Hugging Face 發佈了一篇名為 “DeepSeek 時刻” 一週年 的文章,回顧過去一年中國開源 AI 社區發生的歷史性轉折,並分析這些變化如何重塑整個全球開源生態系統。此係列文章共 3 篇,本文是第一篇。
文章指出,許多 2025 年的重要進展,都可以追溯到一個起點:2025 年 1 月的 “DeepSeek 時刻”。當時,總部位於杭州的人工智能公司深度求索(DeepSeek)發佈了其開源推理模型 DeepSeek R1,這一事件迅速成為中國乃至全球開源人工智能生態的重要分水嶺。
對於依賴和貢獻開源生態的 AI 研究者與工程師,以及試圖理解這一在快速變化環境的政策制定者而言,過去一年所呈現的信號非常明確,即現在正是構建和發佈開源模型與技術的最佳窗口期。值得注意的是,地緣政治因素在很大程度上推動了開源模型的採用;儘管整個 2025 年中,中國開發的模型在各項指標上持續佔據主導地位,新進入者也不斷實現跨越式發展,但西方 AI 社區正在積極尋找可用於商業部署的替代方案。
中國本土開源 AI 生態的起源
在 R1 發佈之前,中國的人工智能產業在很大程度上仍以閉源模型為中心。開源模型雖然已經存在多年,但主要侷限於研究社區,或僅在諸如隱私敏感應用等小眾場景中使用。對大多數公司而言,開源並不是默認選擇。算力資源相對緊張的情況下,“開源還是閉源”始終是一個被反覆討論的問題。
DeepSeek 的 R1 模型降低了獲取先進模型能力的門檻,並提供了一種清晰、可供效仿的發展範式,從而解鎖了新的發展層級。更重要的是,這次發佈為中國 人工智能的發展帶來了一樣極其寶貴的東西:時間。即使在資源有限的情況下,依然可以通過開源與快速迭代實現快速進步。這一路徑與中國在 2017 年提出的 “AI+” 戰略目標契合:儘可能早地將人工智能與產業相結合,同時在長期持續推進算力能力的建設。
R1 發佈一年後,我們看到的不僅是一批新模型,還有一個正在成長的原生開源生態系統。
DeepSeek R1:一個轉折點
這是中國的開源模型首次進入全球主流榜單,並且在隨後的一年中,每當有新模型發佈時,它都反覆被用作重要的參考基準。DeepSeek R1 很快成為 Hugging Face 有史以來獲贊最多的模型,而獲贊最高的模型中,也不再以美國開發的模型為主。
然而,R1 的真正意義並不在於它在當時是否是最強的模型,它的重要性在於:它是如何同時降低了三個關鍵門檻。
首先是技術門檻。R1 通過公開其推理路徑和後訓練方法,將此前被封裝在閉源 API 背後的高級推理能力,轉變為一種可下載、可蒸餾、可微調的工程資產。許多團隊因此不再需要從零開始訓練龐大的模型,也能夠獲得強大的推理能力。推理開始變得像一個可複用的模塊,被反覆應用於不同的系統之中。這一變化也促使整個行業重新思考模型能力與算力成本之間的關係,而這種轉變在像中國這樣算力受限的環境中尤為重要。
其次是應用門檻。R1 以 MIT 許可證發佈,使其在使用、修改和再分發方面都變得非常直接。此前依賴閉源模型的公司開始將 R1 直接引入生產環境。蒸餾、二次訓練以及面向特定領域的適配,逐漸演變為常規的工程工作,而不再是需要單獨立項的特殊項目。隨着分發限制的消失,模型迅速擴展到各類雲平台和工具鏈之中,社區討論的重心也從 “哪個模型得分更高”,轉向 “如何部署、如何降低成本、以及如何將其集成到真實系統中”。隨着時間推移,R1 超越了研究製品的範疇,成為一個可複用的工程基礎設施。
最後是心理門檻。當問題從 “我們能不能做到?” 變成 “我們如何把這件事做好?”時,許多公司的決策邏輯隨之發生了變化。對於中國人工智能社區而言,這同樣是一個難得的、持續受到全球關注的時刻。對於一個長期被視為 “追隨者” 的生態系統來説,這種關注具有深遠意義。
這三個門檻的同步降低,共同意味着:整個生態系統開始具備自我複製和自我擴張的能力。
從 DeepSeek 到 AI+:戰略重組
一旦開源成為主流,一個自然的問題隨之而來:中國公司的戰略將如何變化?在過去一年中,答案變得清晰:競爭開始從模型之間的比拼轉向系統級能力的較量。
與 2024 年相比,R1 發佈之後,中國的人工智能格局逐步形成了一種新的態勢:大型科技公司率先行動,初創公司迅速跟進,來自垂直行業的公司也越來越多地進入這一領域。儘管各自路徑不同,但一種共同的認知正在逐步形成,尤其是在頭部玩家之間:開源已不再是短期戰術,而是長期競爭戰略的一部分。
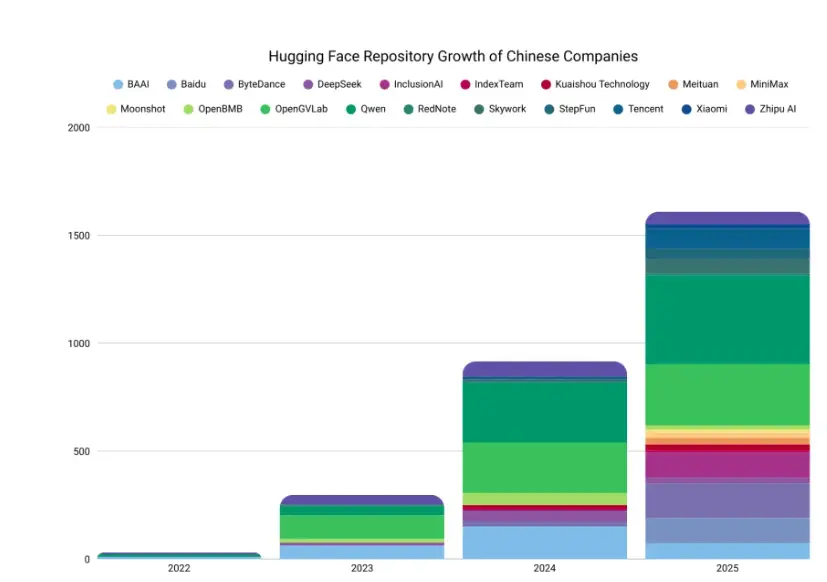
中國公司在 Hugging Face 的模型倉庫增長圖
中國發布最先進模型和代碼庫的組織數量迅速增長。這一趨勢清晰地反映在_中國公司在 Hugging Face 的模型倉庫增長圖 _中:既有巨頭的開源發佈數量大幅上升,其中百度在 2024 年於 Hugging Face 上尚無任何發佈,而到 2025 年已超過 100 個;字節跳動、騰訊等公司也將其發佈數量提升了 8 到 9 倍。與此同時,大量新近轉向開源的組織涌入,發佈了性能極高的模型,其中月之暗面的開源發佈 Kimi K2 被稱為“又一個 DeepSeek 時刻”。
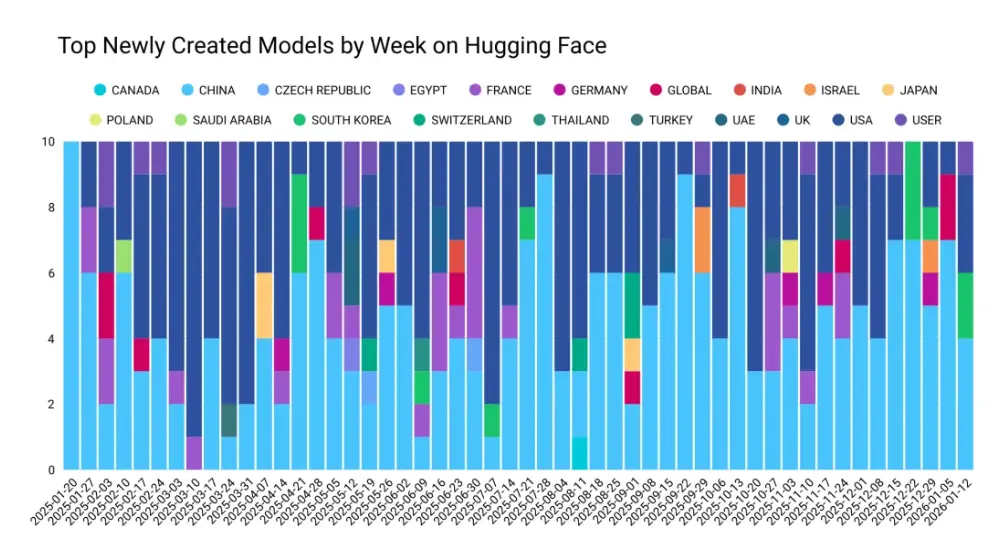
Hugging Face 每週新創建模型統計
模型發佈不僅變得更強,也變得更加頻繁。高性能模型幾乎以每週為節奏持續推出。新創建的中國模型在每一週中都穩定地成為獲贊最多、下載量最高的模型,在 Hugging Face 下載量最高的新模型中始終保持着最高的人氣。Hugging Face 的 每週新創建模型統計 圖中展示了這些新模型倉庫,並根據組織所在地或熱門衍生模型所基於的底座模型組織所在地進行了標註。
中國開源熱力圖
正如 Hugging Face 中國開源熱力圖所顯示,在 2025 年 2 月至 7 月 期間,中國公司發佈開源項目的活躍度明顯提升。其中百度和月之暗面開始從以閉源為主的路徑,轉向更系統性的開源發佈。智譜的 GLM 以及阿里巴巴的通義千問 (Qwen) 更進一步,不再僅僅發佈模型權重,而是擴展到構建完整的工程系統和生態接口。
在這一階段,單純比較模型的原始性能已不足以取得優勢。競爭的焦點越來越集中在生態系統、應用場景以及基礎設施之上。
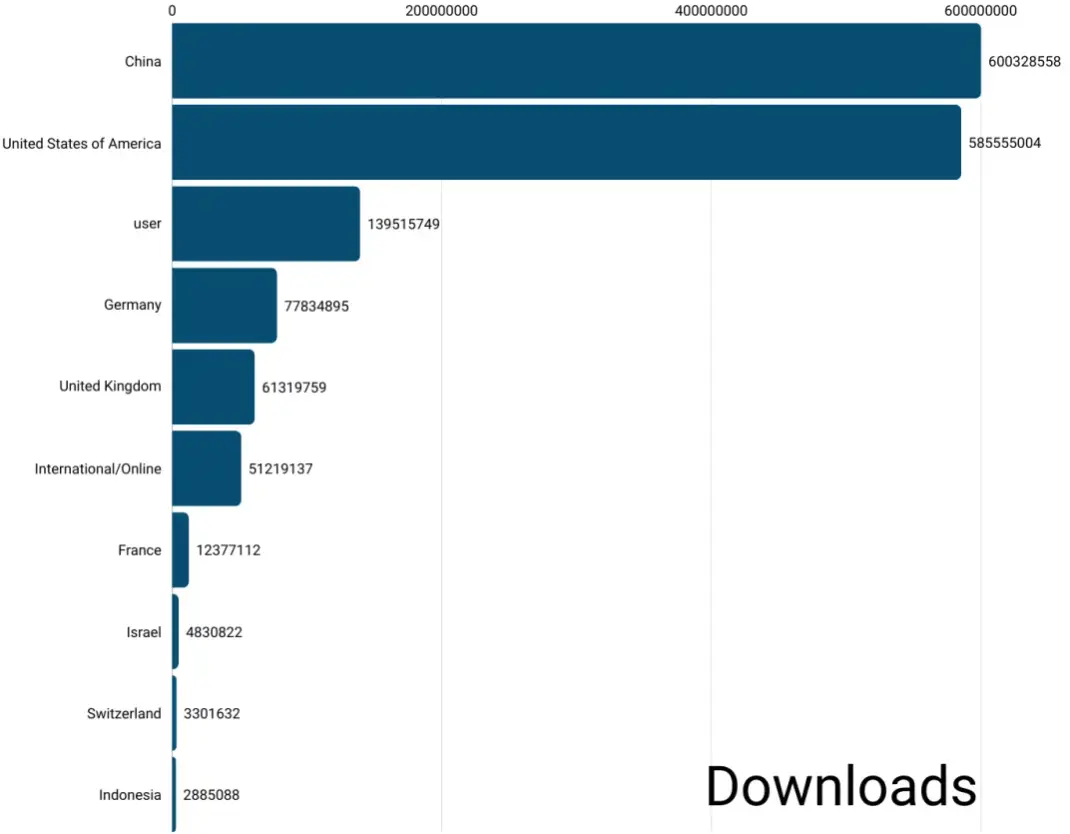
這一戰略已被事實證明是有效的:在所有新創建(發佈時間不足一年)的模型中,中國模型的下載量已經超過包括美國在內的任何其他國家。
中國的人工智能玩家並不是通過協議進行協同,而是在約束之下實現趨同。表面上看似合作的行為,更準確地説,是在共同的技術、經濟與監管壓力下形成的對齊。這並不意味着這些公司結成了合作聯盟;相反,在算力、成本和合規等相似約束條件下,它們開始沿着相近的技術基礎和工程路徑展開競爭。
當競爭發生在可比的系統結構之上時,生態系統便開始顯現出自我傳播與自我成長的能力。最近來自智譜 AI、月之暗面、阿里巴巴通義千問(Qwen)以及騰訊的技術領導者,就若干共性問題進行同台交流,這種現象在其他國家極為罕見。
全球的反響與應對
全球範圍內,對開源應用和發展的積極情緒有所增強,尤其是在美國,人們越來越廣泛地認識到:開源領導力對於提升全球競爭力至關重要。
DeepSeek 在全球市場獲得了廣泛採用,尤其是在東南亞和非洲地區。在這些市場中,多語言支持、開放權重的可用性以及成本因素,共同推動了企業級應用的落地。
西方組織在商業部署時,往往傾向於尋找非中國來源的模型。來自美國機構的重要發佈。例如 OpenAI 的 gpt-oss、AI2 的 Olmo 以及 Meta 的 Llama 4,都獲得了社區的廣泛關注。Reflection AI 也宣佈將致力於構建美國的前沿開放權重模型。在法國,Mistral 發佈了 Mistral Large 3 系列,持續推進其開源根基。
但與此同時,西方的也有多項重要發佈是建立在中國模型之上。2025 年 11 月,Deep Cogito 發佈了 Cogito v2.1,被視為當時領先的美國開放權重模型,而該模型正是 DeepSeek-V3 的微調版本。在全球範圍內,使用開放權重模型的初創公司和研究人員,往往將中國開發的模型作為默認選擇,甚至在很大程度上依賴這些模型。
美國的 Truly Open Model(ATOM) 項目也明確將 DeepSeek 及中國模型所展現出的發展勢頭,視為推動其致力於在開放權重模型領域取得領先地位的重要動因。該項目強調需要多方力量共同投入,其相關研究同樣指出了 OpenAI 的 gpt-oss 在早期階段所獲得的大規模採用。
世界仍在持續迴應這一變化,一股新的開源熱潮正在形成。2026 年有望迎來一系列重大發布,尤其是來自中國和美國的發佈。而與之高度相關的,將是架構趨勢、硬件選擇以及組織發展方向——這些內容,將在本系列的下一篇文章中進一步展開。