vLLM 團隊正式發佈 vLLM-Omni:這是 vLLM 生態向“全模態(omni-modality)”時代邁出的關鍵一步,專門為新一代看得見、聽得懂、會説話、能生成多種媒介的模型設計的推理框架。

自項目開始,vLLM 一直專注於為大語言模型(LLM)提供高吞吐、低顯存的推理能力。但今天的生成式模型已經遠不止“文本輸入、文本輸出”:新的模型可以同時理解和生成文本、圖像、音頻、視頻,背後也不再是單一自迴歸架構,而是由編碼器、語言模型、擴散模型等異構組件拼接而成。
vLLM-Omni 是最早一批支持“omni-modality”模型推理的開源框架之一,它把 vLLM 在文本推理上的性能優勢,擴展到了多模態和非自迴歸推理領域。
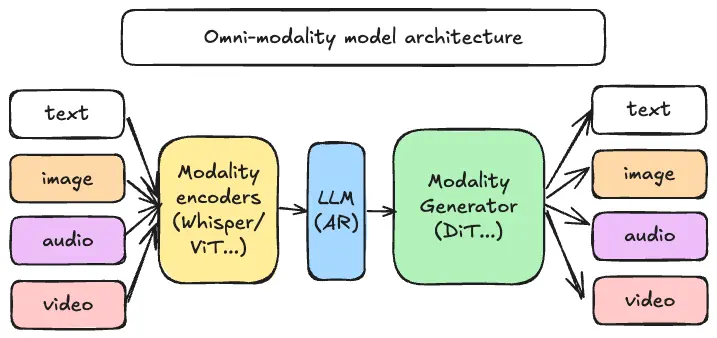
vLLM-Omni 不是在 vLLM 外面再包一層,而是從數據流(data flow)的角度重新拆解了整個推理路徑。它引入了一個完全解耦的流水線架構,讓不同階段可以按需分配資源,並通過統一調度銜接起來。
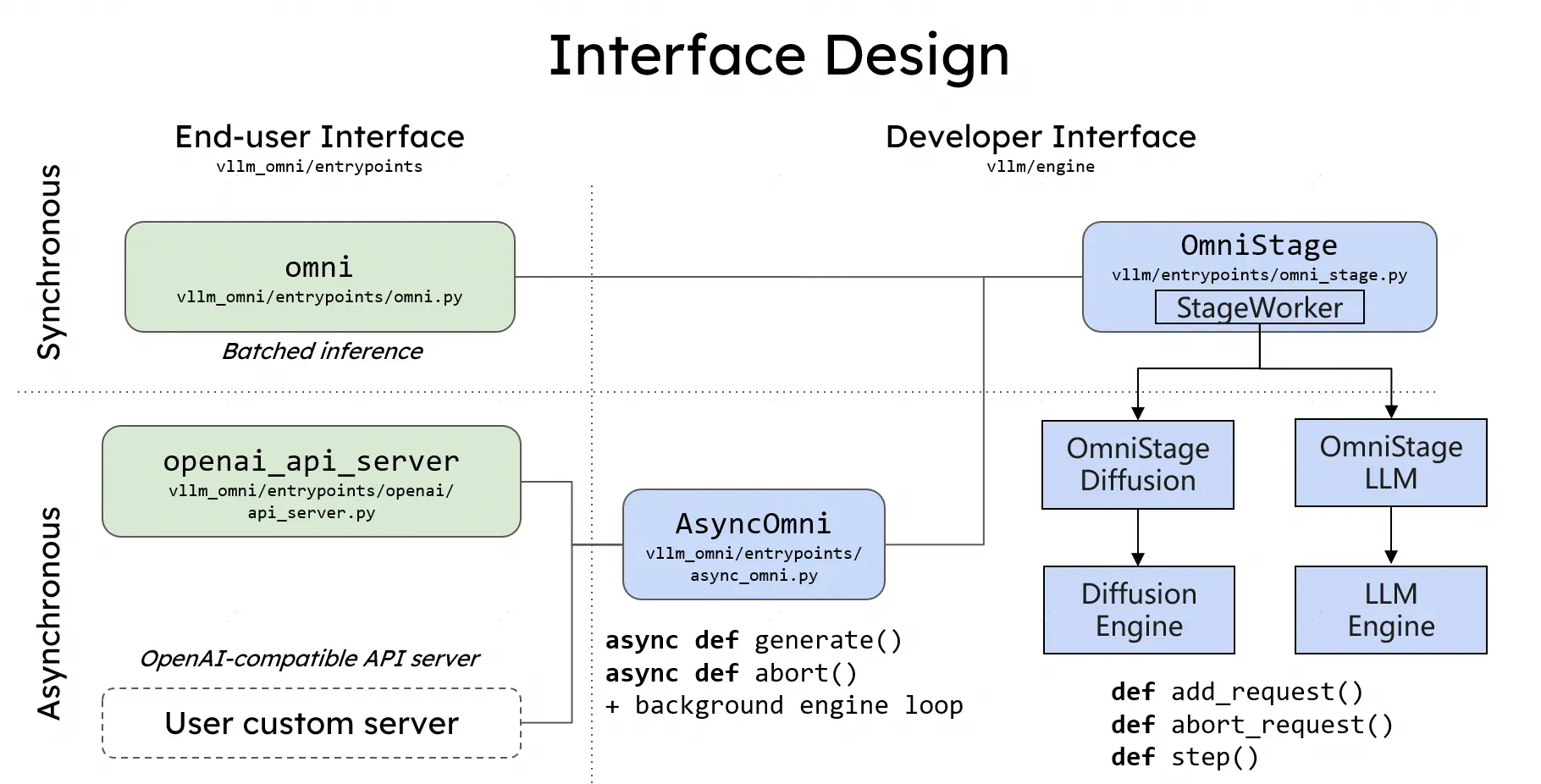
在這套架構中,一個 omni-modality 推理請求大致會經過三類組件:
-
模態編碼器(Modality Encoders):負責高效地把多模態輸入編碼成向量或中間表示,例如 ViT 視覺編碼器、Whisper 等語音編碼器。
-
LLM 核心(LLM Core):基於 vLLM 的自迴歸文本/隱藏狀態生成部分,可以是一個或多個語言模型,用於思考、規劃和多輪對話。
-
模態生成器(Modality Generators):用於生成圖片、音頻或視頻的解碼頭,例如 DiT 等擴散模型。
這些組件並不是簡單串聯,而是通過 vLLM-Omni 的管線調度在不同 GPU/節點間協同工作。對於工程團隊來説,這意味着:
-
可以針對不同階段單獨做擴縮容和部署拓撲設計;
-
可以根據業務瓶頸(如圖像生成 vs 文本推理)調整資源分配;
-
可以在不破壞整體架構的前提下替換局部組件(例如切換為新的視覺編碼器)。
代碼與文檔:
GitHub 倉庫:https://github.com/vllm-project/vllm-omni
文檔站點:https://vllm-omni.readthedocs.io/en/latest/
