大模型雖已具備強大的感知與推理能力,但在面對複雜的計算機圖形界面操作(Computer Use)任務時,仍受限於高質量數據稀缺與環境交互反饋缺失的雙重挑戰。美團技術團隊推出了 EvoCUA 模型並在Github、Huggingface開源,通過構建可驗證數據合成引擎與十萬級併發的交互沙盒,將訓練範式從傳統的"靜態軌跡模仿"轉變為高效的"經驗進化學習"。該方案在權威評測基準 OSWorld 上以 56.7% 的成功率刷新了開源 SOTA(2026年1月6日榜單),驗證了基於經驗的進化範式在 GUI 智能體領域的有效性。
01 背景與挑戰
隨着大模型的發展,AI 已經具備了強大的感知與推理能力。但在真實的使用場景中,我們希望 Agent 不僅能回答問題,更能解決問題------比如自動處理 Excel 表格、在瀏覽器中完成複雜的資料檢索或跨應用協同。這種對解決問題能力的追求,推動了基礎模型從 Chat(對話者)到 Agent(行動者) 的轉變。
在這一進程中,Computer Use Agent(CUA,計算機操作智能體) 是一個關鍵里程碑。CUA打破了 API 的限制,構建了一種原生的交互方式------像人類一樣,通過高分辨率視覺感知屏幕,並利用鼠標鍵盤完成跨應用的長鏈路任務,有可能成為下一代操作系統的核心交互入口。
然而,要訓練出一個通用的 CUA,我們面臨着嚴峻的數據擴展(Data Scaling)瓶頸。當前主流的訓練範式依賴於對專家軌跡的模仿學習,但在將其推向工業級可用時,這種方式面臨着三大挑戰:
- 數據合成質量低: 真實的高質量軌跡數據極度稀缺且昂貴,而試圖用大模型直接生成數據往往會陷入"幻覺"。模型生成的指令或計劃經常看似合理,但在真實的 UI 狀態下根本不可執行。
- 缺乏交互反饋: 靜態數據模仿學習只能告訴模型"什麼是對的",卻無法告訴它"如果點偏了會發生什麼"。缺乏在大規模環境交互中產生的反饋,模型就無法捕捉操作與環境變化之間複雜的因果動態,難以適應真實環境中渲染差異、網絡延遲等隨機擾動。
- 長鏈路探索效率低:計算機操作往往涉及數十步甚至上百步的連續決策,無約束的探索空間巨大且低效。僅靠簡單的模仿學習,模型很難學會如何從中間的錯誤狀態中反思並糾錯。需要一種更高效和可擴展的範式,讓模型專注於從海量自身成功和失敗的經驗裏學習和進化。
面對上述挑戰,我們正式推出了 EvoCUA , 一種原生的計算機操作智能體模型。EvoCUA致力於構建一種進化範式,讓模型在大規模沙盒環境中,像生物進化一樣,通過不斷的試錯,反思和修正,積累海量成功和失敗經驗,進而不斷提升自身能力。
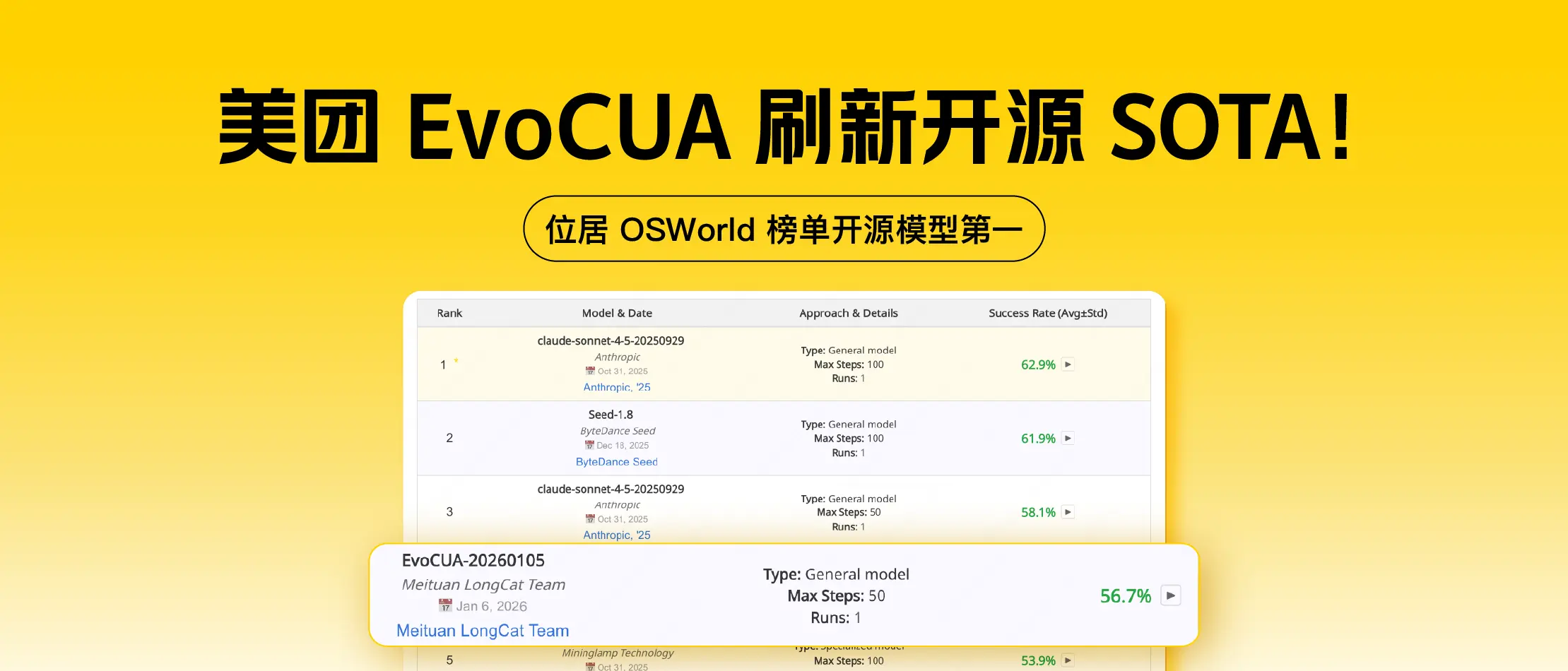
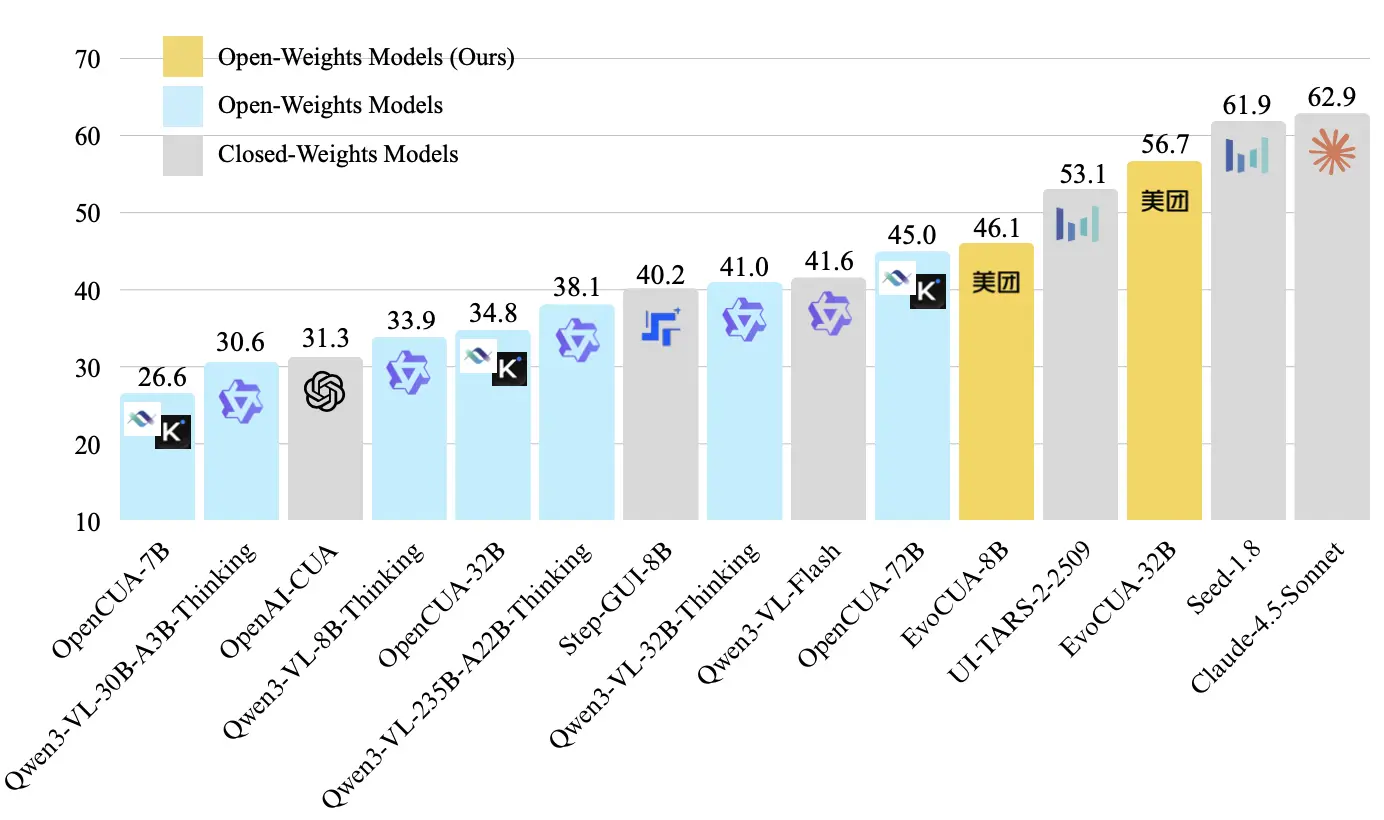
通過這一範式,EvoCUA-32B 在 Computer Use權威的在線評測基準 OSWorld 上取得了 56.7% 的成功率,刷新了開源模型的 SOTA 記錄,以更少的參數量和推理步數超過此前的開源SOTA OpenCUA-72B (45.0%),以及領先的閉源模型UI-TARS-2 (53.1%)。此外,實驗證實該方案的通用性,在不同基座(如 Qwen3-VL、OpenCUA)及多個尺寸(8B 至 72B)的模型上均能顯著提升 Computer Use 能力 。
模型上網查詢如何配置rbenv開發環境並幫用户安裝的示例:
02 核心技術架構
EvoCUA 的核心在於構建"交互-反饋-修正"的閉環。我們針對數據、環境、算法三個維度構建了自維持的進化架構:可驗證數據合成引擎 負責生產高質量任務,高併發交互基建 支持海量軌跡合成,基於經驗的迭代算法提供模型進化的關鍵路徑。
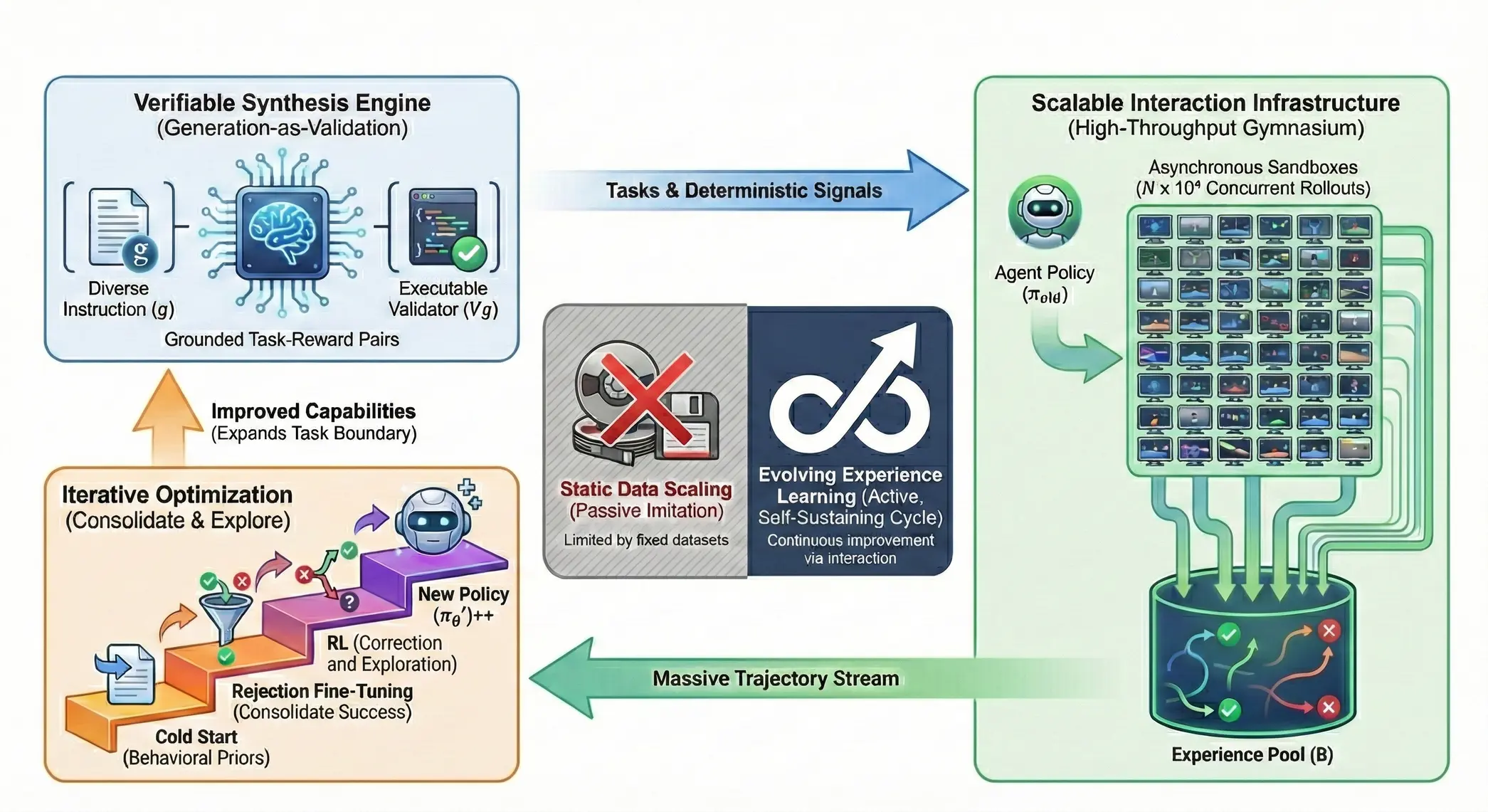
2.1 可驗證數據合成引擎
EvoCUA 數據層的核心任務是構建一個自動化流水線,能夠合成覆蓋各個垂直領域的高質量任務指令。我們要求合成數據要滿足兩個指標:
- 場景完備性:覆蓋從文檔辦公、Web 檢索到系統管理的全場景操作。
- 執行確定性:每一條數據必須在真實環境中可執行、可驗證,杜絕邏輯幻覺。
在實現這一目標時,我們發現業界通用的"大模型生成 + Reward Model (RM) 篩選"範式在 Computer Use 場景下存在本質缺陷:
- 語義與執行的割裂:傳統的 RM 基於語義匹配打分,只能判斷生成的指令在文本層面是否合理,無法驗證其在物理層面能否執行。
- Reward Hacking:模型傾向於生成邏輯通順但包含"幻覺"的指令(例如點擊不存在的 UI 元素)。這些不可執行的任務會引入大量訓練噪音,導致模型在真實操作中產生嚴重的錯誤累積。
為了解決數據可信度問題,我們提出了 "生成即驗證" 範式,在生成自然語言指令的同時,同步生成可執行的驗證代碼,並以沙盒中的實際運行結果作為判斷數據是否有效的唯一標準。
整體數據合成框架如下:
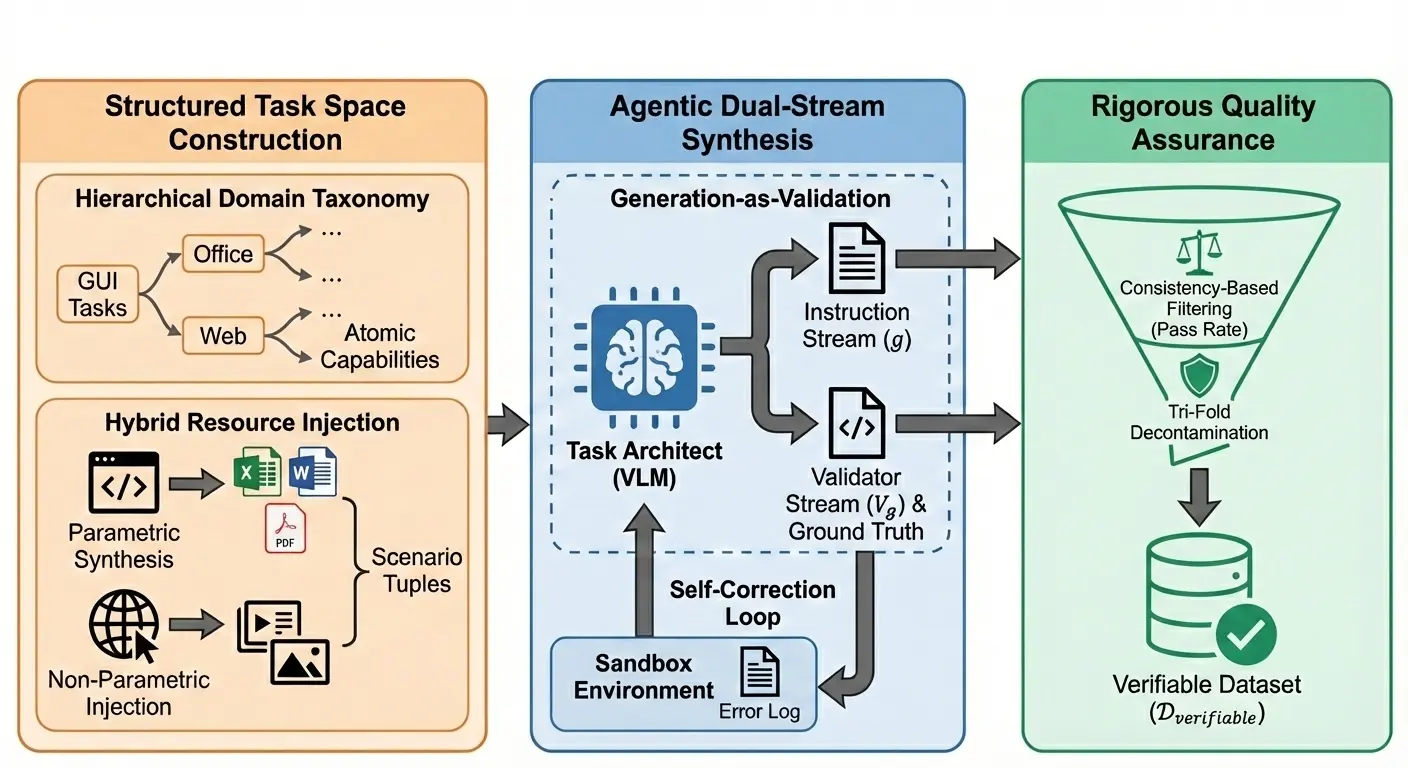
2.1.1 結構化任務空間構建
在構建任務空間時,我們並未盲目堆砌數據,而是基於對 GUI 操作本質的兩個核心洞見:
- 原子能力的可遷移性與泛化性:GUI 操作雖然千變萬化,但其底層的"原子技能"是跨域複用的。例如,"數據篩選"這一能力,無論是在 Excel、CRM 系統還是網頁後台中,其邏輯內核是同構的。
- 複雜任務的組合本質:真實世界中的複雜任務,本質上是由有限的原子能力通過特定邏輯編排而成的序列。掌握了原子能力的組合方式,就等於掌握了生成無限複雜任務的"語法"。
基於這兩點思考,我們採用分層構建策略來初始化任務環境。
- 原子能力拆解:我們將複雜的桌面操作任務解構為標準的原子能力單元。基於分層領域分類體系,例如將"Excel 財務分析"任務拆解為"公式計算"、"多列排序"、"透視表生成"等子技能。
- 資源文件合成 :為了模擬真實環境的複雜性,我們在環境初始化階段實施了兩種資源生成策略。
- 參數化合成:針對結構化數據(如銷售報表),我們利用代碼生成器批量生產 Word/Excel 文檔,隨機化其中的姓名、價格、日期等參數。
- 非參數化合成:針對非結構化數據,我們直接注入無版權問題的互聯網上的公開資源(如真實的圖片、音頻、複雜的 PPT 幻燈片),強迫 Agent 處理真實世界中不可預知的視覺噪聲和佈局多樣性。
2.1.2 指令和驗證器合成
我們構建了基於 ReAct 的 Agentic 數據合成工作流。當給定一個場景元組(角色、能力、資源)後,作為任務架構師的基礎 VLM 會啓動生成:
- 指令:生成符合用户意圖的自然語言指令,確保任務目標清晰且在當前資源環境下可達成。
- 驗證器:同步生成對應的可執行驗證Python驗證代碼以及標準答案(以文件/配置項等形式存在)。這段代碼定義了任務成功的精確條件(例如:檢查某個單元格的值是否為 X,或某個文件是否存在)。
不僅如此,我們還引入了沙盒執行反饋機制。生成的驗證代碼會立即在真實沙盒中運行。如果代碼報錯(如 API 錯誤、語法錯誤),錯誤日誌會被回傳給任務架構師進行自我修正。這個過程會迭代多輪,直到驗證器本身能夠成功運行並通過質量檢查。
2.1.3 質量保障與去污
為了確保入庫數據的純淨度,我們在數據落盤前設置了嚴格的過濾機制。
- 一致性過濾:我們部署了一個測試Agent模型對合成任務進行試跑。通過比對"沙盒實際執行結果"與"驗證器判定結果",我們能精準識別出假陽性(False Positives)數據------即任務其實沒做對,但驗證器誤判為成功的案例。只有那些經得起沙盒檢驗的數據才會被保留。
- 三重去污染 :用於合成數據的模型本身見過大量的預訓練語料包含大量世界知識,大規模構造合成數據時,有混入和 Benchmark 有一定相關性的數據的風險。為了防止測試集泄露,我們實施了三重去污策略:
- 語義去重:使用 LLM 過濾掉與 基準測試集在語義上高度相似的指令。
- 配置去重:剔除與測試集具有相同初始化設置(如完全一致的文件名或窗口布局)的任務。
- 驗證器去重:檢查生成的驗證邏輯和 Ground Truth 文件,確保沒有直接照搬測試腳本。
通過這套數據合成框架,我們成功將可驗證的訓練數據規模擴展到了數萬量級,突破了人工標註的瓶頸。
2.2 支撐十萬級沙盒併發的基礎設施
EvoCUA 的進化範式要求 Agent 進行大規模的探索來合成經驗軌跡。我們面臨的挑戰是工業級的:如何在一個集羣中穩定調度 100,000+ 個每日活躍沙盒,處理百萬級的分鐘交互請求,同時保證每個環境的嚴格隔離與毫秒級響應。為此,我們構建了一套統一的環境沙盒平台,在調度吞吐與環境保真度兩個維度做了大量優化。
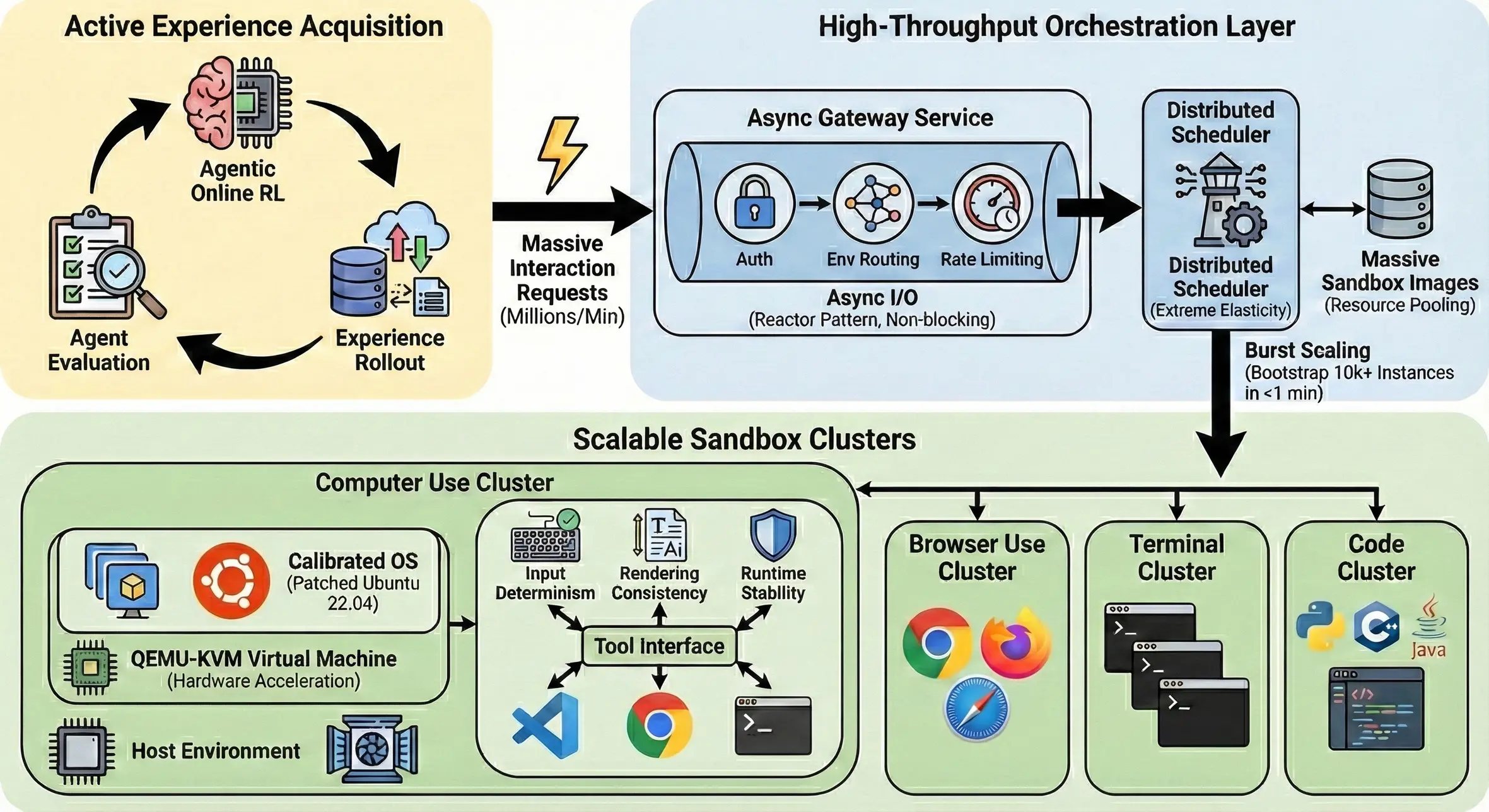
2.2.1 微服務化編排
為了消除大規模強化學習中的 I/O 瓶頸,我們將傳統的單體模擬器重構為基於微服務的異步架構。
異步 I/O 網關: 面對百萬級交互請求,傳統的阻塞式架構已無法支撐。我們採用了基於 Reactor 模式的異步非阻塞 I/O 設計網關架構,實現了 數百萬 QPM(Queries Per Minute)的路由吞吐能力,並且將控制面(生命週期管理)與數據面(環境交互流)徹底解耦,確保長週期的環境執行(如打開一個重型 App)不會阻塞關鍵的路由邏輯,極大地提升了系統的吞吐上限。
沙盒批量急速啓停: 強化學習的採樣階段具有極強的"脈衝"特性(短時間內需求激增)。我們的分佈式調度器通過分片與資源池化技術,實現了極速冷啓動能力。通過該優化,系統能夠在 1 分鐘內拉起 10,000+ 個沙盒實例。這種"即需即供"的彈性能力,確保了環境供給嚴格匹配訓練需求,最小化了策略更新與經驗採集之間的延時,保證了訓練的高效流轉。
2.2.2 保真環境構建
在解決了"量"的問題後,更關鍵的是"質"。Computer Use 任務對環境的確定性要求極高,微小的渲染差異或鍵位衝突都會導致模型訓練非最優。
-
混合虛擬化架構:為了兼顧容器編排的靈活性與虛擬機的強隔離性,我們採用了 Docker 容器嵌套 QEMU-KVM 的混合架構。
- 外層:使用 Docker 對接 K8s 調度體系,複用美團成熟的容器化運維能力。
- 內層:利用 KVM 硬件加速運行 QEMU 虛擬機。
- 價值:這種設計既提供了內核級的安全隔離(防止 Agent 執行惡意代碼穿透宿主機),又保證了接近原生的 GUI 渲染與 I/O 性能。
-
操作系統級校準:標準 OS 鏡像在自動化操作中存在諸多"隱形坑",導致仿真環境與真實世界存在 Gap。為此,我們深度定製了 Ubuntu 22.04 鏡像,實施了內核與用户態的雙重補丁:
- 輸入確定性: 標準虛擬化常存在鍵位映射衝突(例如 US 鍵盤佈局下
Shift+<狀態丟失)。我們深入內核層修改了xkb的符號定義,確保 Agent 的符號意圖與實際輸入嚴格一致。 - 渲染一致性: 視覺 Agent 對字體佈局極其敏感。我們在系統層注入了全套專有字體庫並強制刷新
fc-cache,消除了文檔在仿真環境與真實環境下的視覺渲染差異,防止模型因環境噪音而產生錯誤的視覺關聯。
- 輸入確定性: 標準虛擬化常存在鍵位映射衝突(例如 US 鍵盤佈局下
2.3 基於經驗的學習範式
有了可驗證的數據和高吞吐的環境,我們的核心目標是如何讓模型像人類一樣學習:要在大量的自我實踐中鞏固成功經驗,並從失敗中吸取教訓。然而,單純依賴靜態數據的監督微調存在兩個本質缺陷:
- 分佈偏移:訓練數據的分佈往往是"完美路徑",而推理時的環境充滿了隨機性。模型一旦偏離了專家軌跡,就不知道如何回到正軌。
- 負反饋缺失:SFT 只能告訴模型"怎麼做是對的",卻從未告訴它"怎麼做是錯的"以及"錯在哪裏"。
EvoCUA 提出了一種漸進式的進化範式,將訓練過程解耦為三個階段:冷啓動(注入先驗思維模式)、拒絕採樣微調(動態算力分配,鞏固成功經驗)、強化學習(聚焦關鍵出錯點,從失敗經驗中學習)。
2.3.1 Cold Start: 冷啓動
在讓 Agent 進入大規模環境進行自由探索之前,給模型注入一些思維pattern,能夠提高模型的有效探索能力。為了摸清當前 Agent 能力的邊界,我們深入分析了 Qwen3-VL-Thinking、OpenCUA-72B 等主流模型推理軌跡。我們發現,各家模型均有一定缺陷。例如:OpenCUA-72B 很容易提前誤判成功,而Qwen3-VL模型在動作空間上存在一些明顯缺失(如不支持Shift+Click)。基於此,EvoCUA 在冷啓動階段的核心任務,是定義一套完備的動作空間與嚴謹的思維範式。
- 完備的動作空間 :處理複雜操作,如 Excel 中的
Shift + Click。如果是原子的press操作,無法表達這種持續按壓的狀態。為此,我們將按鍵拆分為key_down和key_up。 - 結構化思維鏈 :為了避免"幻覺"和"偽成功",我們給模型注入了一些像人類一樣的優秀思維範式:
- 目標澄清:在初始時刻,強制模型複述並拆解用户意圖,消除指令歧義。
- 觀測一致性:簡短且精準,嚴格對齊當前的視覺元素,防止"看圖説話"時的幻覺。
- 自我驗證 :在發出
Terminate信號前,模型必須執行顯式的檢查步驟。例如在發完郵件後,進入"已發送"文件夾確認,而非盲目自信。 - 反思與糾錯:針對採集到的失敗軌跡,我們識別出狀態偏離的關鍵分岔點,從錯誤發生後的那一步恢復環境狀態,通過 Prompt 引導和高温採樣讓模型自我修正。
- 終止判斷 :
Terminate動作必須強依賴於前序的 CoT 論證。如果思維鏈中沒有明確的完成證據,模型不得輸出結束信號,以此抑制"偽成功"。
- 後見之明數據合成:在訓練數據構造上,我們不直接使用模型的原始 CoT。對於成功軌跡,我們採用"後見之明"策略------基於正確的 Action 序列反向重寫邏輯嚴密的思維鏈;同時混入不可完成任務,教會模型識別環境邊界,學會説"No"。
經過冷啓動訓練後,模型展現出了明顯的行為範式轉變。它不僅掌握了終端和複雜快捷鍵的操作,更重要的是學會了"慢思考"------在關鍵節點進行校驗和反思。這為後續的大規模進化提供了堅實的原子能力基礎。
2.3.2 RFT:拒絕採樣微調
冷啓動賦予了模型基礎的原子能力,接下來的挑戰是如何在萬級 Query 上進行 Scaling。我們面臨的核心權衡是:如何在有限的算力預算下,最大化高質量經驗的產出效率與信噪比?如果對所有任務平均用力,會導致簡單任務算力浪費,而困難任務探索不足。為此,EvoCUA 設計了一套"階梯式動態算力分配 + 步級別去噪"的拒絕採樣微調策略。
階梯式動態算力分配:為了最大化探索的 ROI,我們將 Query 池劃分為不同難度層級,並實施階梯式的 Rollout 策略。我們將採樣次數 K 劃分為多個檔位 {3, 8, 16, 32, 64},併為每個檔位設定了成功率閾值(如 100%, 75%, 50%...):
- 自適應爬坡:模型從低 K 檔位開始嘗試。如果在當前檔位的成功率達到了預設閾值(説明模型已掌握),則立即停止採樣;反之,若成功率較低,則自動升級到下一檔位,投入更飽和的算力進行攻堅。
- 邊界突破:這種機制確保了算力被集中投放到模型處於能力邊界的困難任務上,而非在已熟練的任務上重複"造輪子"。
步級去噪:模型生成的原始軌跡即使成功了,也往往包含大量噪聲(如無效的鼠標滑動)。直接學習這些數據會污染模型。我們實施了精細化的清洗策略:
- 冗餘和錯誤步驟過濾:利用 Judge Model 分析成功軌跡,識別並掉對最終結果無貢獻的冗餘步驟,顯著提升了數據的信噪比。
- Infeasible 任務特判 :針對不可完成的任務,成功的軌跡往往伴隨着大量的無效嘗試後才終止。對於這類數據,我們僅保留最後一步(即正確輸出
Terminate=Failure及對應的推理),將中間所有的試錯步驟全部剔除。
通過 RFT,我們將大規模的合成經驗內化為模型參數,顯著提升了模型在常規路徑的執行成功率。
2.3.3 RL:強化學習
RFT 夯實了模型在常規路徑上的執行成功率,但面對長鏈路任務中的環境擾動(如彈窗、網絡延遲、佈局微變),模型依然脆弱。相比於成功軌跡中模型已有的知識,失敗軌跡中藴含着廣闊的、非線性的樹狀結構信息,模型往往會在一些關鍵步驟出錯,正是模型能力邊界的直接體現。
傳統的 RL 算法通常以整條軌跡為粒度,存在嚴重的信用分配難題------幾十步的操作中可能只有一步是錯的,全盤否定會導致有效經驗被浪費。
為了解決這一問題,我們提出了一種面向Computer Use的高效DPO算法,將優化粒度從"軌跡級"下鑽到"關鍵分岔點" , 重點解決模型在出錯邊緣的能力邊界感知問題。
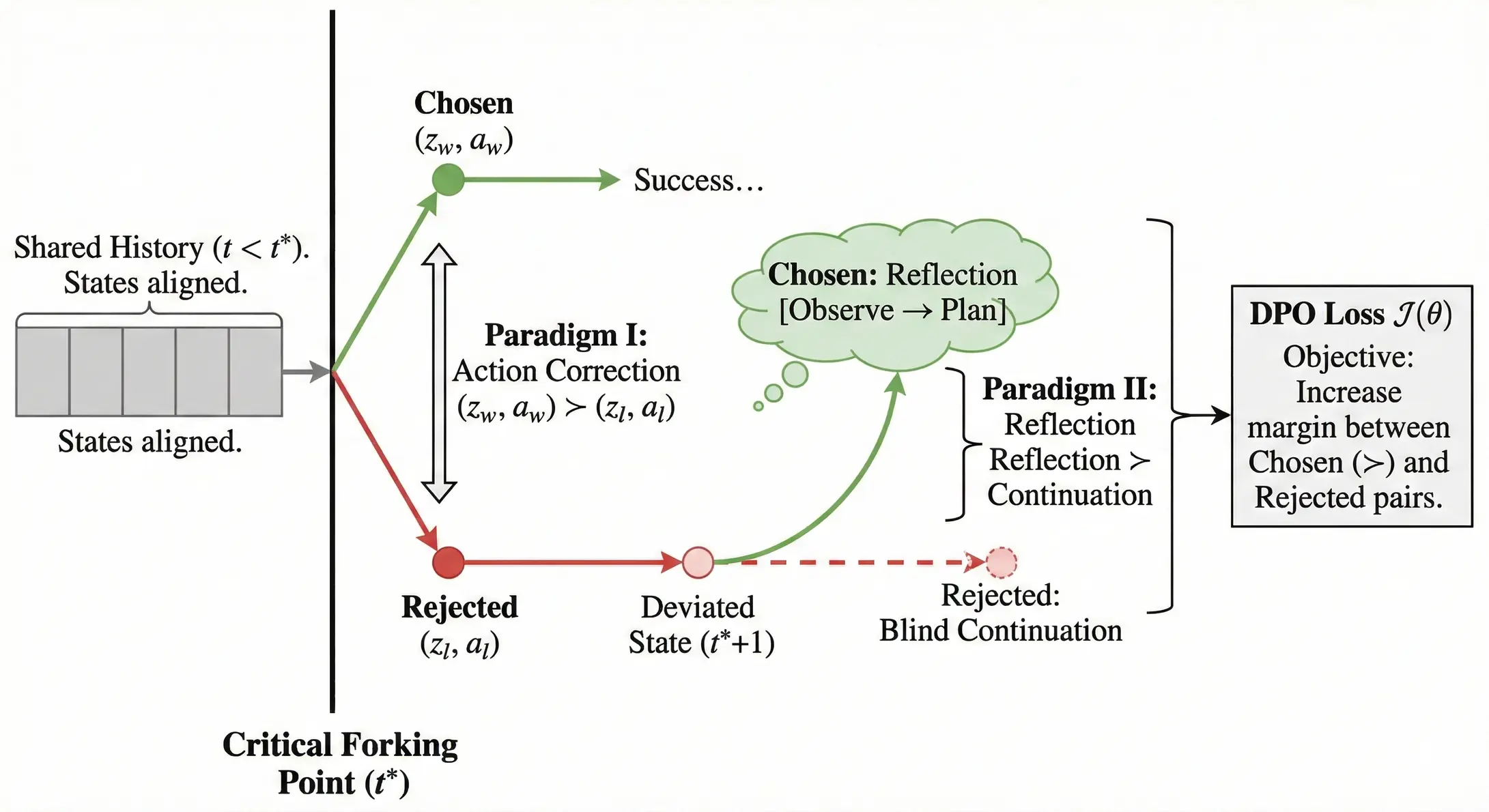
關鍵分岔點挖掘:在長達數十步甚至上百步的 GUI 操作中,任務失敗往往具有滯後性。模型可能在第 5 步做出了一個微小的錯誤決策(如選錯了篩選條件),但直到第 30 步才因為找不到目標文件而報錯。為了精準定位錯誤,EvoCUA 提出了一種基於參考導向的歸因機制------關鍵分岔點挖掘。 我們利用同一 Query 下的"成功軌跡"與"失敗軌跡"進行對齊分析。系統會自動定位到狀態一致但動作開始偏離的那一幀,記為關鍵分岔點。
雙範式偏好對構建:一旦通過因果診斷鎖定了關鍵錯誤,我們並未止步於簡單的行為克隆,而是針對出錯瞬間"和"出錯之後"兩個不同的時空切片 , 構造了兩種截然不同的 DPO 偏好範式,從而在一次訓練中同時兼顧了準確性與魯棒性。
- 範式一:動作修正,此範式聚焦於"即時糾錯",旨在教模型在關鍵分岔點(t時刻)必須"走正道"。我們將導致後續失敗的原始錯誤動作作為負樣本;對於正樣本,我們優先嚐試通過 VLM 語義匹配,將成功參考軌跡中的"正確思考與動作"遷移過來。如果參考軌跡無法對齊,則調用VLMs模型基於當前視覺狀態合成全新的正確動作。
- 範式二:反思與恢復,此範式聚焦於"錯誤恢復",旨在提升模型在錯誤發生後(t+1 時刻)的反思修正能力。在這一時刻,環境狀態通常已經因為前一步的錯誤而發生了偏離(如出現了預料之外的彈窗)。我們把模型無視環境變化、機械執行原計劃的"盲目繼續"行為標記為負樣本;同時,利用 Prompt工程引導模型生成一條"反思鏈"作為正樣本------即教導模型在發現狀態異常時,優先選擇停下來,觀察屏幕異常並重新規劃,而不是一條道走到黑。
通過這兩個範式的結合,模型不僅教會了 Agent 如何做對,更教會了它在做錯或環境突變時如何反思修正。隨着能力的不斷提升,上述RFT和DPO可以進行多輪迭代訓練。
除了DPO,我們在實踐中還探索了online RL,通過主動的環境交互,模型表現出了持續的獎勵增長趨勢,會在下一個版本的模型中更新。
總而言之,我們通過"雙重機制"將海量的合成經驗高效內化為模型參數:一方面利用 RFT 來夯實基礎的執行範式,確保模型在標準任務上的發揮穩定;另一方面利用 RL在複雜的長尾場景中主動糾錯,顯著提升模型在能力邊界上的魯棒性與泛化力。
03 實驗評估
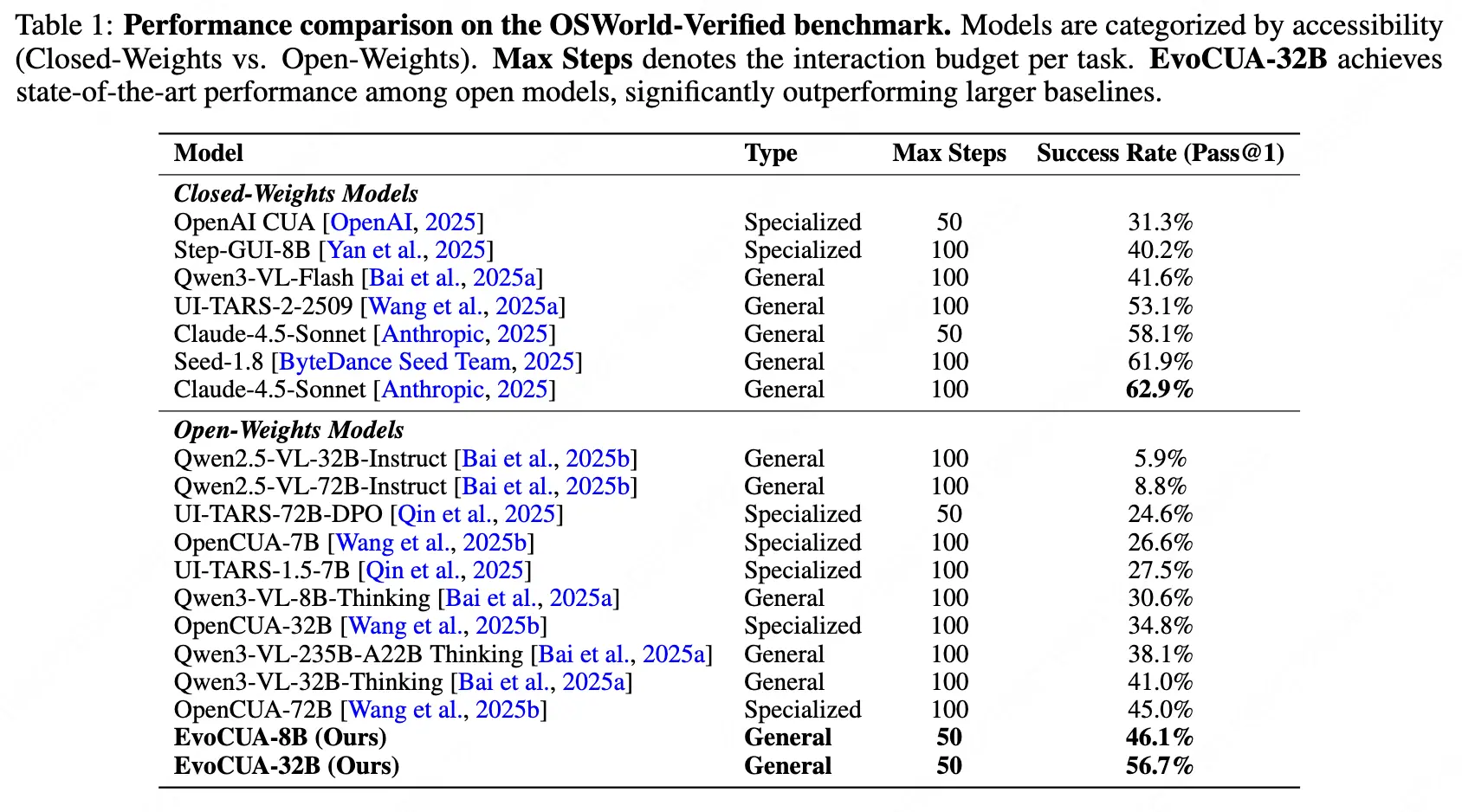
為了驗證 EvoCUA 範式的有效性,我們在權威在線榜單OSWorld上進行評測。實驗的核心結論如下:EvoCUA-32B 以 56.7% 的成功率刷新了開源模型 SOTA,並在同等推理預算(max step=50)下逼近了閉源模型 Claude-4.5-Sonnet (58.1%) 的水平;同時驗證了該進化範式在不同規模模型上的普適性。
3.1 OSWorld 評測
- 開源SOTA:我們的主力模型 EvoCUA-32B(基於 Qwen3-VL-32B-Thinking 後訓練)達到了 56.7% 的成功率。這一成績大幅領先此前的開源 SOTA(OpenCUA-72B, 45.0%)。值得注意的是,EvoCUA-32B 超越了閉源強基線 UI-TARS-2-2509 (53.1%)。在嚴格限制 50 步 推理預算的同等條件下,我們與行業頂尖的 Claude-4.5-Sonnet (58.1%) 差距縮小至僅 1.4%。
- 小參數大潛力:EvoCUA-8B 同樣表現驚豔,以 46.1% 的成功率擊敗了 OpenCUA-72B。與同樣基於Qwen3-VL-8B訓練的Step-GUI-8B (40.2%) 相比,EvoCUA-8B 取得了 +5.9% 的顯著優勢。
3.2 消融實驗
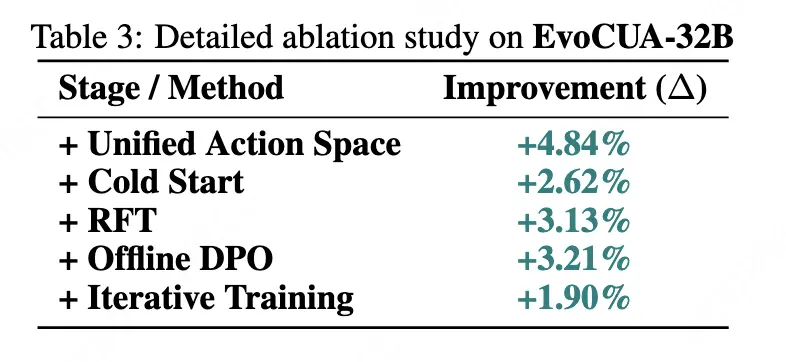
為了探究 EvoCUA 性能提升的來源,我們進行了逐層拆解的消融實驗。
- 統一動作空間 (+4.84%):通過完善動作空間帶來的提升。
- 冷啓動(+2.62%):注入高質量的行為先驗,確立了思維與行動的對齊。
- RFT 拒絕採樣(+3.13%):通過動態算力鞏固成功經驗,在不損失pass@k能力基礎上,提升模型的pass@1能力。
- Offline DPO(+3.21%):針對關鍵分岔點的糾錯訓練,顯著提升了模型魯棒性。
- 迭代訓練(+1.90%):再進行一輪迭代訓練,性能持續增長。
3.3 Scaling分析
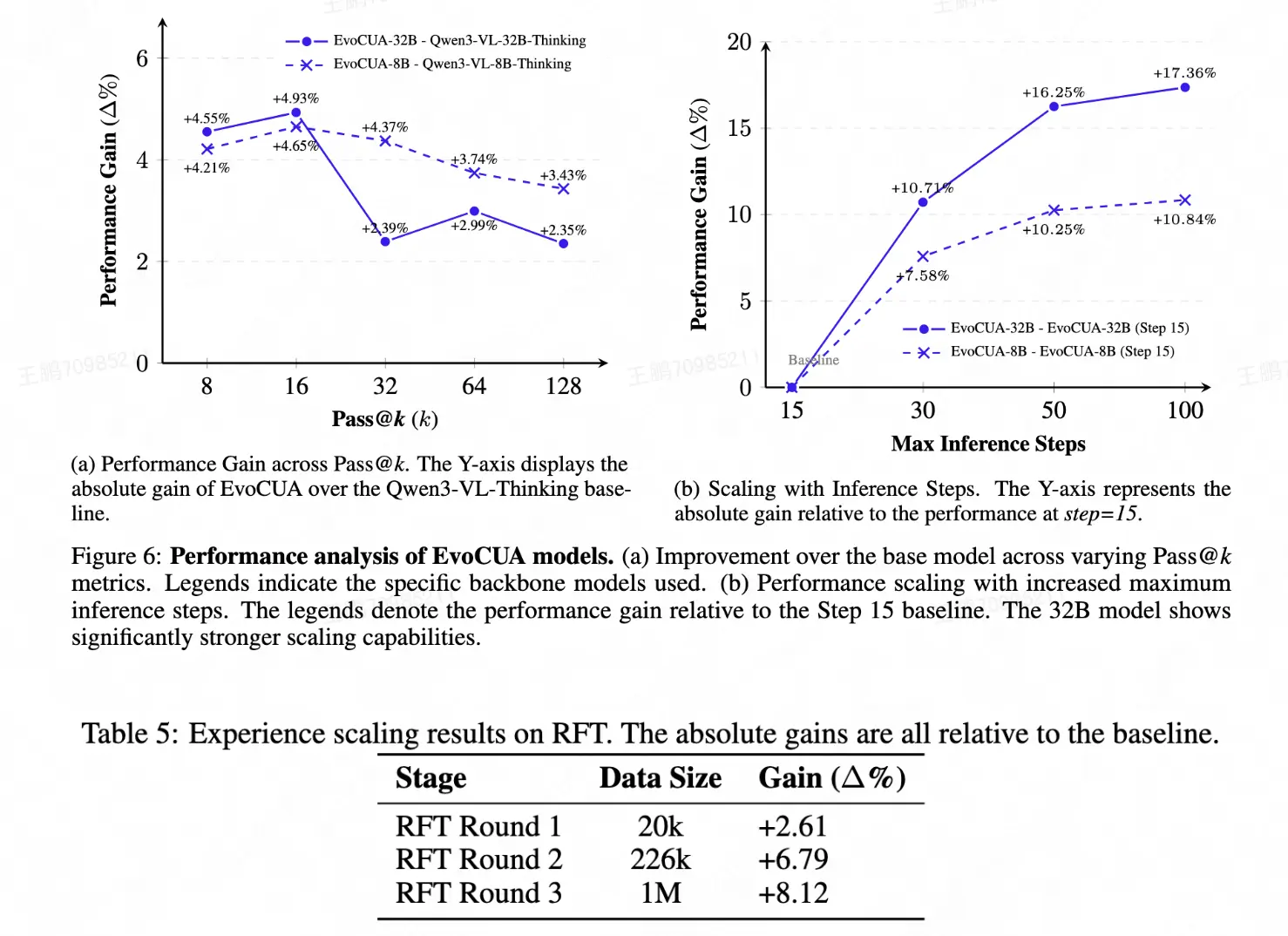
我們進一步驗證了 EvoCUA 的 Scaling Law。
- Max Step:隨着推理時步數的增加,我們觀察到模型的性能在不斷提升。但由於我們數據中超過50步的樣本較少,因此大於50步的邊際收益收窄。
- Pass@k:隨着採樣次數k的增加,EvoCUA 始終保持對初始化模型的顯著優勢。這表明優化後的 Policy 具有更高的天花板。
- 數據規模:在 RFT 階段,我們將數據量從 20k 擴展到 1M,觀察到了持續的性能爬坡。
3.4 軌跡可視化分析
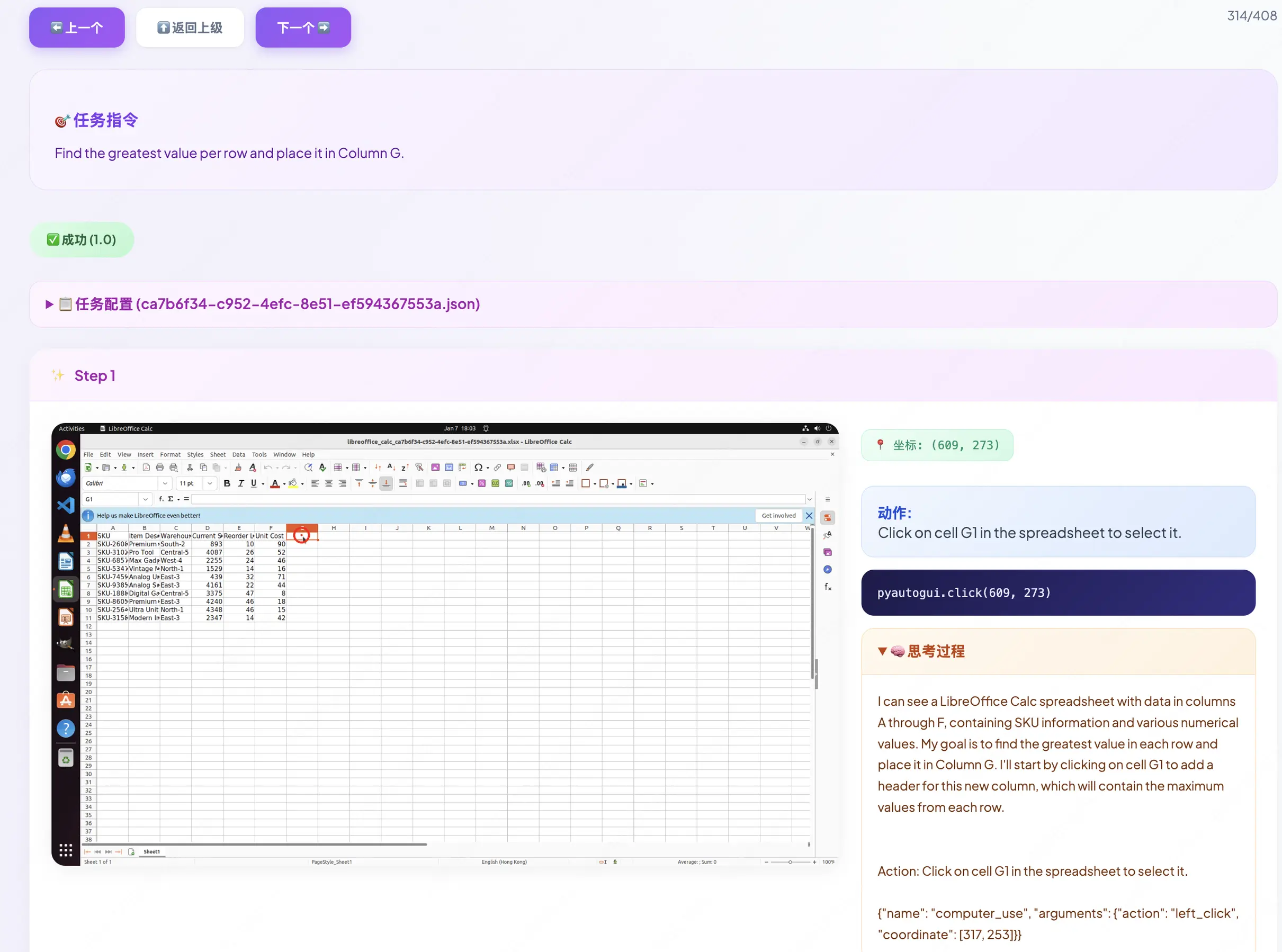
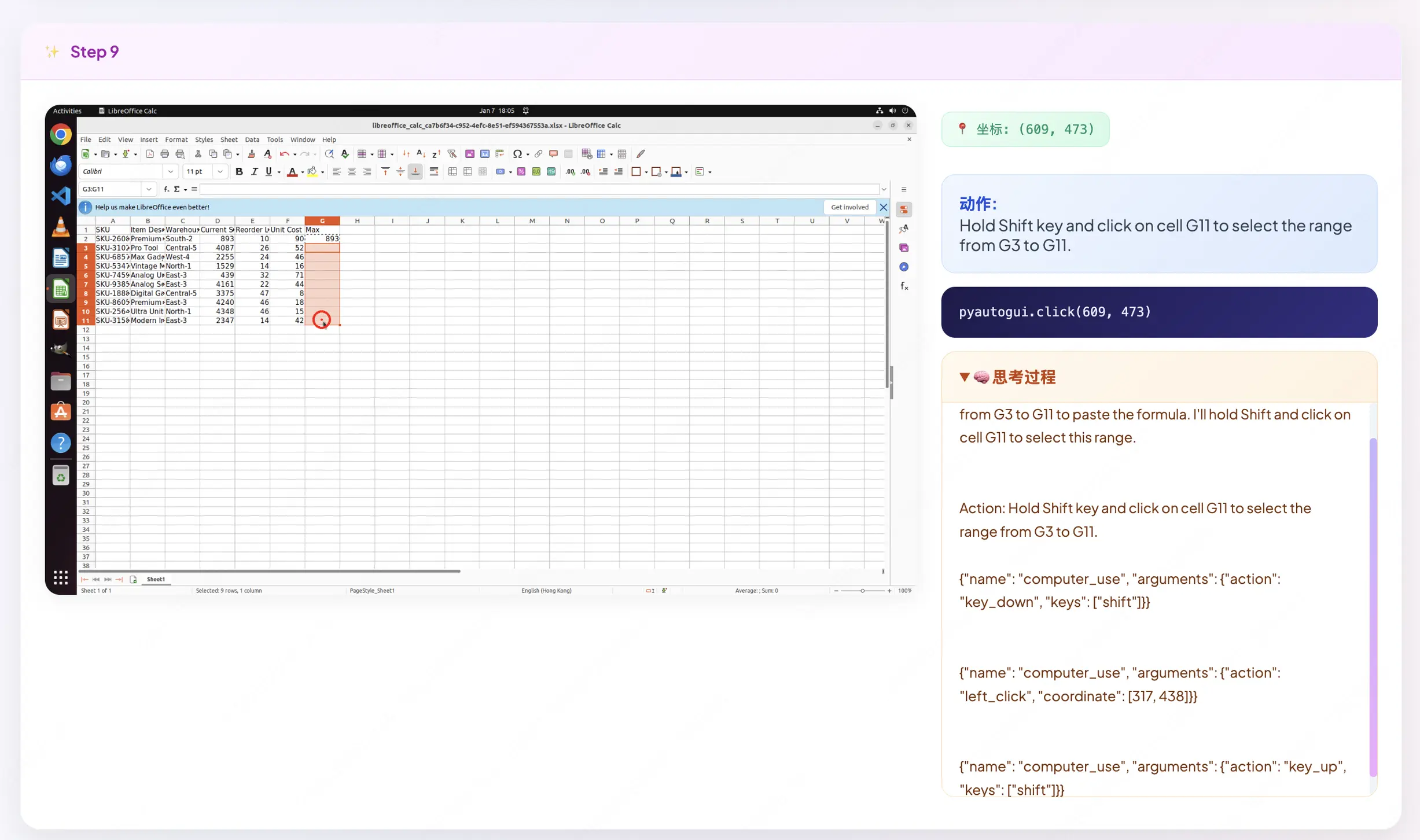
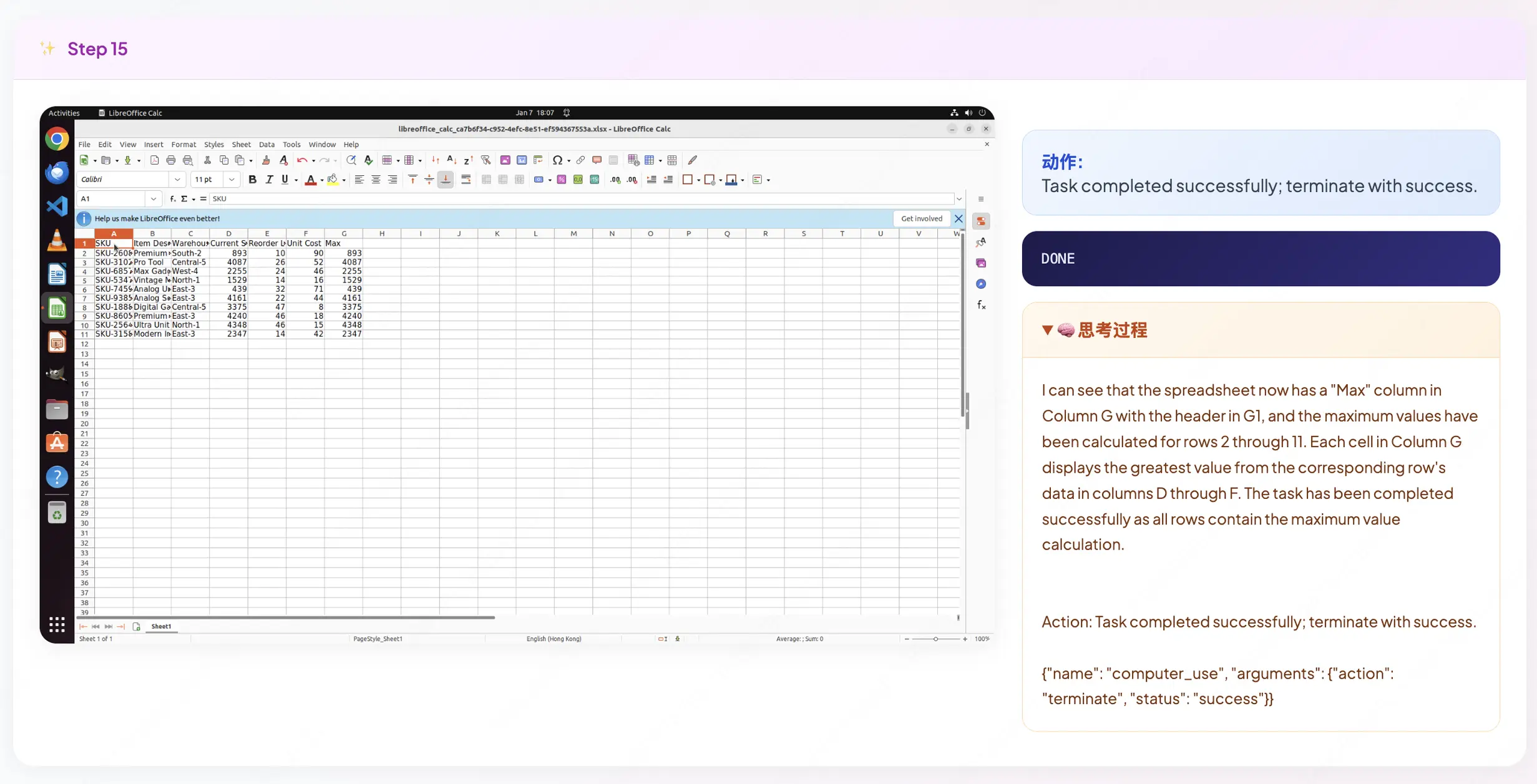
我們隨機抽樣一條合成指令任務,對訓練後的模型採樣軌跡進行可視化。以一個電子表格任務為例:"找出每行的最大值並填入 G 列",以下是EvoCUA-32B在四個關鍵時刻的思考與執行過程:
Step 1:目標澄清,智能體顯式複述並拆解了用户指令。
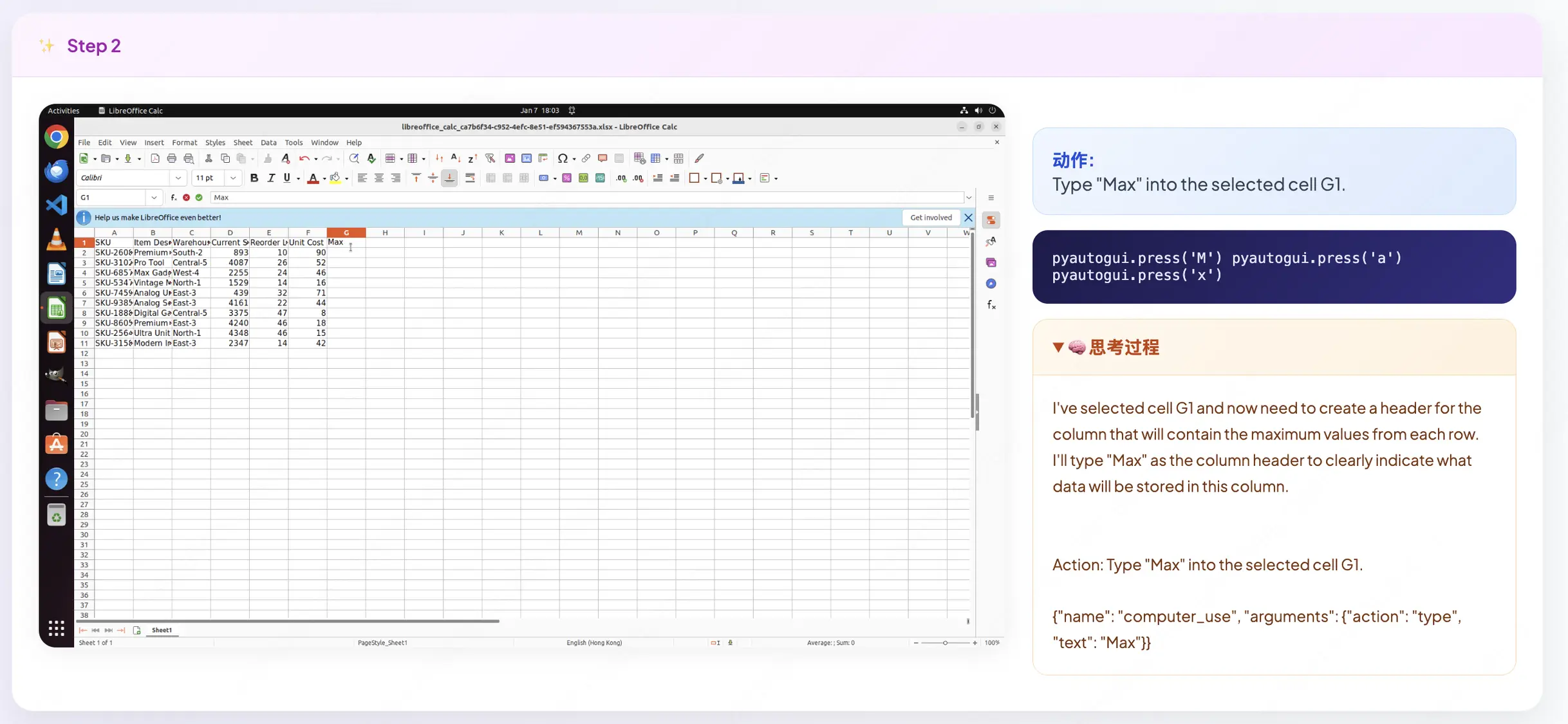
Step2:智能體使用excel公式原子能力Max操作。
Step 9:有狀態鼠標交互,專業軟件操作常涉及"按住並點擊"等組合動作。智能體執行"Shift+點擊"操作以選中 G3 到 G11 的數據範圍。
Step 15 :審慎終止判斷,智能體沒有盲目停止,而是先生成視覺證據:"我看到 Max 列已計算完畢..."。只有在視覺核驗結果符合初始指令後,它才發出terminate信號,確保任務完成。
04 總結展望
EvoCUA ,一個基於經驗進化範式的原生 Computer Use Agent。通過可驗證的合成引擎、可擴展的交互基建和可進化的經驗學習算法,我們探索出一條提升Computer Use能力的通用方法。在 OSWorld 基準測試中,EvoCUA 以 56.7% 的成功率刷新了開源模型的 SOTA,證明了這條路徑的有效性。在超過 100 萬卡時的上千組實驗中,我們總結了四條關鍵的洞察,希望能為社區提供參考:
- 高信噪比數據是關鍵: 成功軌跡是低噪聲但低信息量的,失敗軌跡是高噪聲但高信息量的。如何處理好數據,保證較高的信噪比是模型能力持續提升的關鍵。
- 先驗 Pattern 重於數據量:冷啓動階段,Pattern 的多樣性遠比數據量重要。一個輕量級但覆蓋全原子能力的冷啓動,比大量低質量數據的 SFT 更能為後續的 RL 打好基礎。
- On-Policy 的重要性:在長鏈路任務優化中,要嚴格使用 On-Policy 數據。一旦過度使用 Off-Policy 數據,會導致優化方向偏離原始模型主分量,且較難恢復。
- 可視化驅動的迭代:數據和算法之外,我們開發了大量用於軌跡可視化和 Debug 的分析工具,一套全流程可視化診斷工具對於數據質量校驗、軌跡對比分析和問題發現至關重要。
儘管取得了階段性突破,我們必須承認,當前開源模型與頂尖閉源系統(及人類水平)之間仍存在顯著差距。這一差距揭示了單純依賴離線合成軌跡的性能天花板。我們認為,打破這一瓶頸的關鍵在於在線強化學習。我們初步的實驗信號顯示,通過主動的環境交互,模型表現出了持續的獎勵增長趨勢。未來的工作將聚焦於系統性地拓展這一在線進化邊界,最終實現完全自主的計算機操作能力。
目前,EvoCUA 現已全面開源,歡迎訪問項目主頁獲取更多信息:
- Github : https://github.com/meituan/EvoCUA
- Huggingface :EvoCUA-32B、EvoCUA-8B
- Technical Report :PDF
| 關注「美團技術團隊」微信公眾號,閲讀更多技術乾貨!

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明"內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
