印度 169PI 公司最近發佈的 Alpie 大模型被稱為印度版的DeepSeek,目前已經開源在多個平台,並開放了API。
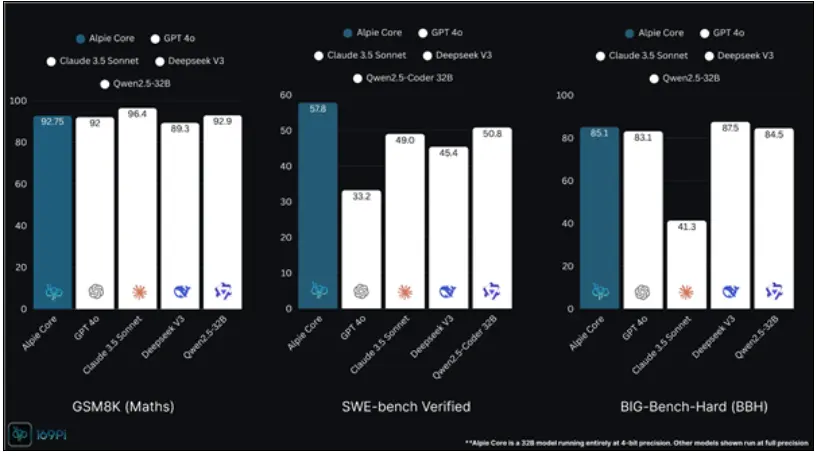
這款模型只是一個320億參數的小模型,主打4bit量化,但AI榜單上表現非常強,GSM8K數學榜單上超過了DeepSeek V3,跟GPT-4o、Qwen 2.5-30B一個檔次,略低於Cluade 3.5。
在SWE軟件工程榜單上則力壓其他大模型,包括Claude 3.5等,表現非常強。BBH榜單上也超過了GPT-4o、Qwen 2.5、Calude 3.5等大模型,略低於DeepSeek V3。
不過 Alpie 的爭議也不少,因為它其實不是印度工程師自己訓練出來的大模型,而是DeepSeek-R1-Distill-Qwen-32B二次深度開發的,是中國開源大模型基礎上蒸餾+量化出來的。
這樣做的好處不少,比如大幅降低了成本,只有GPT-4o的1/10,顯存佔用降低了75%,16-24GB的顯卡就能流暢運行。
