摘要
隨着數據密集型應用的快速發展,哈希索引已成為內存數據庫、鍵值存儲和重複數據刪除系統的核心組件。傳統哈希索引在面對持久內存(PMem)時,由於存儲流量放大和內存效率低下,難以充分利用其大容量和持久性優勢。為此,OceanBase研究人員聯合廈門大學、昆士蘭大學學生及教授提出了一種新型哈希索引設計MetoHash,通過層次化設計、批量持久、指紋過濾和重複合併等技術,有效解決了傳統方案在存儲 I/O 放大和內存效率方面的問題。
簡介
隨着數據密集型應用的快速增長,能夠實現常數級查找複雜度的哈希索引已成為構建內存數據庫、鍵值存儲和重複數據刪除系統的核心組件。傳統哈希索引在面對新興的持久內存時,雖然利用了其大容量和數據持久性優勢,卻在存儲流量放大和內存效率方面面臨嚴峻挑戰。
持久內存以其大容量、數據持久性、近 DRAM 性能等特性,為內存架構帶來革命性變革。然而,PMem 的固定訪問粒度和持久化 CPU 緩存特性,使得傳統哈希索引設計難以充分發揮其硬件潛力,其原因在於現有方案極易放大存儲 I/O 或降低內存效率。
日前,一篇題為《MetoHash: A Memory-Efficient and Traffic-Optimized Hashing Index on Hybrid PMem-DRAM Memories》的論文被高性能計算頂級會議SC 2025錄用,並榮獲最佳學生論文提名(該會議錄用的 136 篇論文中選擇 6 篇)。該論文由廈門大學、昆士蘭大學與 OceanBase 的研究人員聯合完成。其中,廈門大學碩士生餘子祥、鄧光陽為共同第一作者,沈志榮教授為通訊作者;昆士蘭大學鮑芝峯教授,以及 OceanBase 的徐泉清、楊傳輝研究員共同參與了此項研究。
SC 由美國計算機協會(ACM)與美國電氣電子工程師學會(IEEE)於 1988 年共同創辦,是全球高性能計算領域公認的年度頂級盛會,是中國計算機學會 CCF 推薦的 A 類國際會議。SC 2025 會議共收到 643 篇投稿,接收 136 篇,錄用率 21.2%。
本論文的核心思想是構建一個跨越 CPU 緩存、DRAM 和 PMem 的三層索引架構,讓數據在層次化存儲中高效流動。
本文提出的 MetoHash 通過層次化設計、批量持久、指紋過濾、重複合併等關鍵技術,系統性地解決了現有方案在流量放大與內存效率上的痛點,為高性能鍵值存儲、內存數據庫、實時分析等應用提供了強大的底層支撐。
核心理念:三層協同,讓數據在混合內存中“各得其所”
傳統哈希索引在面對由持久內存(PMem)和動態隨機存取內存(DRAM)構成的混合內存系統時,面臨一個根本性矛盾:若為追求 PMem 的持久性而將索引完全置於其中,則會因 PMem 較高的訪問延遲和固定的寫入粒度導致嚴重的性能下降和 I/O 放大;若為追求速度而將索引完全置於 DRAM,則又無法利用 PMem 的大容量和持久化優勢。
MetoHash 的創新核心理念在於“解耦與協同”。它不再將哈希索引視為一個單一的整體,而是將其功能拆解,並根據 CPU 緩存、DRAM 和 PMem 的不同硬件特性進行重新部署,構建了一個三層的高效數據管理流水線。其目標是讓熱數據、元數據和海量持久化數據分別在最適合的存儲層級上被處理,從而在整體上實現高吞吐、低延遲、低流量和高內存效率的統一。
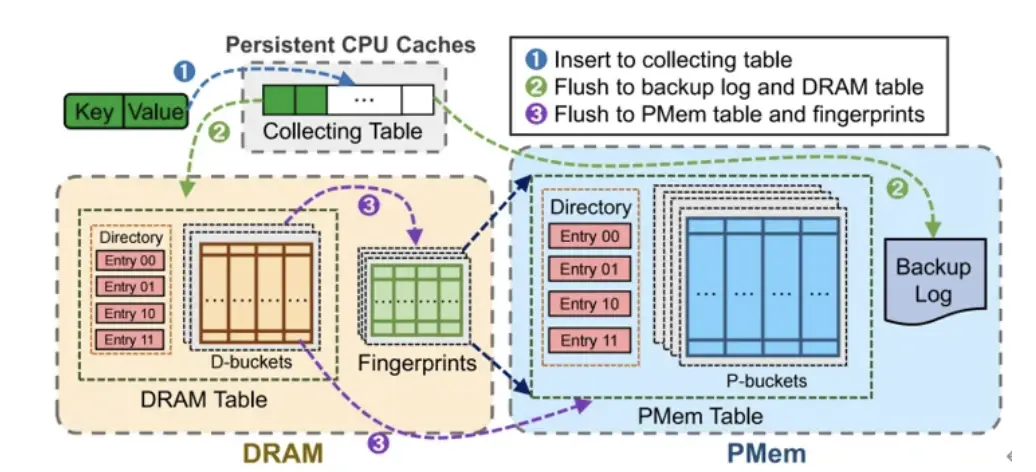
圖1 MetoHash 的三層索引結構
核心技術一:緩存輔助的批量收集寫入
此技術旨在根治向 PMem 進行小粒度插入時引發的“寫放大”(Write Amplification)與頻繁桶探測問題。其方案是在持久性 CPU 緩存中預分配多個與 PMem 訪問粒度對齊的“收集表”(Collecting Table)。新到達的鍵值對根據哈希值被直接路由到相應收集表,並通過原子操作實現無鎖快速插入,從而充分利用緩存的高速與持久化特性。當一個收集表被填滿時,其包含的多個鍵值對將作為一個完整的、與 PMem 最佳寫入粒度匹配的數據單元,被一次性順序刷寫到 PMem 的備份日誌中。這種方法徹底消除了因寫入粒度不匹配帶來的額外 I/O 流量,充分利用 PMem 的寫入帶寬,同時將零散插入轉化為高效批量操作。
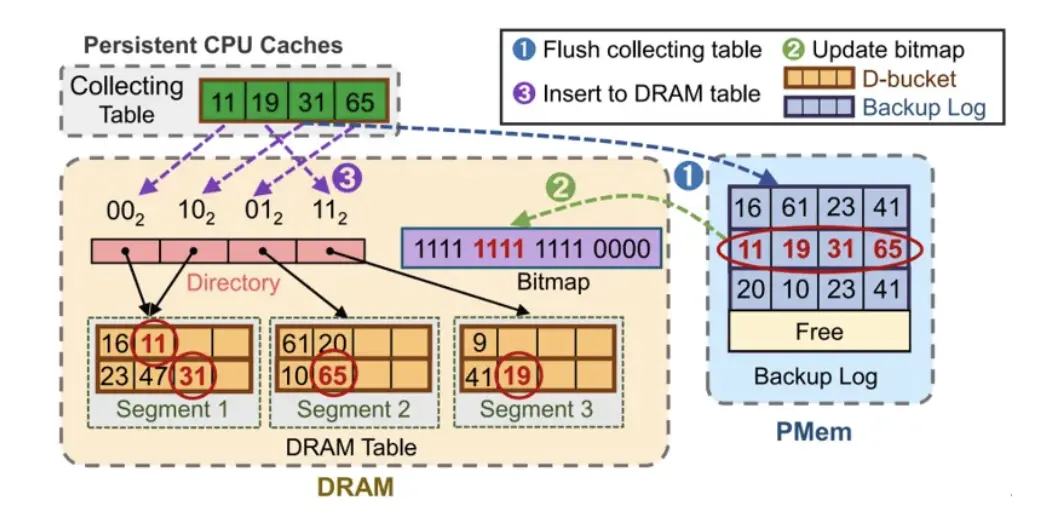
圖2 持久緩存刷入 DRAM 和 PMem 中
核心技術二:基於 DRAM 指紋的反向精準查找
該技術致力於解決在混合多層索引中查詢時在 PMem 層進行盲目、耗時的桶探測的瓶頸。其核心是在 DRAM 中維護一個緊湊的“指紋”目錄,其本質為 PMem 主哈希表中的每個鍵哈希值的一個簡短片段。
在進行查詢時,系統首先計算查詢鍵的指紋,並利用 SIMD 指令等在 DRAM 指紋目錄中進行高速並行比對,迅速篩選出 PMem 中少數幾個可能匹配的位置。只有這些候選位置,才需要訪問 PMem 進行精確的鍵值比較。整個查詢遵循 PMem 主表 → DRAM 表 → CPU 緩存收集表的反向路徑,確保定位到有效值。這一設計將耗時的海量比對操作從慢速的 PMem 轉移至高速的DRAM,極大減少了查詢延遲與 PMem 訪問壓力。
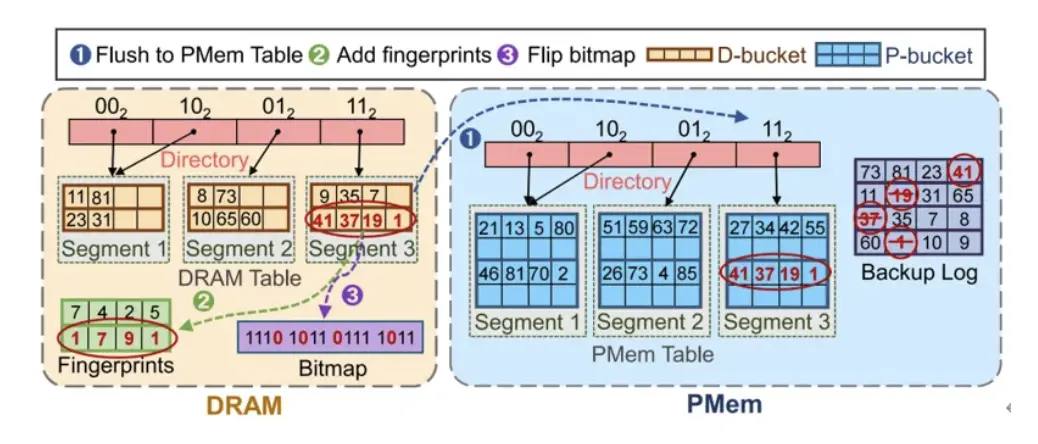
圖3 DRAM 結構刷入 PMem 中,並在 DRAM 中保留指紋
核心技術三:段分裂驅動的重複項消除與空間回收
為解決“先插入後檢查”模式可能產生的鍵重複問題以及刪除操作導致的空間碎片化問題,MetoHash 在數據結構段分裂中引入合併與清理機制。
首先,DRAM 桶與 PMem 桶在邏輯佈局上嚴格對齊,使得 DRAM 桶滿時其內容能高效批量刷寫至 PMem 對應位置。當 PMem 中某個段需要分裂以擴容時,系統將舊段所有數據讀入 DRAM,在此過程中主動識別並消除同一鍵的多個版本的無效值,僅保留其最新的有效項,並將合併、去重後的結果寫入新分配的段。此過程自然跳過了已標記刪除的項,從而在完成容量擴展的同時,一舉實現了存儲空間的即時回收與整理,保持了 PMem 存儲的緊湊性與查詢效率。
性能成果
在實際搭載英特爾傲騰持久內存的測試平台上,MetoHash 與八種前沿方案進行了全面對比。
①吞吐量提升:在 YCSB 等各類負載下,其吞吐量平均超越以往方案 86.1% 至 257.6%,並呈現近線性擴展能力。

圖4 MetoHash 相較其他基線索引在不同負載下均有明顯優勢
②變長數據支持:在處理 16B 至 256B 的變長鍵值時,其吞吐量平均仍領先對比方案 190.8%,尤其在小值主導的負載中優勢顯著。
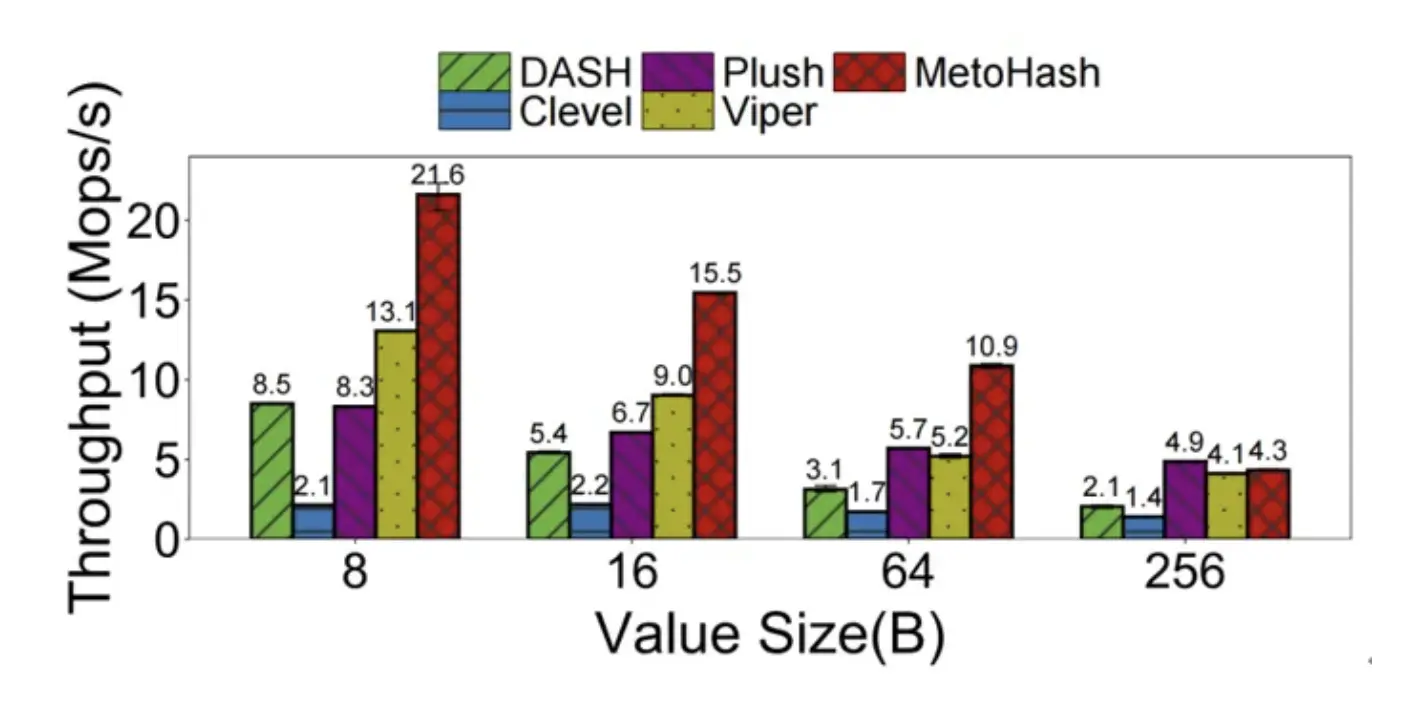
圖5 MetoHash 相較於其他基線索引在不同鍵值對大小下均有明顯優勢
③內存效率權衡:相比將全部索引存於 DRAM 的方案(如 VIPER),MetoHash 的 DRAM 佔用減少 86.7%;相比 PMem 利用率低的方案 (如 Plush),MetoHash 的 PMem 佔用減少 86.5%。
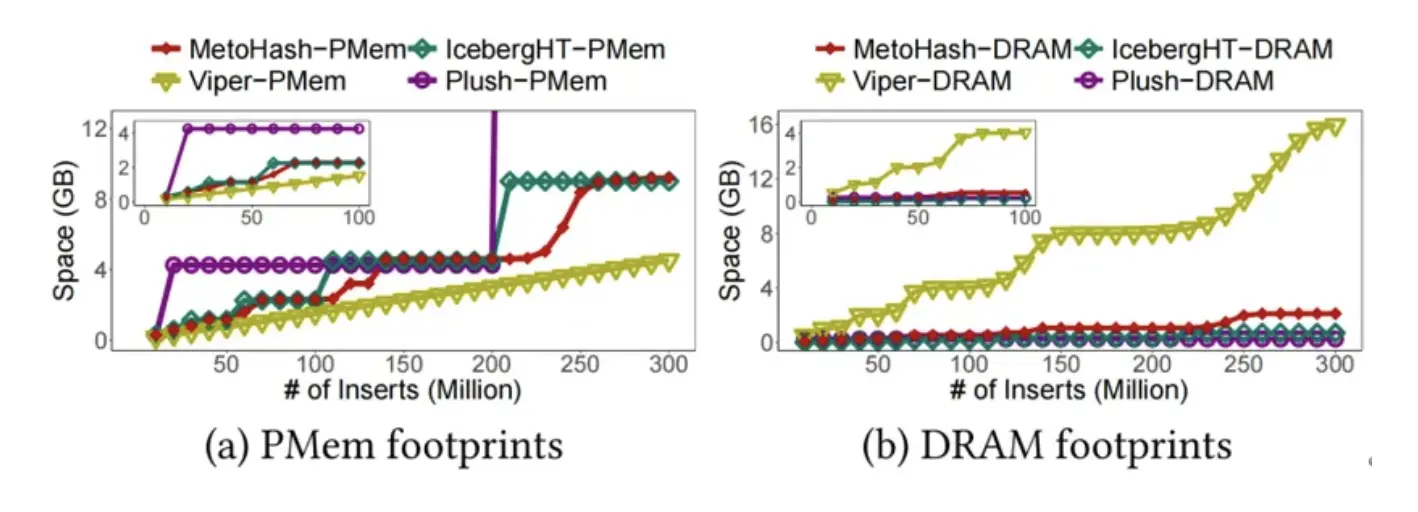
圖6 MetoHash 相較於其他基線索引能夠取得較好的 DRAM/PMem 效率權衡
小結
這項工作提出的 MetoHash 混合內存哈希索引,為持久內存時代的高性能、高內存效率數據管理提供了系統的解決方案。在理論上,MetoHash 首次通過緩存、DRAM、PMem 三層協同的架構,解決了由 PMem 固定訪問粒度引發的 I/O 放大與內存效率低下這一對核心矛盾。在實踐中,其在多種負載下的吞吐量相較當前方案平均提升 86.1% 至 257.6%,存儲流量大幅降低,內存佔用顯著優化,在多種負載中驗證了其卓越性能。
歡迎訪問 OceanBase 官網獲取更多信息:https://www.oceanbase.com/
