編者按: 現代大語言模型已經能夠一次性處理相當於整本書的文本量,但我們是否曾想過,當模型的"記憶"容量再擴展成千上萬倍,足以容納長達數月乃至數年的交互信息時,人工智能的能力邊界將會發生怎樣顛覆性的變化?
我們今天為大家帶來的文章,作者的核心觀點是:超長上下文推理的真正潛力,並不僅僅是處理海量文檔,更在於它為實現人工智能的"持續學習"和規模化"強化學習"這兩大關鍵瓶頸提供了革命性的突破路徑。
文章指出,超長上下文窗口能讓 AI 系統在部署後,通過"記憶"和"反思"過往的交互案例來不斷學習和糾錯,這是解決當前 AI 系統無法從經驗中成長這一核心障礙的關鍵。作者認為,強大的長上下文推理不僅能支持模型處理時間跨度更長的複雜任務(例如需要數月才能驗證的科研方向),還能通過驗證複雜的推理鏈條為模型提供高質量的訓練信號,甚至可以用來生成更逼真的強化學習訓練環境。
作者 | JS Denain and Anson Ho
編譯 | 嶽揚
從理論上講,現代大語言模型能夠一次性處理相當於多本書籍的文本量。以 Gemini 2.5 Pro 為例,其上下文窗口達到 100 萬 token,足以容納十本《哈利·波特與魔法石》的內容¹。但若能對更長的上下文進行大量推理呢?如果大模型可以接收 100 億 token 的上下文,並且我們具備使之可以實現的硬件與算法,又將如何?
最直接的應用場景自然是處理超長文檔[1]。但我們認為長上下文推理的意義遠不止於此:
- 其一,它為模型部署後持續學習新知識提供了突破口 ------ 而這也是當前人工智能系統在實際應用中的最大瓶頸之一。
- 其二,它能極大推動強化學習的擴展:實現更復雜的推理、驗證模型輸出,並生成高質量的強化學習環境。
- 但瓶頸依然存在。 隨着強化學習任務時長增加,研究迭代週期會放緩。同時還需要硬件與算法的雙重突破,確保長上下文推理不會因速度或成本問題而難以落地。
值得注意的是,上下文長度正以每年 30 倍的速度增長[2],前沿大模型利用上下文的能力也在快速提升。即便這種趨勢稍有放緩,這些重大突破也極有可能在不久的將來成為現實。
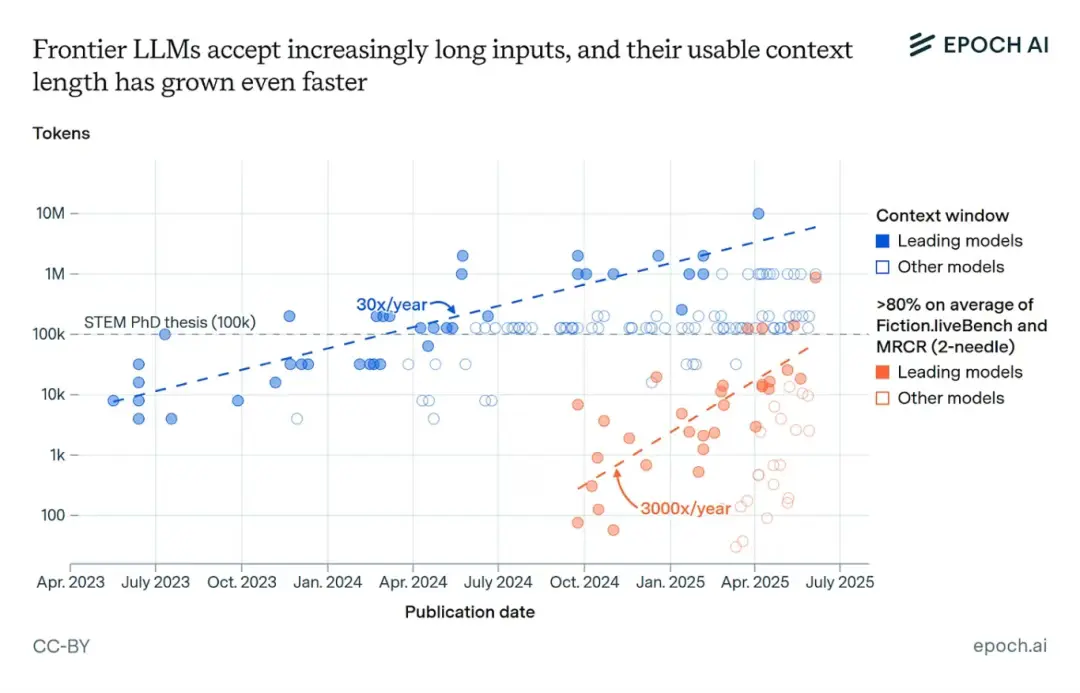
01 超長上下文推理為持續學習提供了突破口
要使大語言模型真正具備經濟價值[3],它們很可能需要"持續學習"的能力,即在模型部署後仍能不斷吸收新知識²。這種能力對於幫助 AI 系統從犯過的錯誤中學習或培養研究直覺[4]非常重要。但當前的大模型缺乏能在長對話或多輪交互中保留的"記憶"。
部分問題在於,當前大模型的上下文窗口不夠長,難以支撐有效的持續學習。 舉例來説,若通過截圖記錄工作歷程,100 萬 token 的上下文僅能支持 AI Agent 執行半小時的電腦任務 ------ 遠不足以獲取大量隱性知識³。但更長的上下文能帶來質變:1000 萬 token 可覆蓋約 6 小時的電腦使用記錄,而 100 億 token 便能延伸至八個月!更樂觀地看,若僅憑文本和音頻 token 就能表徵工作經驗,約 4000 萬 token 或許已足以積累數月的"工作經驗"⁴。
一旦擁有超長上下文,模型便能直接從上下文窗口中的過往案例學習。例如,推理模型已展現出在思維鏈中自我糾錯[5-6]的能力,將這些習得的修正方案保留在上下文中,將有助於模型未來解決類似問題。
這種"超大上下文窗口+上下文學習"的持續學習路徑已被探討多次。比如 Aman Sanger 在與 Cursor 團隊交流時曾提及這一方向[7],Andrej Karpathy 也在 X 平台上勾勒過其實現框架[8]:

(譯者注:這個框架的核心邏輯大概是,模型在完成任務時,先試幾次 ---> 記錄每次的結果和評估分數 ---> 用一個"反思提示詞"讓模型自己總結經驗 ---> 把經驗寫成"lesson" ---> 存起來,下次遇到類似任務時用上 ---> 不斷迭代優化。)
不過,有人可能會質疑這種方法[9],理由是隱性知識很難存儲在基於先前上下文的文本摘要中 ------ 這會導致關於任務執行過程的豐富信息大量丟失。這種擔憂確有道理,但未必能否定該路徑的可行性。
首先,如果上下文窗口比現有模型大幾個數量級,我們就有可能對上下文進行深度優化。這有望克服經驗壓縮中的信息損耗問題。例如,假設有一個大語言模型能夠存儲相當於數月工作內容的上下文,我們可以結合"sleep-time compute"[10]機制:讓模型利用(可預設的)空閒時間,將新獲取的信息與既有知識建立關聯進行學習。通過大量推理計算和強化學習優化後,所產生的學習上下文可能極為高效。當前模型通過強化學習已顯著提升了對上下文的利用效率,而正如下一節將探討的,這方面仍有巨大提升空間。
如果問題在於以文本形式存儲信息,長上下文還可以與業界積極研究的其他方案結合。例如,token 可作為多種模態信息[11]的通用表徵載體;又或者,隱性知識可以存儲在經過學習的 KV 緩存[12]中,形成比文本摘要更密集的知識表徵。
當然,這些技術能否真正奏效,不僅取決於紙上談兵地擴大上下文窗口尺寸,還需要建設配套基礎設施,確保相關上下文(例如近期所有工作交互記錄)都能被數字化並輸入大語言模型[13]。
我們同樣需要關注長上下文在實際應用中的效果 ------ 即便模型理論支持 100 萬 token 的上下文窗口,但在遠未達到該長度時,其輸出就可能已經開始混亂。 以 Vending Bench 基準測試[14]為例:模型需要運營自動售貨機賺取利潤,但往往在理論上下文窗口遠未填滿時就出現"失控",產生鉅額虧損。在實際使用大語言模型時我們也能觀察到類似現象:模型在長對話中會對先前的錯誤過度關注,導致用户不得不開啓新對話重新開始。
02 能夠執行大量長上下文推理有助於強化學習的規模化擴展
要確保模型在長上下文窗口中保持邏輯連貫,一種方法是延續當前強化學習與測試時計算擴展的技術路線。例如,採用一定程度的端到端強化學習訓練 ------ 這種方法已為 OpenAI 的 Deep Research 系統[15]等產品提供了助力。它能提供訓練信號,幫助模型在迴應用户的長查詢時保持前後一致性。
強大的長上下文推理能力正是強化學習持續擴展的重要支撐。原因之一在於它支持更長的決策軌跡[16]:更大的上下文窗口允許模型對耗時任務[17]輸出更長的推理鏈條。
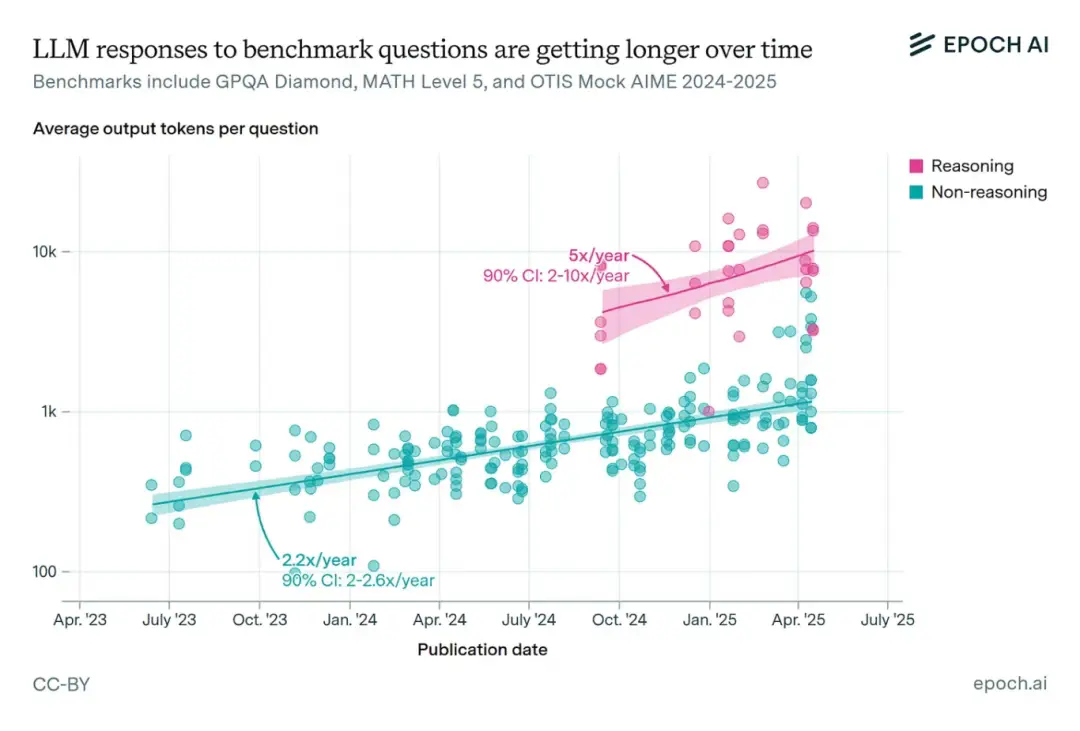
各基準測試中模型的回答正變得越來越長,尤其是通常經過強化學習訓練[18]的推理模型。這進一步加大了對長上下文推理的需求。
隨着大模型應用於更復雜的長週期任務,它們可能越來越多地面臨"稀疏獎勵"問題 ------ 即模型很難獲得明確的行為反饋信號。 例如在 AI 研發中選擇研究方向時,可能需要數月時間提出假設、設計和實施實驗,才能最終判斷出研究策略的優劣。對於此類任務,不僅單次決策軌跡長,更需要大量重複嘗試[19] ------ 這能增加至少出現一次成功軌跡的概率,為模型提供學習範本⁵。
長上下文推理還能通過驗證長模型輸出所需的複雜思維鏈,為推理模型提供高質量獎勵信號⁶。高質量驗證機制對 AI 的發展一直至關重要,OpenAI 用於改進 GPT-5 的"Universal Verifier[20]"就是明證。
此外,長上下文推理有助於生成強化學習環境(或其中的組成部分)。如 Kimi K2 的訓練[21]就融合了 MCP[22] 服務器,利用大模型自動生成大量模擬的"工具"、"智能體"、"任務"和"對話記錄"來為後訓練階段創建高質量的數據⁷。這個過程催生了長上下文推理的新需求場景,未來很可能擴展到強化學習任務的創建。當前這類環境大多通過程序化生成,但我們預期其質量將持續提升[23]。而要構建更高質量的強化學習環境,有效運用長思維鏈或智能體交互變得愈發關鍵,這正是長上下文能力的用武之地。
具體而言,我們認為長上下文推理能在擴展推理模型能力邊界方面發揮關鍵作用,使其勝任持續數週甚至數月的長週期任務。如果這種強化學習擴展能帶來類似去年推理模型的進步幅度,其影響將不可估量。
03 瓶頸:研究迭代速度放緩與潛在成本上升
這些強化學習的擴展和持續學習能力的實現,都需要付出代價。在發展道路上存在着諸多瓶頸和限制。
其中一個瓶頸是根本性的 ------ 當 AI 模型執行單次推理任務的時間被拉長到數週甚至數月時,會直接拖慢整個科研的迭代速度,從而延緩技術創新的進程。 Noam Brown 在 Latent Space 播客[24]中犀利指出:
"隨着模型思考時間的延長,你會受到實際時鐘時間(wall-clock time)的制約。當模型能夠即時響應時,實驗迭代非常輕鬆。但當它們需要三小時才能迴應時,難度就完全不可同日而語了。
[...]
雖然可以在一定程度上將實驗並行處理,但多數情況下,你必須先運行並完成當前實驗、看到結果後,才能決定下一組實驗的方向。我認為這恰恰是 AI 研發需要長週期的最有力佐證"
另一大瓶頸在於成本。即便在理論上能實現長上下文推理,最終能否投入使用還要看成本是否可承受。 需要硬件與推理算法[25]的雙重突破,否則模型運行速度可能慢到無法接受,成本也會高昂得難以承受。成本問題已現端倪 ------ Google DeepMind 就曾因高昂的成本[26]主動放棄發佈具備 1000 萬 token 上下文能力的 Gemini 1.5 Pro。
但總體而言,我們相信賦予語言模型長上下文推理能力將具有重大意義。它不僅能夠將現有的推理範式推向新的高度,也能為 AI 系統賦能關鍵能力,使其在真實場景中發揮實用價值。儘管需要付出一定代價,但這些瓶頸並非不可逾越。結合當前上下文長度的增長趨勢與資源投入力度,這些影響可能很快就會顯現。
本文諸多觀點受 Will Brown 的啓發,特此致謝。同時還要感謝 Lynette Bye 在寫作方面提供的寶貴建議,以及 Josh You 和 Jaime Sevilla 的反饋意見。
1 《哈利·波特與魔法石》約含 7.5 萬個單詞[27],即約 10 萬 token。
2 需注意,某些持續學習的定義[28]明確包含對新數據的訓練(即更新模型參數)。我們採用更寬泛的定義而不限定具體機制,因為我們主要關注模型在上下文環境中持續處理新信息的能力。
3 此計算基於每圖像約 250 token[29]、每秒 2 幀的設定。在 100 萬 token 的上下文窗口下,可處理時長約為 1,000,000 / (250 * 2) = 2000 秒(約 30 分鐘)。實際場景中可能需要更多 token,尤其在文本密集的計算機操作流中 ------ 但這反而凸顯了長上下文推理能力的重要性。
4 例如,假設一人每日閲讀 3 萬 token 文本(約合三篇論文),其思維速度與語速同步(每分鐘 125 詞),且每日工作場景中保持 6 小時思考,則對應新增 4.5 萬詞(6 萬 token)。日總量約 10 萬 token,年累積量約為 12×30×100,000 ≈ 3500 萬 token。實際數值可能更高,因為人類思維速度通常遠超語言表達速度。
5 其他方法同樣有效。例如在研究過程中設置階段性獎勵[30],可加速模型學習。
6 獎勵信號未必僅基於最終結果 ------ 基於過程的獎勵[31]同樣具有促進作用。
7 相關案例包括阿里通義實驗室的 AgentScaler[32],其提出了構建智能體任務環境的標準化流程。
END
本期互動內容 🍻
❓要實現"數月工作經驗"的上下文,文章指出面臨成本和迭代速度兩大瓶頸。你認為,在"算力成本下降"和"算法效率突破"之間,哪個是更快破局的關鍵?
文中鏈接
[1]https://cloud.google.com/transform/the-prompt-what-are-long-context-windows-and-why-do-they-matter
[2]https://epoch.ai/data-insights/context-windows
[3]https://www.dwarkesh.com/p/timelines-june-2025
[4]https://epoch.ai/frontiermath/expert-perspectives
[5]https://huggingface.co/blog/NormalUhr/deepseek-r1-explained
[6]https://openai.com/index/learning-to-reason-with-llms/
[7]https://www.youtube.com/watch?app=desktop&v=sLaxGAL_Pl0&t=2880s
[8]https://x.com/karpathy/status/1944435412489171119
[9]https://www.dwarkesh.com/p/timelines-june-2025
[10]https://www.letta.com/blog/sleep-time-compute
[11]https://arxiv.org/abs/2405.09818
[12]https://arxiv.org/abs/2506.06266
[13]https://www.interconnects.ai/p/contra-dwarkesh-on-continual-learning
[14]https://arxiv.org/abs/2502.15840
[15]https://www.youtube.com/watch?v=bNEvJYzoa8A
[16]https://epoch.ai/data-insights/output-length
[17]https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
[18]https://epoch.ai/gradient-updates/how-far-can-reasoning-models-scale
[19]https://www.youtube.com/watch?v=sLaxGAL_Pl0&t=330s
[20]https://www.theinformation.com/articles/universal-verifiers-openais-secret-weapon?rc=spkbjw
[21]https://arxiv.org/abs/2507.20534
[22]https://www.anthropic.com/news/model-context-protocol
[23]https://www.mechanize.work/blog/cheap-rl-tasks-will-waste-compute/
[24]https://www.latent.space/p/noam-brown
[25]https://epoch.ai/data-insights/llm-inference-price-trends
[26]https://www.youtube.com/watch?v=NHMJ9mqKeMQ&t=980s
[27]https://jspotter.fandom.com/wiki/James_Potter_Series/Word_count_note
[28]https://www.ibm.com/think/topics/continual-learning
[29]https://web.archive.org/web/20250903220857/https://ai.google.dev/gemini-api/docs/video-understanding
[30]https://arxiv.org/abs/2501.07301
[31]https://www.interconnects.ai/p/interviewing-ross-taylor-on-llm-reasoning
[32]https://arxiv.org/abs/2509.13311
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯繫獲取授權。
原文鏈接:
https://epochai.substack.com/p/the-huge-potential-implications-of