關鍵。
-
傳統開發模式:需要工程師根據不同的輸入數據類型,手動配置響應的鏈接參數,以進行不同的適配;同時還需要自定義數據解析邏輯,處理不同格式數據的字段映射和類型轉換;此外,還需要手動處理連接異常、數據讀取重試等問題,避免數據丟失或重複處理。
-
配置化調優:無需手動編寫接入與解析代碼,支持多種主流數據格式,如CSV、Parquet、PB等;對於PB格式來説,在預置的標準數據格式模板的基礎上,支持上傳自定義proto後,通過反射將proto內各個字段映射成便於用户處理的Schema;同時系統內部集成連接容錯、自動重試、斷點續讀機制,保證數據接入的穩定性。
-
-
Map/Filter算子——數據預處理的第一個環節
-
算子特點:最基礎、高頻的算子,Map 負責對單條數據做結構化轉換(如字段格式清洗、維度擴充、單位換算),Filter 則按業務規則篩選數據(如過濾空值、無效訂單、非目標場景數據),是所有業務邏輯落地的前置環節;
-
傳統開發模式:開發流式作業時需要工程師手動編寫定義轉換/篩選邏輯, Map需要逐字段處理數據類型轉化,而Filter要精確寫明判斷條件。除了要保證邏輯精準外,還需要兼顧性能,如複雜字段多層嵌套可能會導致單條數據處理耗時過長,進而引發整條流數據延遲;
-
配置化調優:無需編寫一行代碼,通過可視化界面配置流式作業,系統會現針對於用户的數據源進行預處理,將多種多樣的格式處理成便於用户直接用Sql語句直接處理的格式,Map 操作支持拖拽算子、上傳自定義proto等實現,Filter 可通過配置Sql設置過濾規則。
-
-
Aggregate算子——業務指標計算
-
算子特點:針對於實例內拿到的這一批數據,對數據做聚合計算(如求和、計數、平均值、TopN等),是實現實時業務指標統計的核心算子;
-
傳統開發模式:需要工程師自行定義聚合邏輯,如使用hash map做累加器等,在複雜聚合(如多維度嵌套聚合)的情況下,開發難度大,調試成本高,同時還需要兼顧計算時效和聚合粒度等;
-
配置化優化:直接寫Sql的模式極大降低了開發成本,同時底層採用向量化引擎對列進行操作,相較於傳統的行處理模式極大提高了計算效率,提高了時效性。
-
-
Sink算子——計算結果的最終出口
-
算子特點:作為核心計算層的收尾環節,將最終流式作業產出數據輸出至下游目標系統,是實時數據價值落地的關鍵。
-
傳統開發模式:需要工程師手動編寫輸出代碼和配置項,適配下游系統的通信協議與數據格式;同時在Exactly-Once語義要求下,工程師需要協調檢查點與Sink算子的事務或冪等寫入邏輯,實現難度大;與此同時,批量寫入的大小、間隔等參數調優將直接影響吞吐量和端到端延遲。
-
配置化優化:流式開發平台提供了一套標準化的Sink框架,用户只需要指定落盤的目標系統並配置基礎參數,即可實現流式計算結果輸出。目前已支持落盤Afs,廠內自研消息隊列Bigpipe,以及向量化數據庫Doris,未來還將進一步支持Redis、Clickhouse等。
-
-
檢查點:在配置化場景下,用户僅需要配置檢查點存儲路徑,而觸發時機、容錯策略、狀態分片與恢復等底層複雜邏輯全部交由系統自動託管,提升了流式作業的可用性和易用性。
3.2.2 時間與容錯層
時間與容錯層是流式計算中“扛風險,保穩定”的核心支撐,水位控制和狀態管理兩大模塊的底層邏輯複雜且易出錯,傳統開發模式下調優成本高,而配置化將其完全對用户透明,僅在頁面上向用户體現為各個計算環節處理進度。
在流式系統中,水位體現了數據的完整性(水位時間之前的所有數據都已就緒)和可見性(當某條數據處理出現故障,水位便不會再退進,問題由此變得可見),作為這麼重要的一個概念,水位控制就顯得格外重要,往往需要豐富的經驗和多次調優才能達到預期的效果。而在配置化的流式平台中,水位的控制對用户基本透明,僅在運維界面體現為各個算子的當前處理進度,在降低了門檻的前提下又保證了水位的數據完整性和可見性兩個特點。
而狀態管理是Exactly-Once的重要保證,保障了故障恢復時的數據一致性。傳統開發模式下,用户需手動設計狀態的存儲結構(如選擇本地內存還是分佈式存儲)、編寫狀態序列化 / 反序列化代碼、規劃狀態分片策略以避免單點瓶頸,還要手動處理狀態版本衝突、清理過期狀態以防止存儲膨脹,每一步都依賴對底層存儲和分佈式系統的深度理解。而在配置化的幫助下,這些技術被完全封裝,用户僅需要配置狀態存儲的路徑,其他則完全交由系統實現。
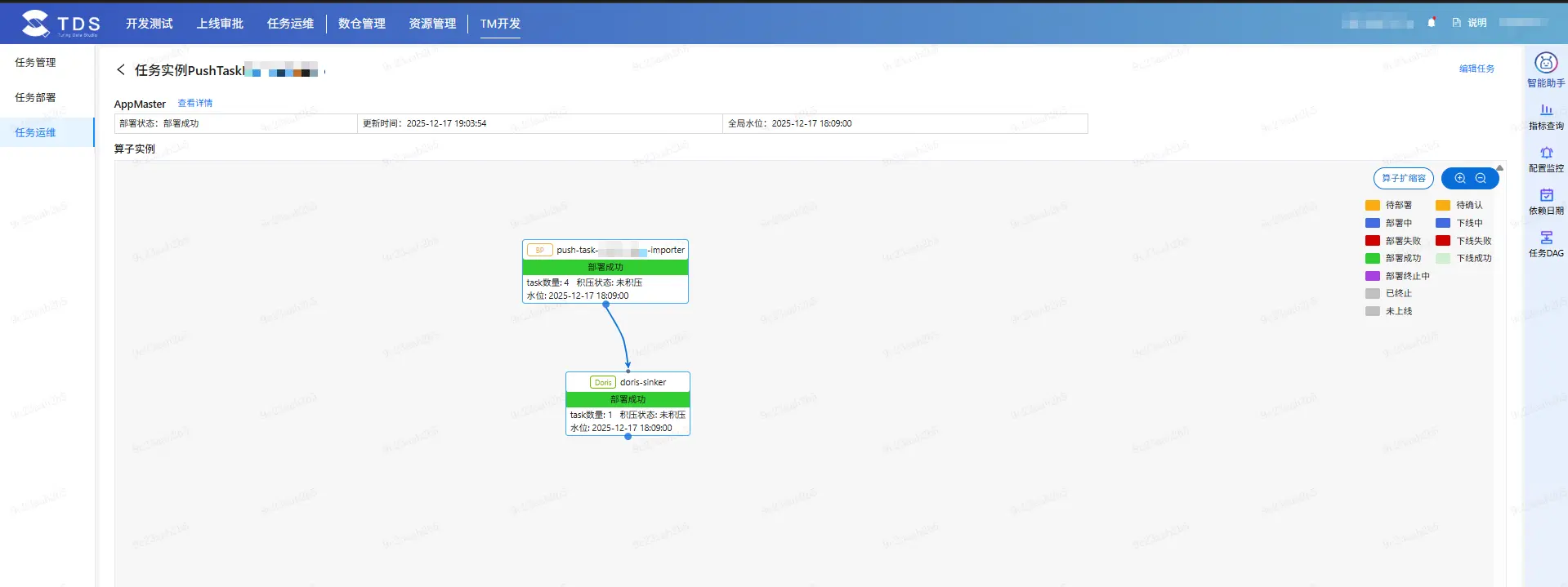
3.3 實踐——Push業務在流式計算開發平台的落地
目前,Push業務實時方向優先在流式計算開發平台落地實踐,這一決策不僅契合流式計算場景“低延遲、高吞吐、實時處理”的核心特性,更通過創新的開發方式實現了業務價值的高效釋放——相較於傳統開發模式中“開發-測試-部署-迭代”的冗長鏈路,新方案大幅簡化了流式任務的編排、調試與上線流程,減少了環境適配、依賴衝突等冗餘環節,讓開發人員能夠聚焦核心業務邏輯的迭代優化,無需投入過多精力在底層環境搭建與運維工作上。最終,這一落地策略顯著縮短了業務需求從提出到上線的週期,極大提升了業務更新迭代的效率,助力業務快速響應市場變化、迭代產品功能,同時降低了開發與運維成本,為後續在更多雲原生、實時計算相關業務場景的規模化推廣奠定了堅實基礎。
3.4 降本增效與敏捷迭代
配置化帶來的價值是多維且立竿見影的,與我們在背景中討論過的核心挑戰相呼應:
-
大幅降低開發門檻和人力成本:在有了配置化之後,業務部門想要開發流式任務便不再需要向流式部門提需,只需要經過簡單培訓即可上手,同時也降低了溝通成本,團隊的人力成本得以有效優化;
-
顯著提升運維效率與系統穩定性:標準化的核心優勢就是避免了很多人為錯誤,同時作為模板一定是經過多次試驗後的最佳實踐,能夠保障作業運行的基線性能。同時,統一的交互界面將各個操作接口收口到一個平台上,極大降低了操作成本,版本管理、作業啓停變得輕而易舉,極大提升了運維效率;
-
極致優化資源利用:聲明式的資源配置讓流式系統可以更加靈活地進行資源擴速容調度和優化,避免了資源浪費或瓶頸;
-
賦能業務敏捷迭代:從前每個簡單的迭代(例如將落盤窗口從5分鐘修改成15分鐘)都需要走開發-測試-上線的繁瑣流程,往往會耗時半天至一天,而有了配置化後,僅僅需要在配置界面修改一個參數並重新發布部署即可實現修改,實現了真正的“敏捷開發”,讓業務創新快人一步。
04 總結與展望
通過構建基於 Kubernetes 的雲原生流式計算 PaaS 平台,我們不僅解決了傳統流式系統“開發難、運維重、擴展弱”的三大痛點,更完成了一次開發範式的躍遷——從“手寫代碼、手動調優”走向“配置驅動、平台兜底”。開發者不再需要深陷於資源調度、狀態管理、容錯機制等底層複雜性,而是聚焦於業務邏輯本身,真正實現“所想即所得”的流式應用構建體驗。這一轉變的背後,是平台將多年積累的流式計算最佳實踐,以標準化、自動化的方式內嵌於架構之中。無論是時間語義的精準處理,還是 Checkpoint 與 Exactly-Once 的默認保障,平台都在默默承擔起“專家角色”,讓普通開發者也能輕鬆駕馭高可靠、高性能的實時計算任務。
展望未來,立足於當前穩固的雲原生底座,平台的演進路徑清晰可見:
-
彈性智能化:當前基於可觀測層豐富的監控指標,為引入更精細的自動化彈性策略奠定了堅實基礎。後續,我們將探索基於自定義監控指標(如水位延遲、CPU使用率、吞吐量波動)的HPA,讓資源擴縮容能緊貼真實業務負載,在保障SLA的同時進一步優化成本。
-
運維自治化:在大模型能力快速發展的當下,基於多年積澱的流式工程經驗方案,在RAG技術的加持下構造流式服務運維智能體,實現運維自治化。
-
體驗服務化(Serverless):在配置化開發之上,最終極的體驗是讓用户完全感知不到底層引擎與基礎設施。未來,平台將向流式計算FaaS(Function-as-a-Service)深化,用户只需提交一段業務處理函數或SQL,平台即可自動完成資源調度、引擎選擇與任務生命週期管理,實現真正的“按需計算”。
