導讀
本文聚焦百度電商風控場景,針對傳統機審多模態識別弱、語義模糊難區分、審核體驗差等痛點,推進原有機審流程向AI化流程改造,基於業界MultiAgent範式在審核場景落地應用,提出 “多模態大模型 + 規則 + 知識庫” 協同的機審 Agent 方案。通過:1. 審核標準體系化、大模型化;2. 多模態大模型在領域典型問題上的抽象技術方案;3. 針對場景化問題精準優化。產出標杆式業務落地效果,為電商風控大模型落地提供可遷移能力強的技術方案。
01 背景與問題
1.1 背景
“百度優選”是百度旗下電商品牌,伴隨着近年百度電商的快速成長,在 “人、貨、場” 高速運轉的背後,風控體系始終面臨 “安全 - 效率 - 體驗” 的三角挑戰:
-
對平台:風控是 “生命線”若未能準確及時的管控風險,可能引發監管處罰、用户信任流失,甚至影響百度的商譽。
-
對商家:“快過審 + 明理由” 是核心訴求,在傳統人工審核流程中,商家提交信息後需等待2-4 小時(峯值期甚至 1 天),若被拒審僅收到 “內容違規” 的模糊反饋(在歷史的商家訪談中,部分不滿意指向了 “審核慢、理由不清”)。
-
對用户:“看到靠譜內容” 是關鍵,若平台出現了不可靠或者低質的信息,用户可能會因 “被騙” 損失利益,從而進一步導致用户的流失 。
作為百度電商風控技術團隊,我們的目標很明確:用大模型重構機審體系,實現 “全機審覆蓋 + 即時反饋 + 高可解釋性”,讓平台 “安全”、商家 “高效”、用户 “放心”。
1.2 面臨的問題
在大模型落地前,我們的傳統風控流程是 “商家提交→機審(規則+小模型過濾)→人審(人工判定)”,這種模式在業務快速增長下:
-
問題 1:人審瓶頸剛性,無法支撐業務增長
-
問題 2:機審能力薄弱,為保證風險不露出人審覆蓋面大,審核時效長(小時級,極端情況下甚至長達1天)
-
傳統機審依賴規則引擎(如關鍵詞匹配 “最佳”“第一” 判定虛假宣傳),但無法處理複雜場景:
-
多模態違規:主圖顯示 “Nike”品牌,詳情頁顯示為”山寨品牌“—— 規則無法識別圖文不一致;
-
模糊語義:“本品有助於睡眠”(合規)vs “本品治癒失眠”(違規)—— 規則無法區分 “程度差異”;
-
問題 3:審核體驗差,商家申訴率高
-
傳統機審拒審理由模糊,商家需反覆猜測修改方向。
為了解決上述提到的問題,本文將詳細介紹本次最佳實踐
02 技術方案
針對傳統流程的痛點,我們提出 “大模型 + 規則 + 知識庫” 協同的機審 Agent 方案,核心邏輯是:讓模型做 “語義理解”(擅長的事),規則做 “確定性判斷”(穩定的事),知識庫補 “外部信息”(精準的事)。
2.1 整體技術方案
流程上,我們重構了整個審核流程,實現了 “全機審覆蓋 + 即時反饋 + 動態校準”:
原流程 vs 新流程對比
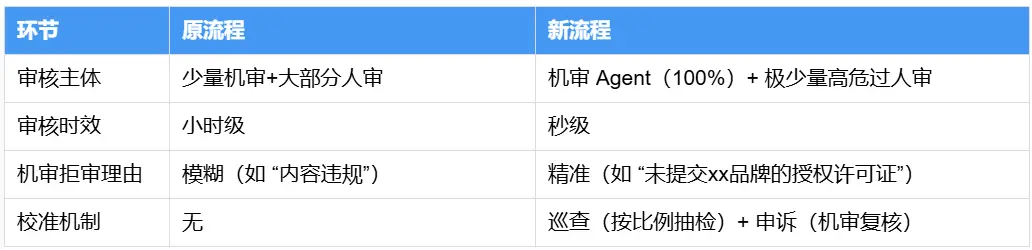
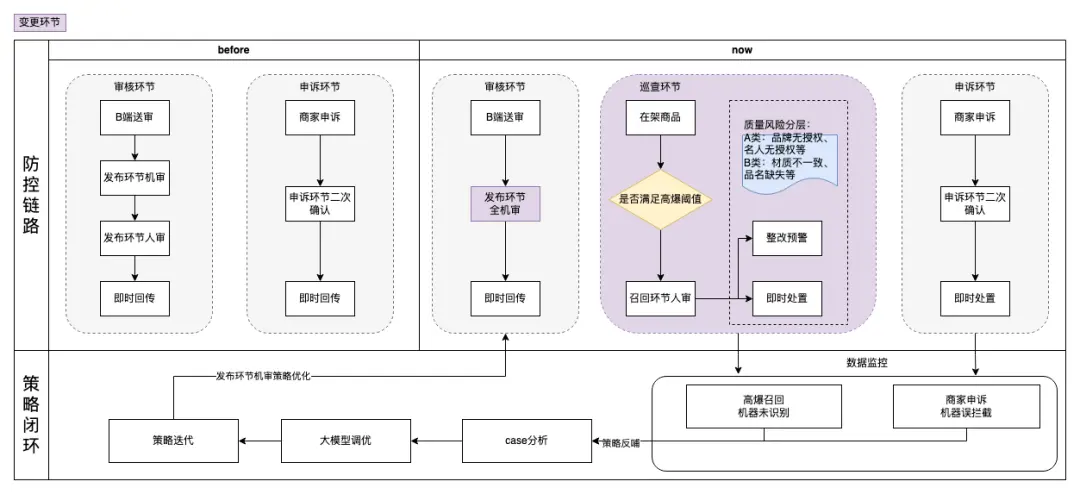
2.2 亮點
2.2.1 審核標準對齊
要實現全機審,“人審標準可量化” 是前提。我們通過 “風險梳理→標準優化→動態更新” 三步,將 700 餘個零散風險點整合成 24 組核心風險,覆蓋了95%+的線上違規問題。
步驟 1:風險點梳理 —— 做 “減法”
我們採集2025年Q1的全部人審記錄,
-
相似風險合併:採用層次聚類將相似違規進行歸類。
-
風險分層:對”風險嚴重程度“較低,且不直接影響商品價值和用户購買決策的風險暫時不納入機審(人工巡查覆蓋)。
-
長尾剪枝:對”發生頻率“較低的風險暫時不納入機審(人工巡查覆蓋)。
步驟 2:審核標準優化 —— “規範化”
我們把人審識別的風險劃分為三部分,明確違規/明確不違規/邊界樣本

步驟 3:動態更新 —— 做 “迭代”
我們每月例行巡查、回收商家申訴和人審處理數據,若發現新違規類型,則補充到風險組,及時更新線上機審agent。
2.2.2 基於多模態大模型的機審agent設計
大模型是機審 Agent 的 “大腦”,我們選擇大語言模型+多模態大模型為基礎,輔助知識庫(品牌授權庫、類目樹、資質庫),實現 “多模態理解 + 精準判定”。
輸入層:多模態數據整合
接收商家提交的全量商品數據,包括:
-
文本數據:商品標題、詳情頁描述、規格參數、商家資質名稱;
-
圖像數據:主圖、詳情圖、資質圖片(如《授權許可證》);
-
結構化數據:商家資質庫(如品牌授權記錄、進口報關單)、平台類目樹、風險規則庫。
特徵抽取層:多模態特徵融合
特徵抽取是機審的 “感知層”,我們採用 “規則抽取 + LLM 文本理解 + 多模態模型圖像理解” 的組合方式,覆蓋所有維度的商品信息:
-
規則抽取:用正則表達式提取標題中的品牌(如 “Nike”)、類目(如 “運動鞋”)、關鍵詞(如 “進口”);
-
LLM 文本理解:用文心大模型提取詳情頁中的模糊語義(如 “治癒失眠” 的違規表述)、邏輯矛盾(如 “進口商品” 但未提報關單);
-
多模態大模型圖像理解:使用多模態大模型模型識別主圖中的品牌 logo(如 Nike 的 Swoosh 標誌)、資質圖片中的 OCR 信息(如《授權許可證》編號)。
風險判定層:大模型 + 規則 + 知識庫協同
風險判定是機審的 “決策層”,核心邏輯是 “讓專業的模塊做專業的事”:
-
規則引擎處理確定性邏輯:針對 “絕對化用語”“資質必填項” 等確定性規則,直接用代碼判斷(如 “含‘進口’關鍵詞必須提交《進口報關單》”);
-
知識庫查詢外部信息:關聯商家資質庫、平台類目樹等領域知識(如查詢商家是否有 Nike 的授權記錄);
-
LLM 綜合判定:融合多模態特徵、規則結果、知識庫信息,輸出最終結論(如 “主圖含 Nike logo + 無授權記錄 → 品牌侵權違規”)。
輸出層:精準反饋 + 可解釋性
輸出層是機審的 “交互層”,需滿足商家的 “明理由、能整改” 需求:
-
審核結果:通過 / 拒絕;
-
拒審理由:自然語言描述(如 “您發佈的商品主圖含 Nike 品牌 logo,但未提交 Nike 品牌的《授權銷售許可證》”);
-
整改建議:輸出給發品端前端,提供自動整改能力(如刪掉對應違規位置違規信息)。
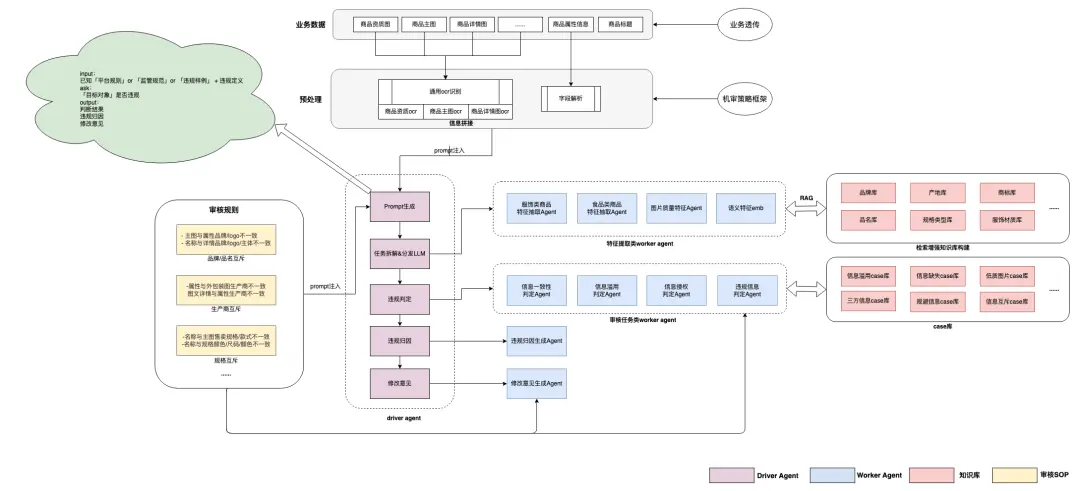
任務拆分:讓模型 “專注擅長的事”
我們將機審任務拆分為三類,以同時保證審核結果的高召回,高準確,清晰可解釋:
-
特徵抽取:提取商品的關鍵信息(如從主圖提取品牌 logo、從詳情頁提取材質等);
-
風險判定:規則引擎結合知識庫,判斷特徵是否違規(如 “logo 是 Nike,但無授權→侵權”);
-
理由生成:模型生成自然語言拒審理由(如 “未提交xx品牌的授權許可證,請補充”)。
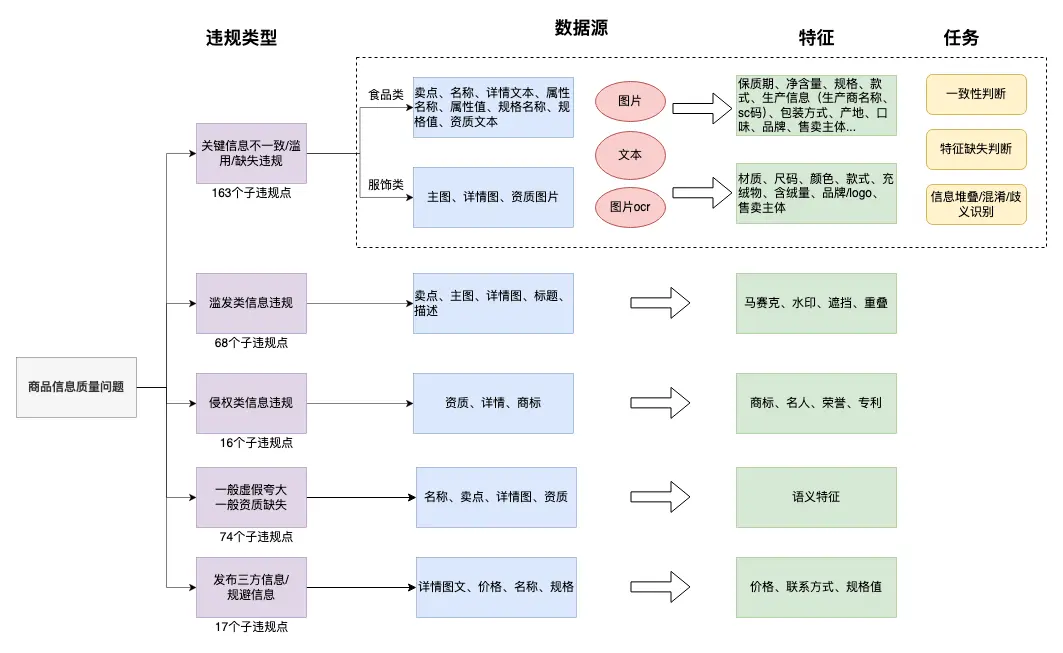
03 實踐案例
在典型問題的文本問題判定,圖片問題判定,圖文融合問題判定上,經過我們的技術方案演進,均可達到幾乎對標人審能力的效果。
3.1 資質缺失風險判定
場景描述
針對高危商品行業如三品一械行業,售賣相關商品時要求商家提供清晰可辨、且信息完整的對應資質(如《保健食品批准證書》、《國產特殊用途化妝品行政許可批件》、《醫療器械備案證明》、《委託進口協議》等)。
傳統流程痛點
-
規則策略:僅能檢查 “是否含‘進口’關鍵詞”,無法關聯商家資質庫,漏檢率高;
-
人審需人工查詢和核對資質,耗時長,易因 “漏看” 導致誤判。
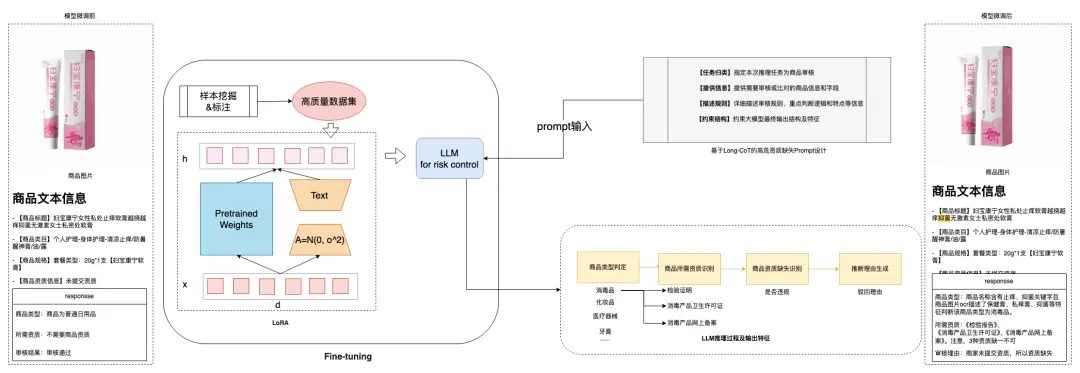
機審方案:領域微調 + Prompt Engineering
對於此類複雜判定類問題,領域知識深度深,我們基於基座模型進行了模型微調,通過高質量樣本收集 -> Prompt Engineering -> 數據增強 -> 模型微調 得到了專注於電商風控場景的領域AI模型
-
高質量樣本收集 :我們將真實場景下經人工核驗的高質量樣本沉澱為模型訓練語料。這一環節是模型訓練的核心,保障了訓練數據的真實性、多樣性,以及對各類場景的覆蓋豐富度。
-
Prompt Engineering:基於不同樣本類別,設計場景化提示詞,引導模型關注風控領域知識:
-
數據增強:我們採用SOTA思考模型,動態生成Cot並對生成內容進行精細化糾偏,提升模型的推理能力:
-
模型微調:對比百度自研文心基座模型和開源Qwen系列模型,我們分別對比和採用了全參數微調和指令微調方式,加速訓練過程,進一步提升模型效果,獲得風控領域專家模型。
3.2 品牌授權風險判別
場景描述
商家發佈的商品信息,涉及限售品牌,但實際未獲得品牌授權(易引發假貨投訴等體驗問題)
傳統流程痛點
-
“山寨 logo”較難以識別(如 “Nlke” 冒充 “Nike”);
-
授權書需人工手動核驗,耗時久,漏檢率較高;
-
管控品牌庫變動升級較多
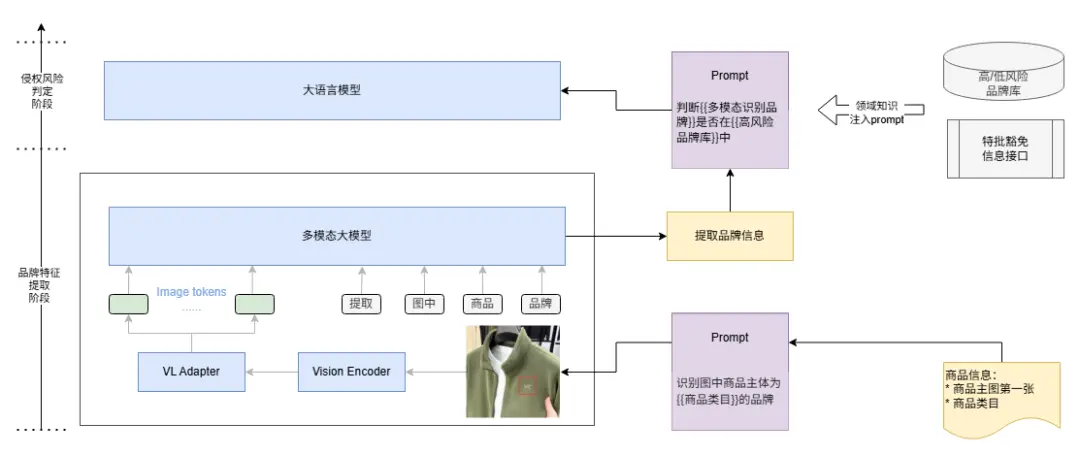
機審方案:多模態特徵匹配 + 知識庫關聯
採用 “多模態模型圖像識別 + LLM 字符相似度對比 + 知識庫查詢” 的方案:
-
多模態模型圖像識別:採用多模態模型提取主圖中的 logo 特徵;
-
知識庫查詢:關聯限售品牌庫,確認品牌是否限售,是否有授權記錄;
-
LLM 圖文信息融合判斷:確認提取品牌信息是否限售且無授權;
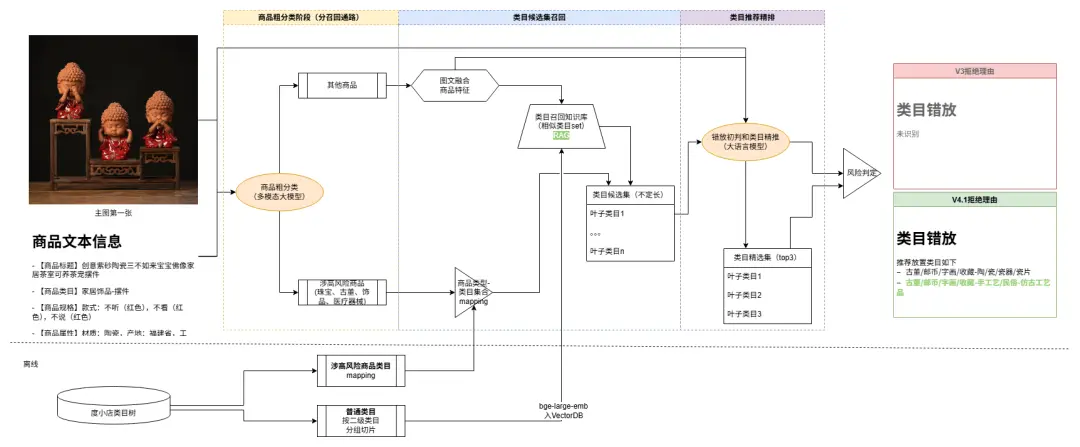
3.3 類目錯放風險判定
場景描述
1)因電商商業流量推薦等場景中列類目特徵權重極高,類目準確性嚴重影響流量變現效率;2)平台佣金政策和資質/定向准入等管控要求與類目強關聯;因此要求商家發佈商品必須選擇到平台類目體系內最準確的類目;
傳統流程痛點
-
圖文特徵融合困難:傳統方案一般僅使用標題識別類目,商家對抗後容易繞過機審
-
平台類目龐雜:審核員需非常瞭解平台近5000個類目結構,極容易誤審
方案演進
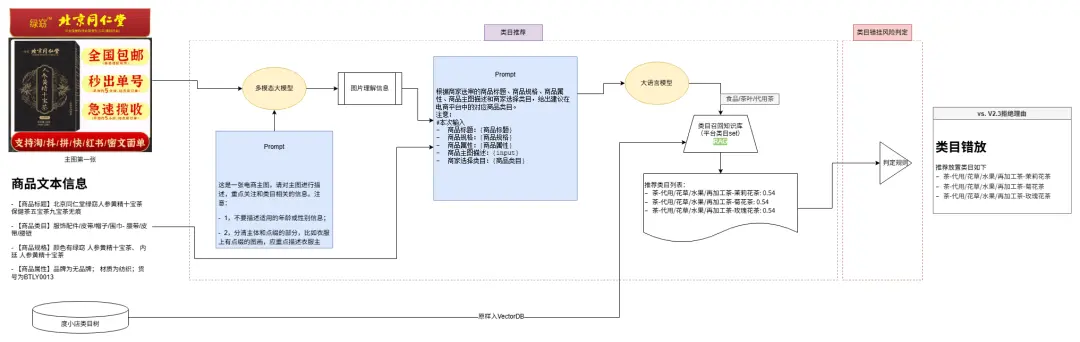
方案一:基礎方案
- 圖文特徵融合推薦平台top相似度類目
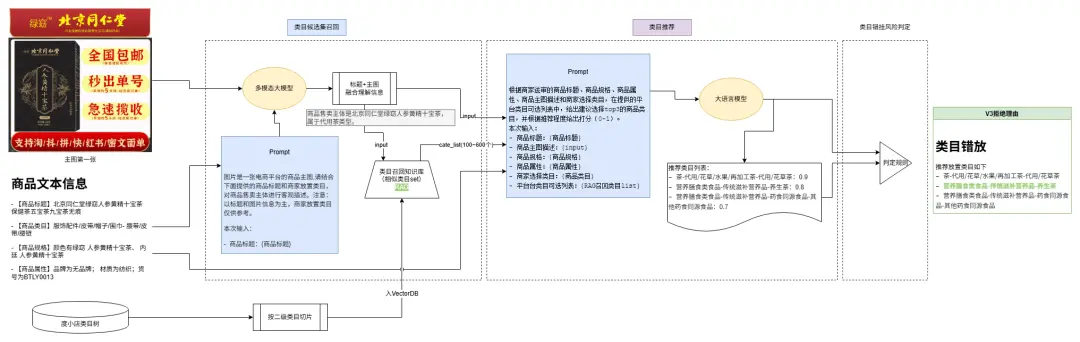
方案二:解決類目推薦不準確問題
-
改為召回+rank 兩階段方案,提升精準選擇類目可能性
-
升級相似度計算模型為bge-large-emb,解決部分情況下相似度召回精準不足問題
方案三:解決部分高風險商品在第一輪候選集召回不足問題
-
增加定向召回通路,提升高風險商品召回能力
-
升級風險判定方案,結合大模型判定和識別規則,進一步提升精準判別能力
04 總結與展望
4.1 落地效果
超預期的 “三升三降”
三升
-
機審覆蓋率提升
-
審核時效提升
-
商家滿意度提升
三降:
-
人審量減少
-
申訴率減少
-
用户投訴率減少
4.2 經驗總結
大模型不是 “取代人”,而是 “解放人”—— 讓審核人員從 “重複勞動” 轉向 “標準制定、風險預判”。
本次落地實踐較為成功的要點
-
多模態融合:電商數據 80% 是多模態的,單模態模型無法覆蓋所有場景;
-
可解釋性優先:大模型的自然語言生成能力是提升商家體驗的關鍵 —— 傳統規則的 “內容違規” 無法讓商家整改,而 LLM 生成的 “未提交 Nike 授權許可證” 能直接指向問題,進一步的我們業務團隊為商家提供了一鍵整改功能,大大提升商家使用平台工具的滿意度;
-
閉環迭代:用巡查、申訴數據持續優化模型,形成 “數據→模型→效果提升” 的飛輪;
4.3 展望
agent的自我優化:利用大模型生成能力生成難樣本,解決風控場景的大難題——小樣本問題,輔助少量人工干預使得agent自我演進和優化。
05 結語
過去的1年裏,大模型技術突飛猛進的發展,為電商風控帶來了 “質的飛躍”—— 從 “被動堵風險” 轉向 “主動防風險”。在百度電商風控技術的實踐中,我們乘着時代的技術紅利,落地 “多模態大模型 + 規則 + 知識庫” 解決了傳統機審的痛點,實現了 “平台安全、商家高效、用户放心” 的平衡。未來,我們將繼續探索 “AI + 風控” 的邊界,提供可快速遷移的大模型落地方案。