11 月 18 日晚,Cloudflare 遭遇波及全球的大規模網絡故障,導致 ChatGPT、社交媒體平台 X 等多家網站部分用户無法正常訪問。
彼時,Cloudflare 在系統狀態頁面稱正就“可能影響多個客户”的問題展開調查。該頁面還顯示,其客户支持門户此前已出現故障,且當日早些時候已安排在部分地區進行計劃內維護。
Cloudflare 團隊今天早上在其博客發佈了故障覆盤文章,以下內容來自馮若航對該文章的翻譯:《Cloudflare 11-18 斷網故障覆盤報告》。
2025 年 11 月 18 日 11:20 UTC(本文所有時間均為 UTC),Cloudflare 的網絡開始出現核心網絡流量傳輸的嚴重故障。 對於嘗試訪問我們客户網站的 Internet 用户而言,這種故障表現為一個錯誤頁面,提示 Cloudflare 網絡內部發生了故障。
此次問題並非由任何形式的網絡攻擊或惡意活動直接或間接導致。相反,起因是我們一個數據庫系統的權限更改, 導致該數據庫將多個條目輸出到了我們的 Bot 管理系統所使用的一個“特徵文件”中。 該特徵文件的大小因此翻了一倍。這個超出預期大小的特徵文件隨後被分發到構成我們網絡的所有服務器上。
運行在這些服務器上的軟件(用於在我們的網絡中路由流量)會讀取這個特徵文件,以使我們的 Bot 管理系統能夠應對不斷變化的威脅。 該軟件對特徵文件的大小設有一個上限,而這個上限低於特徵文件翻倍後的大小,導致軟件發生了故障。
最初,我們誤以為所觀察到的症狀是一場超大規模 DDoS 攻擊所致。 後來,我們正確地識別出了問題的核心原因,並阻止了那個超出預期大小的特徵文件繼續傳播, 將其替換為之前的一個版本。 到 14:30 時,我們的大部分核心流量已經基本恢復正常。此後幾小時裏,隨着流量回升,我們團隊持續努力減輕網絡各部分面臨的過載問題。 截至 17:06,Cloudflare 的所有系統均已恢復正常。
我們對本次事件給客户和整個 Internet 帶來的影響深表歉意。 鑑於 Cloudflare 在互聯網生態系統中的重要性,我們的任何系統發生中斷都是不可接受的。 而我們的網絡有一段時間無法路由流量,這讓我們團隊的每一名成員都深感痛心。我們知道,今天我們讓大家失望了。
本文將深入詳述事件的經過,以及哪些系統和流程出現了故障。 這也是我們開始着手採取行動以確保類似中斷不再發生的起點(但絕非結束)。
故障概況
下圖顯示了 Cloudflare 網絡返回的 HTTP 5xx 錯誤狀態碼數量。正常情況下,這個值應當非常低,事實在故障開始前也是如此。
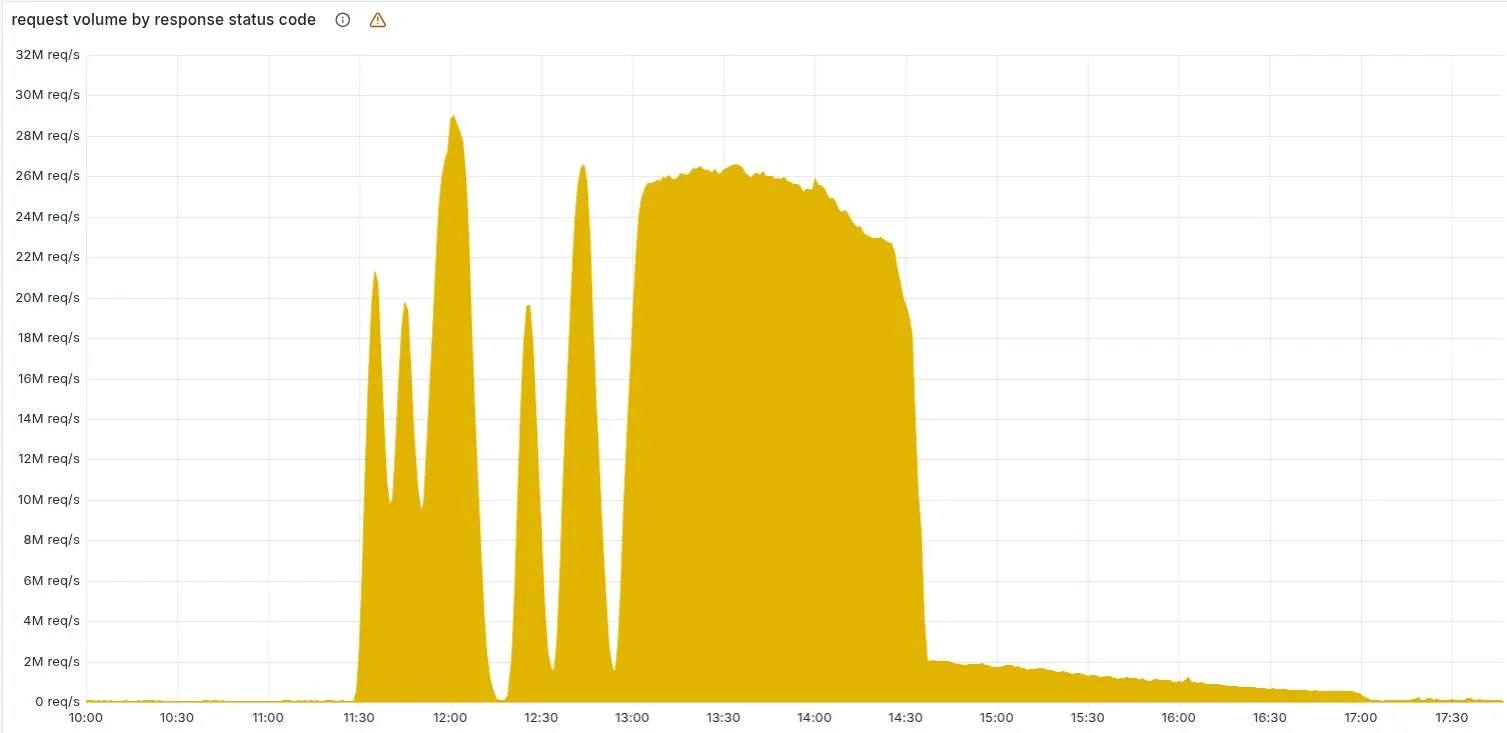
在 11:20 之前,5xx 錯誤數量保持在我們預期的基線水平。之後的激增及隨後的波動表明,由於加載了錯誤的特徵文件,我們的系統發生了故障。 有一點值得注意:我們的系統隨後一度自行恢復正常過一段時間——對於內部錯誤而言,這種現象非常不尋常。
原因在於,這個文件每隔五分鐘由一個在 ClickHouse 數據庫集羣上運行的查詢生成,而該集羣當時正在逐步更新以改進權限管理。 只有當查詢在已更新的集羣節點上運行時,才會生成錯誤數據。因此,每隔五分鐘,就有可能生成一套正確的或錯誤的配置文件,並迅速傳播到整個網絡。
這種波動使我們難以及時判斷髮生了什麼,因為整個系統會先恢復正常,然後在下一次分發配置文件時(有時文件正確、有時文件錯誤)再次發生故障。 起初,這讓我們認為故障可能是由攻擊造成的。最終,當每個 ClickHouse 節點都開始生成錯誤的配置文件後,系統波動停止並穩定地處於故障狀態。
錯誤一直持續到 14:30,我們才找到根本原因並着手解決問題。 我們通過停止生成和傳播錯誤的特徵文件,並手動將一份已知良好的文件插入特徵文件分發隊列來解決問題,隨後強制重啓了我們的核心代理。 上圖中後面拖長的尾部曲線,代表我們的團隊在逐步重啓那些進入異常狀態的服務;到 17:06 時,5xx 錯誤數量已恢復正常。
以下服務受到了影響:
•核心CDN與安全服務:返回 HTTP 5xx 狀態碼。(本文開頭的截圖展示了終端用户看到的典型錯誤頁面。)
•Turnstile:無法加載。
•Workers KV:出現了顯著升高的 HTTP 5xx 錯誤率,因為對 Workers KV “前端”網關的請求由於核心代理故障而失敗。
•Dashboard:儀表盤基本保持可用,但由於登錄頁面上的 Turnstile 無法使用,大多數用户無法登錄。
•Email安全:雖然郵件處理和傳遞未受影響,但我們觀察到一度無法訪問某個 IP 信譽數據源,導致垃圾郵件檢測準確性降低,並使一些基於域名註冊時長的檢測未能觸發(未發現嚴重的客户影響)。我們還觀察到部分自動移動操作(Auto Move)失敗;所有受影響的郵件均已過審查並得到處理。
•Access:從故障開始到 13:05 回滾期間,大多數用户的身份驗證嘗試都失敗了(已有的 Access 會話不受影響)。
所有這些失敗的身份驗證嘗試都會出現錯誤頁面,這意味着故障期間這些用户無法訪問其目標應用。而在此期間成功的登錄嘗試都已被正確記錄。嘗試在故障期間進行的任何 Access 配置更新要麼完全失敗,要麼傳播非常緩慢;目前所有配置更新均已恢復正常。
除了返回 HTTP 5xx 錯誤,我們還觀察到在故障影響期間 CDN 響應的延遲顯著增加。 這是因為我們的調試和可觀測性系統消耗了大量 CPU 資源——它們會在未捕獲的錯誤中自動附加額外的調試信息。
Cloudflare 請求處理流程及本次故障原因
每個發往 Cloudflare 的請求都會沿着我們網絡中一條明確的路徑進行處理。 請求可能來自加載網頁的瀏覽器、調用 API 的移動應用,或者來自其他服務的自動化流量。 這些請求首先終止於我們的 HTTP 和 TLS 層,然後流入我們的核心代理系統(我們稱之為 FL,即 “Frontline”), 最後經由 Pingora 執行緩存查找,或在需要時從源站獲取數據。
我們曾在這裏更詳細地介紹過 核心代理的工作原理。
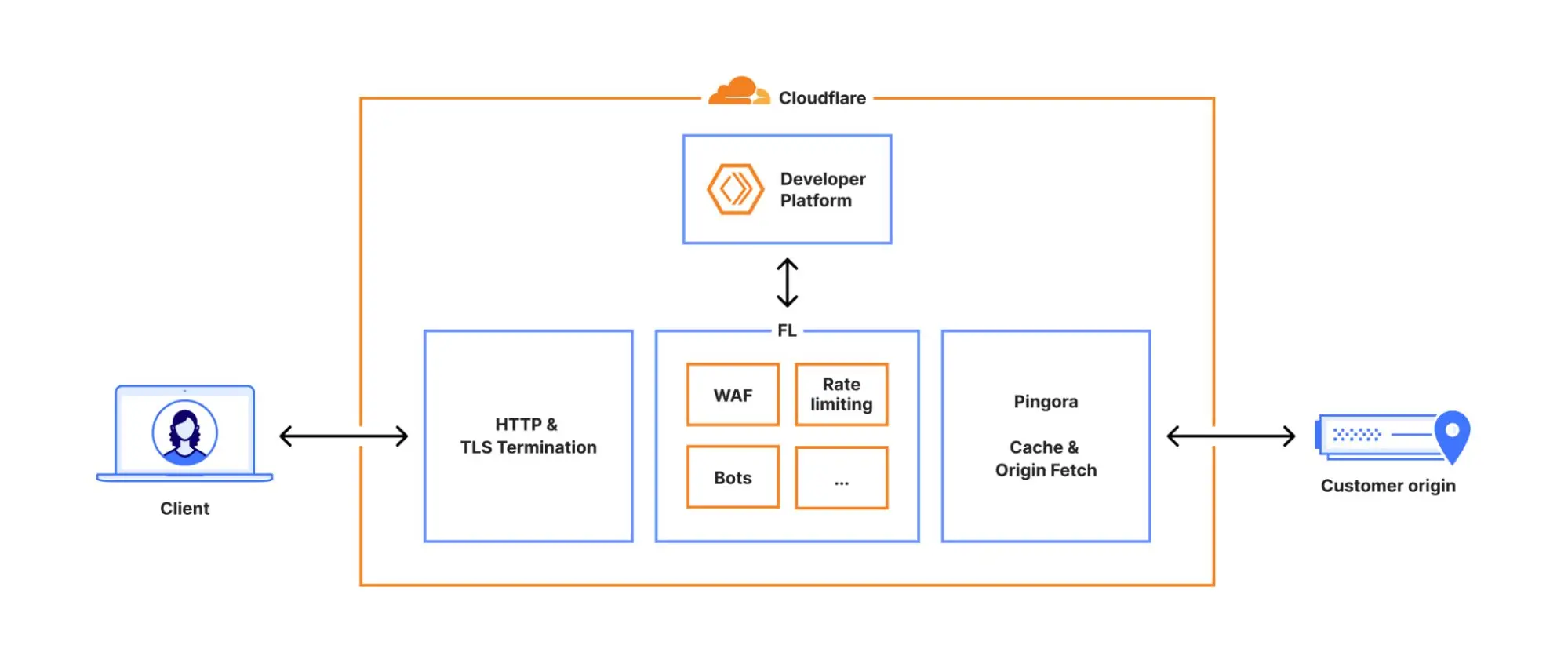
當請求通過核心代理時,我們會運行網絡中提供的各種安全和性能產品。 核心代理根據每個客户的特定配置和設置處理流量,從執行 WAF 規則、防禦 DDoS 攻擊,到將流量路由到開發者平台和 R2 等。 這一過程通過一系列特定領域的模塊實現,這些模塊對經過代理的流量應用相應的配置和策略規則。
這些模塊中的一個 —— Bot 管理模塊,正是此次故障的源頭。
Cloudflare 的 Bot管理系統 包含多個子系統, 其中包括一個機器學習模型,我們用它為經過我們網絡的每個請求生成“機器人分數”。 客户可以使用這個分數來控制哪些機器人被允許訪問他們的網站,哪些則不被允許。
該模型使用一個“特徵”配置文件作為輸入。在這裏,“特徵”是指機器學習模型用來判斷請求是否由自動程序發出的單個屬性。特徵配置文件是由各個獨立的特徵組合而成的集合。
這個特徵文件每隔幾分鐘就會刷新併發布到我們整個網絡上,使我們能夠對 Internet 上不斷變化的流量模式作出響應。 它讓我們能夠應對新型的機器人以及新的機器人攻擊。因此,需要頻繁且快速地發佈該文件,因為惡意行為者往往很快改變策略。
在生成該文件的底層 ClickHouse 查詢行為發生變化(詳見下文)後,文件中出現了大量重複的“特徵”行。 這使得原本固定大小的特徵配置文件變得比預期更大,導致 Bot 模塊觸發了錯誤。
結果是,核心代理在處理任何依賴 Bot 模塊的流量時都會返回 HTTP 5xx 錯誤。 這也影響到了依賴核心代理的 Workers KV 和 Access。
需要指出的是,我們當時正在將客户流量遷移到新版代理服務(內部稱為 FL2)。 舊版和新版代理引擎都受到了這一問題的影響,儘管表現出的影響有所不同。
使用新 FL2 代理引擎的客户遇到了 HTTP 5xx 錯誤。而使用舊版代理(FL)的客户雖然沒有看到錯誤,但機器人分數未能正確生成,所有流量的機器人分數都變成了零。 那些基於機器人分數設置了封禁規則的客户會遇到大量誤判;未在規則中使用機器人分數的客户則沒有受到影響。
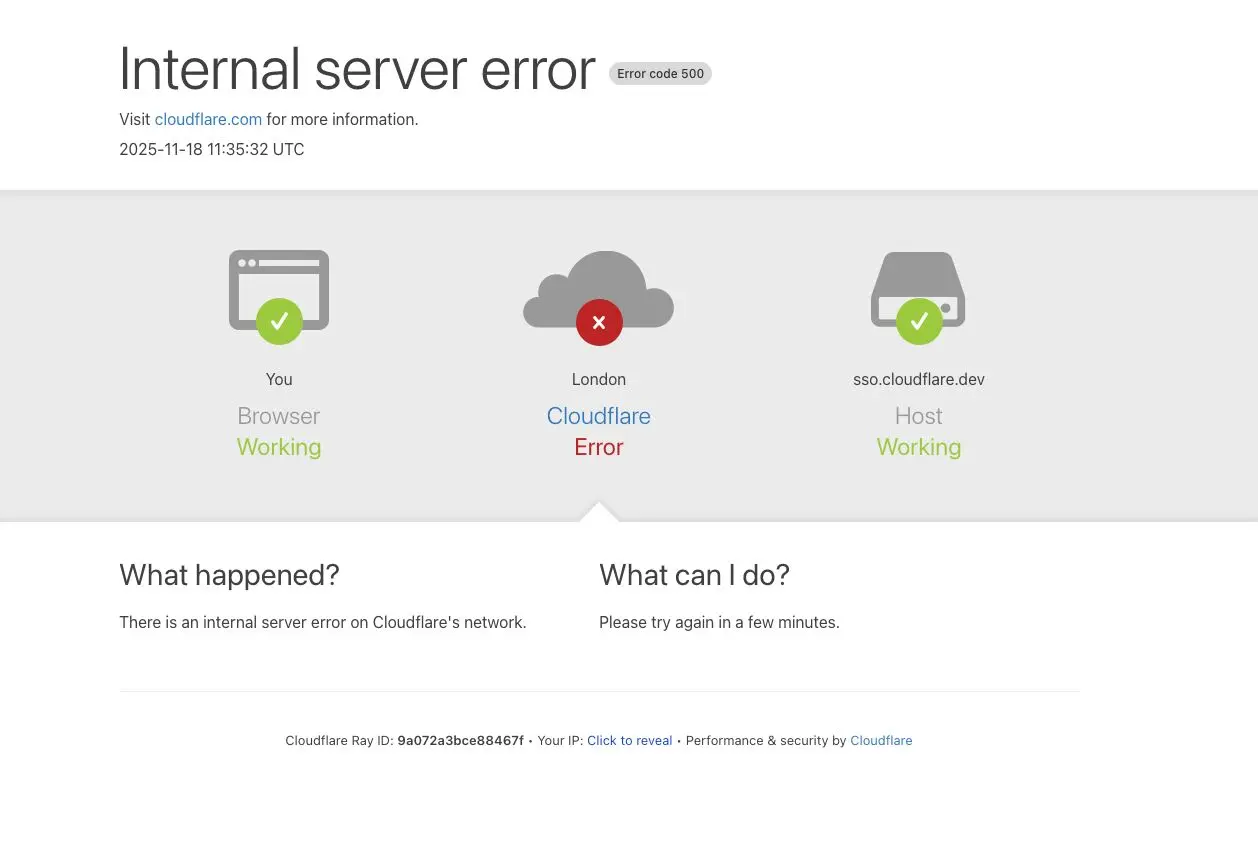
還有一個現象最初使我們誤以為遇到了攻擊:Cloudflare 的狀態頁也發生了故障。 狀態頁完全託管在 Cloudflare 基礎設施之外,與 Cloudflare 系統沒有任何依賴關係。 雖然事後證明這只是一個巧合,但它使得部分診斷團隊成員一度認為攻擊者可能同時針對了我們的系統和狀態頁。 在那段時間訪問狀態頁的用户會看到如下的錯誤信息:

在內部事故聊天頻道中,我們擔心這可能是最近一系列高流量 Aisuru DDoS 攻擊 的延續:
查詢行為的變化
正如前文提到的,底層查詢行為的更改導致特徵文件中包含了大量重複行。此處涉及的數據庫系統使用的是 ClickHouse 軟件。
這裏有必要説明一下 ClickHouse 分佈式查詢是如何工作的:一個 ClickHouse 集羣由許多分片組成。 為了從所有分片查詢數據,我們在名為 default 的數據庫中使用所謂的分佈式表(由 Distributed 表引擎提供支持)。 Distributed 引擎會查詢名為 r0 的數據庫中的底層表;這些底層表是每個分片上實際存儲數據的地方。
對分佈式表的查詢是通過一個共享的系統賬户執行的。作為提高分佈式查詢安全性和可靠性工作的其中一環,我們正在努力使這些查詢改為在初始用户賬户下運行。
在今天之前,當從 ClickHouse 的系統表(如 system.tables 或 system.columns)查詢表的元數據時,用户只能看到 default 數據庫中的表。
由於用户已經隱含擁有對 r0 數據庫中底層表的訪問權限,我們在 11:05 進行了改動,將這種訪問權限顯式化,以便用户也能看到這些表的元數據。 通過確保所有分佈式子查詢都在初始用户上下文中運行,我們可以更細粒度地評估查詢限制和訪問授權,從而避免某個用户的異常子查詢影響到其他用户。
上述改動使得所有用户都可以獲取到其有權限訪問的表的準確元數據。 不幸的是,此前有些代碼假定這類查詢返回的列列表只會包含 “default” 數據庫下的內容。例如下面的查詢並沒有按數據庫名過濾:
SELECT name, type FROM system.columns WHERE table = 'http_requests_features' ORDER BY name;
注意,上述查詢並未按數據庫名稱進行過濾。隨着我們逐步在該 ClickHouse 集羣上推出顯式授權, 上述查詢在 11:05 的改動後開始返回列的“重複”,因為結果中包含了存儲在 r0 數據庫中底層表的列。
不巧的是,Bot 管理特徵文件的生成邏輯執行的正是上述類型的查詢來構建文件中的每一個“特徵”。
上述查詢會返回一個類似下表所示的列清單(示例經過簡化):

然而,由於給用户授予了額外的權限,查詢結果現在包含了 r0 模式下的所有相關元數據,有效地使響應行數增加了一倍多,最終導致輸出文件中的特徵數量大大超出正常範圍。
內存預分配
我們的核心代理服務中的每個模塊都設置了一些上限,以防止內存無限增長,並通過預分配內存來優化性能。在本例中,Bot 管理系統限定了運行時可使用的機器學習特徵數量。 目前該上限設置為 200,遠高於我們當前大約 60 個特徵的使用量。再次強調,這個限制存在是出於性能考慮,我們會預先為這些特徵分配內存空間。
當包含超過 200 個特徵的錯誤文件被傳播到我們的服務器時,這一限制被觸發——系統因此發生了 panic。下面的 FL2(Rust)代碼片段顯示了執行該檢查並導致未處理錯誤的部分:
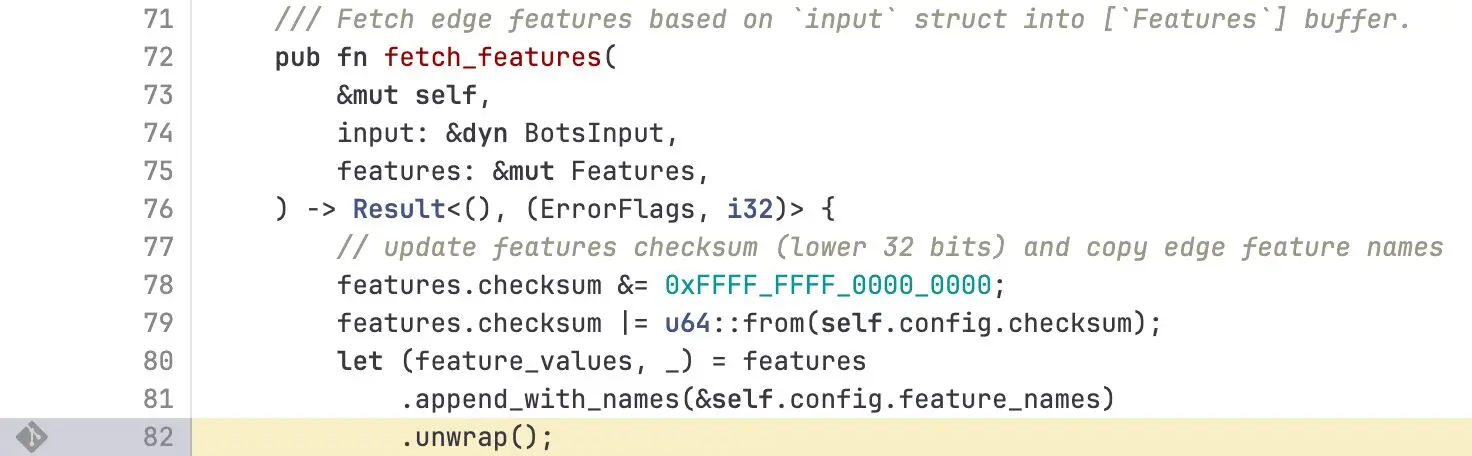
由此產生了如下所示的 panic 日誌,進而導致了 5xx 錯誤:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
故障期間的其他影響
在此次事故中,其他依賴我們核心代理的系統也受到了影響,包括 Workers KV 和 Cloudflare Access。 在 13:04,我們對 Workers KV 實施了補丁以使其繞過核心代理,從而降低了這些系統所受的影響。 此後,所有依賴 Workers KV 的下游系統(例如 Access 本身)的錯誤率都降低了。
Cloudflare 儀表盤(Dashboard)也受到了影響,因為儀表盤內部使用了 Workers KV,且我們的登錄流程中部署了 Cloudflare Turnstile。
這次中斷也影響了 Turnstile:對於沒有活躍儀表盤會話的用户,他們在事故期間無法登錄。 儀表盤的可用性在兩個時間段內下降:11:30 至 13:10,以及 14:40 至 15:30(如下圖所示)。
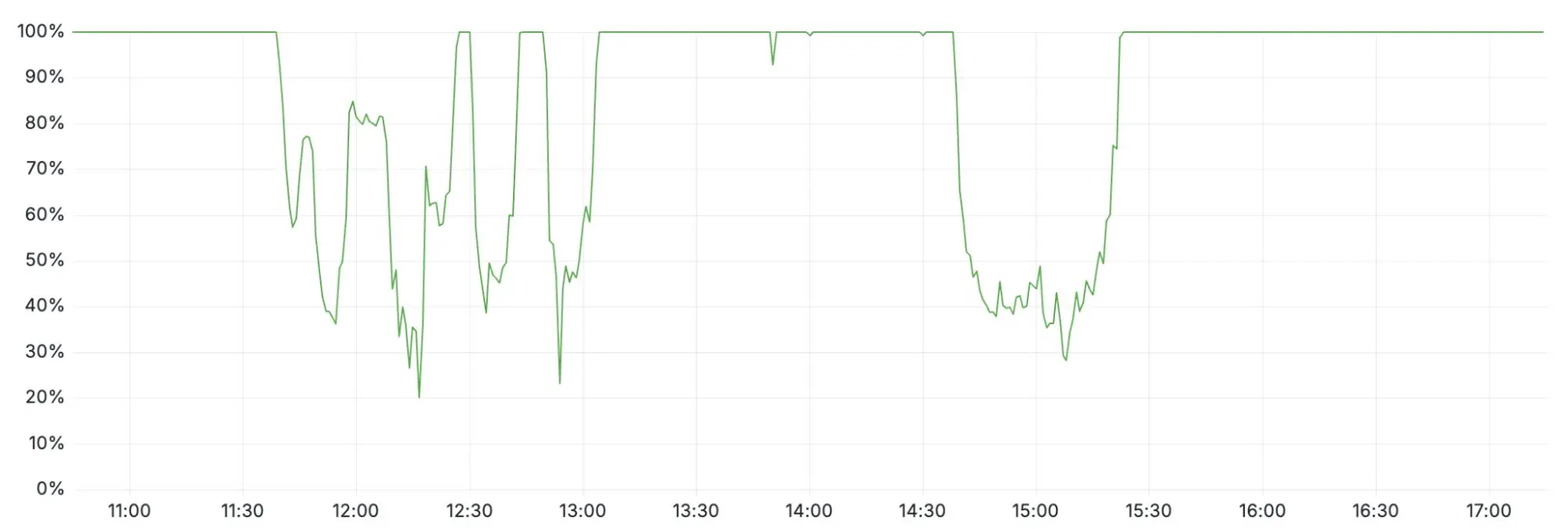
第一個時間段(11:30 至 13:10)的可用性下降是由於 Workers KV 受到了影響——一些控制平面和儀表盤功能依賴於 Workers KV。 在 13:10,當 Workers KV 繞過核心代理系統後,這些功能恢復了正常。 第二個時間段的儀表盤可用性問題發生在恢復特徵配置數據之後。 大量積壓的登錄嘗試開始讓儀表盤不堪重負。這些積壓的請求結合用户重試操作,導致了高延遲,儀表盤可用性下降。 通過提升控制平面的併發處理能力,我們在大約 15:30 恢復了儀表盤的可用性。
補救措施和後續步驟
現在,我們的系統已經恢復正常運行,我們已經開始着手研究如何在未來加強系統抵禦類似故障的能力。具體來説,我們將:
•像對待用户生成的輸入那樣,強化對 Cloudflare 內部生成的配置文件的攝取和校驗;
•為功能啓用更多全局性的緊急開關;
•消除核心轉儲或其他錯誤報告佔用過多系統資源的可能性;
•審查所有核心代理模塊在錯誤情況下的失效模式。
今天的事故是 Cloudflare 自 2019 年以來最嚴重的一次中斷。我們過去也出現過讓儀表盤無法使用的停機,還有一些導致較新功能暫時不可用的故障。但在過去超過 6 年的時間裏,我們沒有再出現過讓大部分核心流量停止的中斷。
像今天這樣的中斷是不可接受的。我們在架構設計上讓系統具備高度的容錯能力,以確保流量始終可以繼續傳輸。 每次過去發生故障後,我們都會據此構建新的、更可靠的系統。
我謹代表 Cloudflare 全體團隊,對我們今天給互聯網帶來的影響表示誠摯的歉意。
|
時間 |
狀態 |
描述 |
|
11:05 |
正常 |
數據庫訪問控制更改已部署。 |
|
11:28 |
故障開始 |
新配置部署到客户環境,在客户的 HTTP 流量中首次觀察到錯誤。 |
|
11:32–13:05 |
調查進行中 |
團隊調查了 Workers KV 服務流量和錯誤率升高的問題。初始症狀表現為 Workers KV 響應速度下降,導致 Cloudflare 其他服務受到下游影響。團隊嘗試通過流量調整和賬户限制等措施使 Workers KV 恢復正常。11:31 自動測試首次檢測到問題,11:32 開始人工調查,並在 11:35 發起了事故會議。 |
|
13:05 |
影響減輕 |
針對 Workers KV 和 Cloudflare Access 啓用了內部繞過,使它們回退到較早版本的核心代理。雖然舊版核心代理也存在該問題,但其影響較小(如上文所述)。 |
|
13:37 |
準備回滾 |
我們確認 Bot 管理配置文件是事故的觸發因素。各團隊以多種途徑着手修復服務,其中最快的方案是恢復該配置文件之前已知的良好版本。 |
|
14:24 |
停止發佈 |
停止生成和傳播新的 Bot 管理配置文件。 |
|
14:24 |
測試完成 |
使用舊版本配置文件進行的恢復測試取得成功,我們隨即開始加速在全球範圍內部署修復。 |
|
14:30 |
主要故障解除 |
部署了正確的 Bot 管理配置文件,大多數服務開始恢復正常。 |
|
17:06 |
全部恢復 |
所有下游服務均已重啓,全部業務功能已完全恢復。 |
原文:https://blog.cloudflare.com/18-november-2025-outage
