MiniMax 聯合華中科技大學首次開源了其視覺生成的關鍵技術 VTP (視覺分詞器預訓練) ,在不修改標準DiT的情況下,通過擴展視覺分詞器(Visual Tokenizers),實現了 65.8% 的生成性能提升。
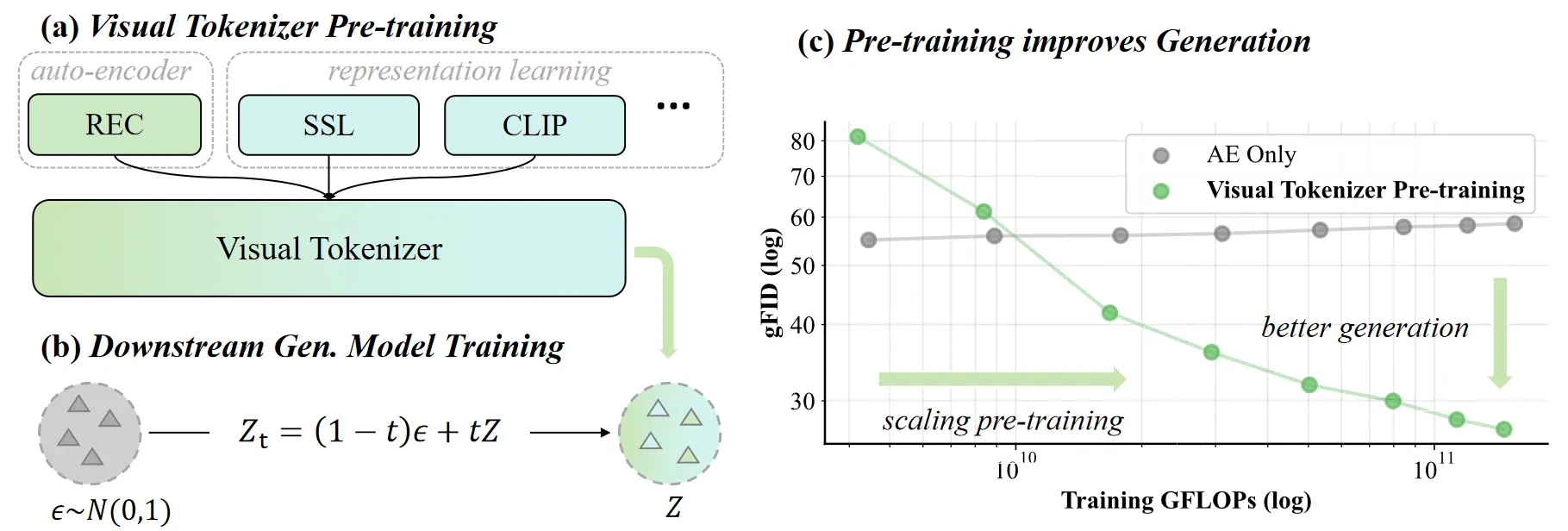
與很多tokenizer工作不同的是,VTP在設定上不對下游的主模型(DiT)訓練過程做任何修改,僅通過前置優化tokenizer來實現端到端生成性能的倍數提升。
VTP預訓練範式:
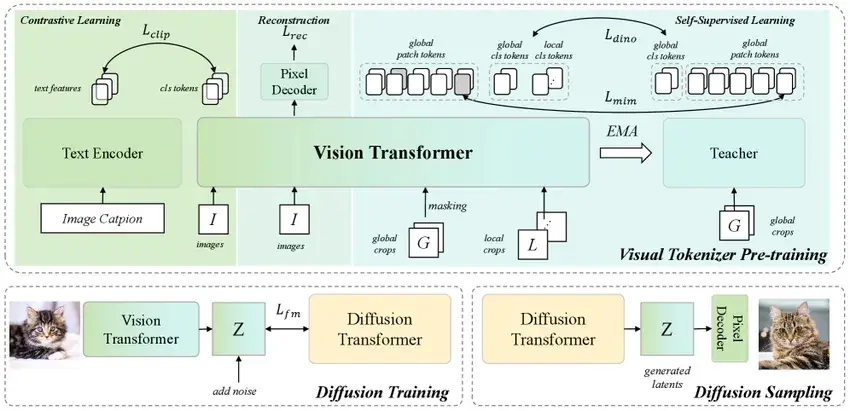
一句話來説——VTP把latents易學性和通用表徵學習建立起明確關聯,從而第一次將tokenizer作為scaling的主角,展現出全面的scaling曲線和擴展方向。VTP提供了一個全新的視角,指導我們除了在主模型上投入更多參數/算力/數據之外,還可以通過tokenizer的scaling來提升整個生成系統的性能。
代碼:https://github.com/MiniMax-AI/VTP
論文:https://arxiv.org/abs/2512.13687v1
