今年 8 月,美團開源的 InfiniteTalk 項目憑藉無限長度生成能力與精準的唇形、頭部、表情及姿態同步表現,迅速成為語音驅動虛擬人領域的主流工具,吸引全球數萬名開發者的使用。10月底,LongCat 團隊開源了 LongCat-Video 視頻生成模型,尤其在長視頻生成領域具備顯著優勢。

在 InfiniteTalk 和 LongCat-Video 基座的良好基礎上,LongCat 團隊針對實際場景中的核心痛點持續優化,正式發佈並開源 SOTA 級虛擬人視頻生成模型 ------LongCat-Video-Avatar。該模型基於 LongCat-Video 基座打造,延續 "一個模型支持多任務" 的核心設計,原生支持 Audio-Text-to-Video(AT2V)、Audio-Text-Image-to-Video(ATI2V)及視頻續寫等核心功能,同時在底層架構上全面升級,實現動作擬真度、長視頻穩定性與身份一致性三大維度的顯著突破,為開發者提供更穩定、高效、實用的創作解決方案。
點擊查看產品介紹視頻
開源地址:
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar
- Project:https://meigen-ai.github.io/LongCat-Video-Avatar/
一、技術亮點
1.1 開源 SOTA 擬真度:讓虛擬人"活"起來
告別"僵硬",迎接"鮮活"。還記得以前那些虛擬人嗎?只有嘴巴在動,頭和身體卻像沒通電,看起來既尷尬又不自然。全新的 LongCat-Video-Avatar 徹底改變了這一點。它像一位全能導演,不僅指揮嘴型,還同步指揮眼神、表情和肢體動作,實現豐富飽滿的情感表達,讓虛擬人真正"演"了起來。
點擊查看效果對比
連"不説話"的時候,都很像人: 真人説話是有停頓和呼吸的。我們通過一種獨特的訓練方法 Disentangled Unconditional Guidance(解耦無條件引導),讓模型明白了"靜音"不等於"死機"。現在,哪怕是在説話的間歇,虛擬人也會像你我一樣,自然地眨眼、調整坐姿、放鬆肩膀。
這種技術讓 LongCat-Video-Avatar 成為首個同時支持文字、圖片、視頻三種生成模式的全能選手。從口型精準到全身生動,虛擬人從此有了真正的生命力。
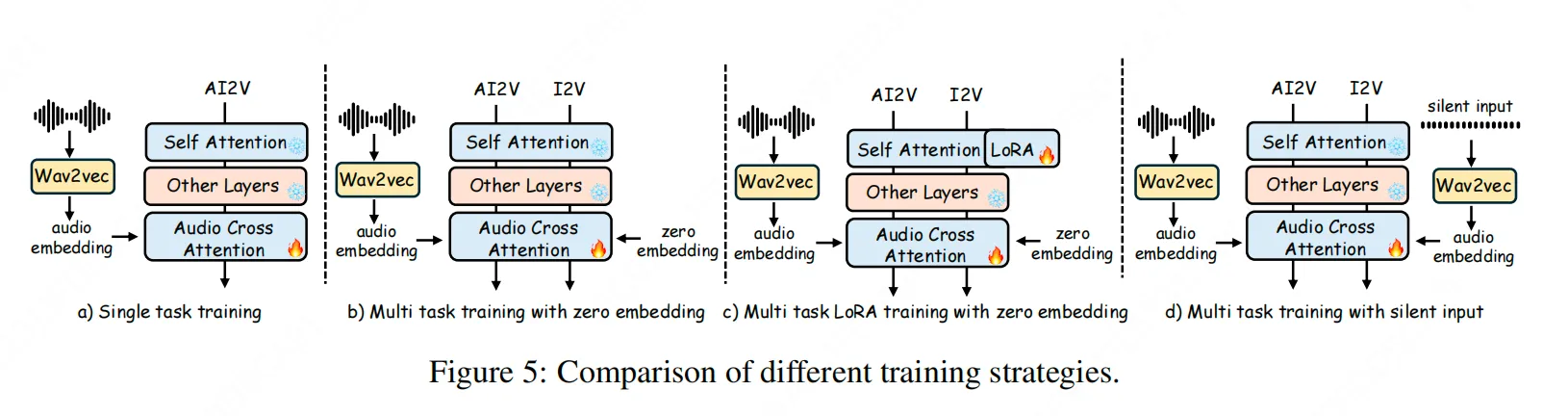
1.2 長時序高質量生成:讓視頻"穩"下來
上一代 InfiniteTalk 在長視頻生成中會出現視覺質量退化的現象,而VAE 的反覆編解碼是正是視覺質量退化的主要原因。現有方法通常將上一段生成結果解碼為像素,再將末尾幀重新編碼為潛變量,作為下一段的條件------這一"解碼→再編碼"循環會持續引入累積誤差,導致色彩偏移與細節模糊。
點擊查看效果對比
LongCat-Video-Avatar提出了Cross-Chunk Latent Stitching (跨片段隱空間拼接) 訓練策略以根本性解決此問題。在訓練階段,我們從同一視頻中採樣兩個連續且部分重疊的片段,在隱空間內直接進行特徵替換,讓模型學會在潛空間中無縫銜接上下文。在推理時,系統直接將前一段生成的 latent 序列末尾部分作為下一段的 context latent,全程無需解碼到像素域。該設計不僅消除 VAE 循環帶來的畫質損失,還顯著提升推理效率,並有效彌合訓練與推理之間的流程差異(train-test gap)。實驗顯示,LongCat-Video-Avatar 在生成5分鐘約 5000 幀視頻時仍保持穩定色彩與清晰細節。
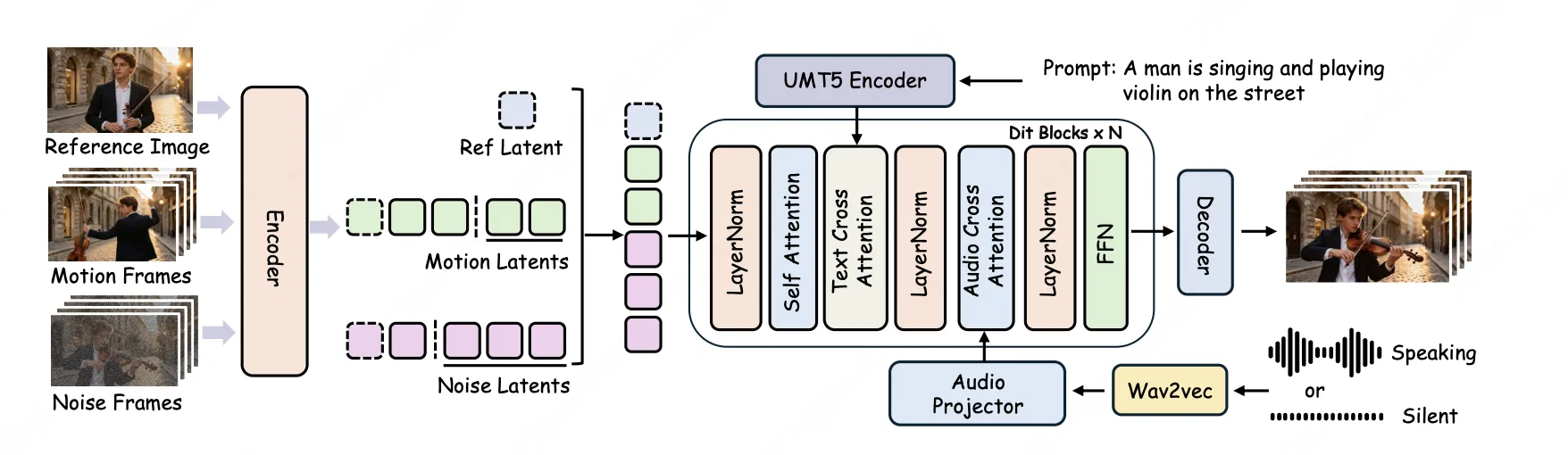
1.3 商用級一致性:精準錨定角色,讓演繹生動自如
點擊查看效果對比
為維持長視頻中的身份(ID)一致性, InfiniteTalk 採用注入參考幀的方式,但有時會導致色彩偏移(color shift)或動作僵化("複製-粘貼"效應)。LongCat-Video-Avatar 從以下兩方面進行系統升級:
- 基座升級:視頻基礎模型遷移到 LongCat-Video,後者在大規模長視頻預訓練中具備了更強的身份保持與色彩一致性先驗。
- 參考機制創新:我們引入了帶位置編碼的參考幀注入模式。推理時,用户可通過指定RoPE中的索引位置,靈活控制參考幀在生成塊中的插入位置。更重要的是,我們設計了Reference Skip Attention機制,在參考幀相鄰的時間步,屏蔽參考幀對注意力計算的直接影響,僅允許其提供身份語義先驗,而不主導具體動作生成。這套機制在確保ID一致性的同時,有效抑制了動作的重複與僵化,使長視頻既穩定又富有變化。
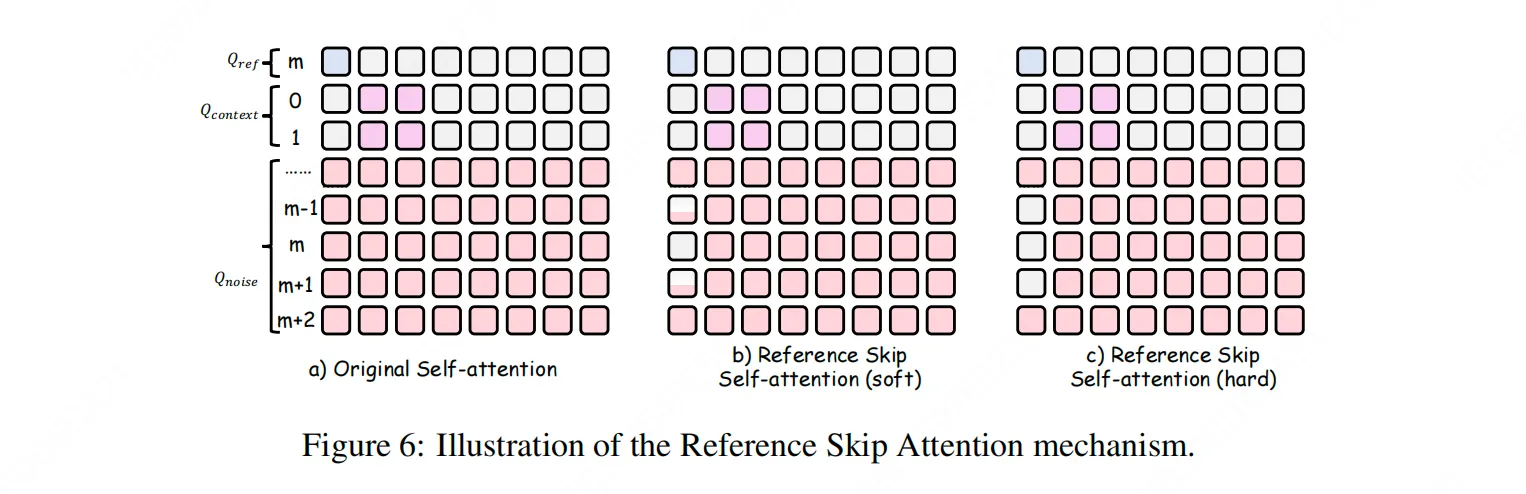
二、模型性能
2.1 客觀基準評測
在 HDTF、CelebV-HQ 、EMTD 和 EvalTalker 等權威公開數據集上的定量評測表明,LongCat-Video-Avatar 在多項核心指標上達到SOTA領先水平。
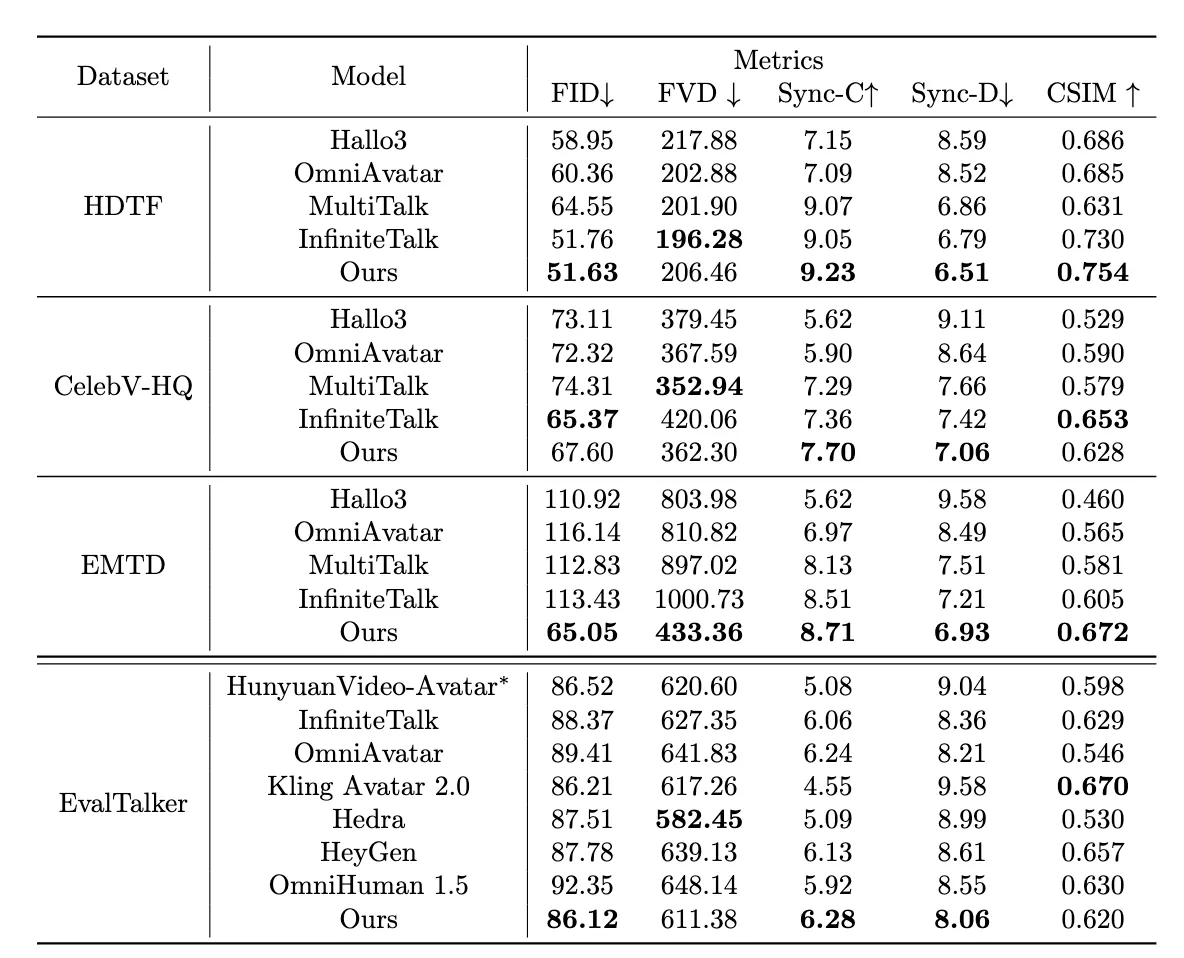
在衡量唇音同步精度的 Sync-c/Sync-D指標上,LongCat-Video-Avatar 在各個數據集上均取得 SOTA 成績;在一致性指標方面(FID、FVD、CSIM)也表現優異。
2.2 綜合主觀評測
為貼近真實用户體驗,我們基於 EvalTalker 基準組織了大規模人工評測,從"自然度與真實感"維度對生成視頻進行盲測打分(5分制)。
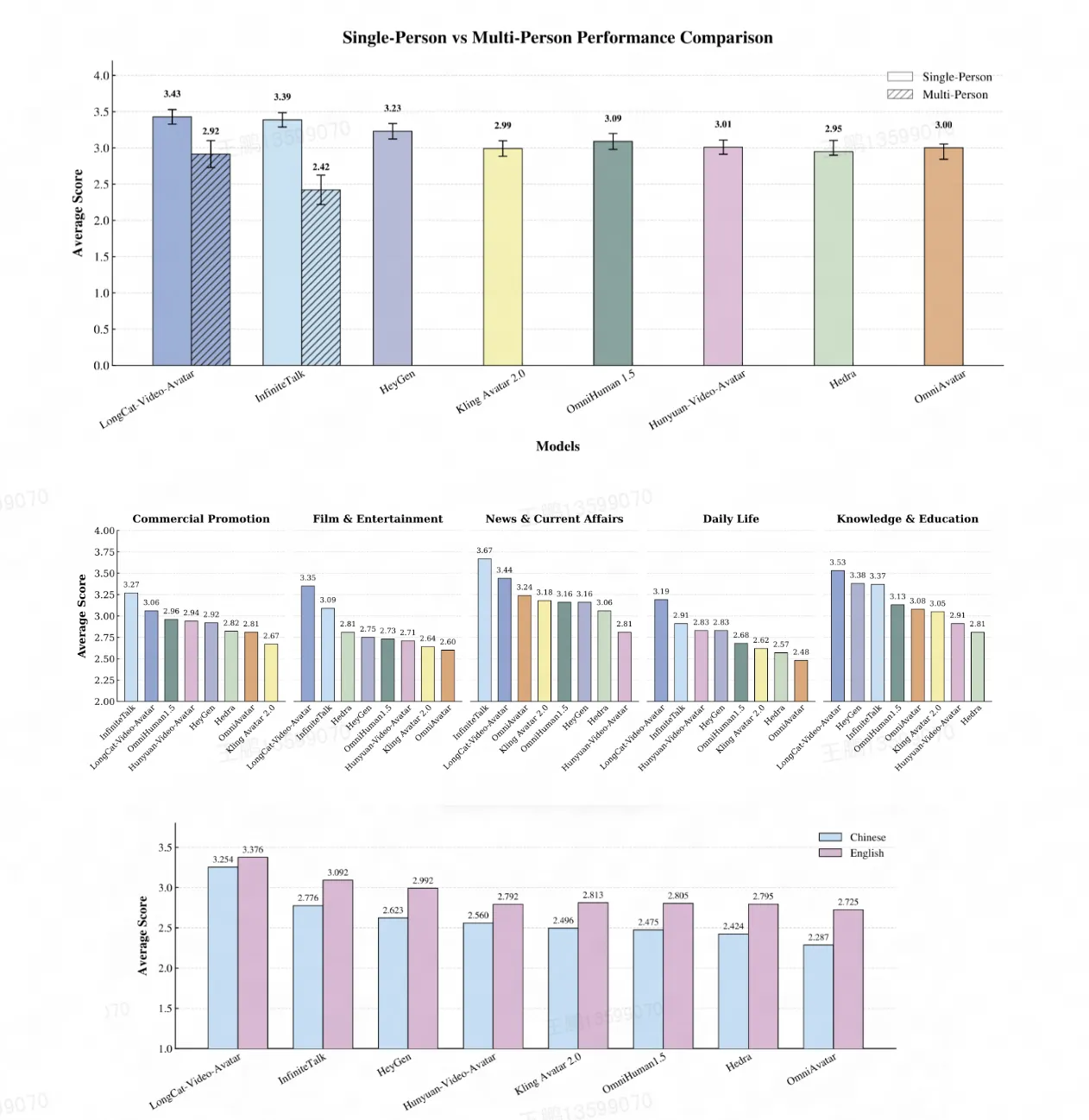
在涵蓋商業推廣、影視娛樂、新聞時事、日常生活和知識教育五大場景的單人對話測試中,LongCat-Video-Avatar 的綜合評分領先於包括 InfiniteTalk、HeyGen、Kling Avatar 2.0 在內的眾多主流開源與商業模型。
通過基於EvalTalker基準的嚴謹人工評測(共492名參與者),LongCat-Video-Avatar在多個細分維度獲得顯著正向反饋:
- 靜音段表現:絕大多數評審者指出,LongCat-Video-Avatar 在靜音段能保持如呼吸、眨眼等自然微動作;
- 長視頻穩定性:在長序列生成中,相較 InfiniteTalk,該模型展現出更優的身份一致性與視覺連續性,有效緩解了長期存在的漂移問題;
- 動作多樣性:得益於創新的參考幀機制,其生成的動作被普遍認為更為豐富、自然,避免了明顯的重複或"複製-粘貼"效應;
- 語言表現:LongCat-Video-Avatar 在中文和英文語言中均優於所有對比方法,體現出穩健的跨語言性能和精準的音畫同步效果;
- 應用場景表現:LongCat-Video-Avatar 在影視娛樂、日常生活和知識教育場景中表現最優,展現出在多樣應用場景下的強泛化能力。
三、One More Thing,開源是為了更好的共創
LongCat-Video-Avatar 是我們繼 InfiniteTalk 之後,在數字人生成方向上的持續迭代。我們關注開發者在長視頻生成中遇到的實際問題------身份漂移、畫面卡頓、靜音段僵硬,並嘗試從模型層面給出改進。
這次開源的不是一個"終極方案",而是一個進化的、可用的技術基座。它們都基於真實反饋與長期實驗,代碼和模型均已開放。我們堅持開源,是因為相信工具的價值在迭代中產生,而迭代需要更多人的使用、驗證與共建。如果你正在探索數字人相關應用,或對生成技術有想法,歡迎關注我們的項目,更歡迎留下你的反饋。
開源地址:
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar
- Project:https://meigen-ai.github.io/LongCat-Video-Avatar/
現在,輪到你來創造"千人千面"的數字世界了。
關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明"內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
