清華大學與快手可靈團隊合作推出了一款名為 SVG(無 VAE 潛在擴散模型)的新型生成模型。此次創新不僅在訓練效率上實現了6200% 的驚人提升,而且在生成速度上更是達到了3500% 的飛躍。
VAE 在圖像生成領域的衰退,主要源於其存在的 “語義糾纏” 問題。也就是説,當我們嘗試僅僅改變圖像中某一特徵(如貓的顏色)時,其他特徵(如體型、表情)往往也會受到影響,導致生成的圖像不夠精準。為了解決這個問題,清華與快手的 SVG 模型採取了不同的策略,主動構建了一個融合語義與細節的特徵空間。
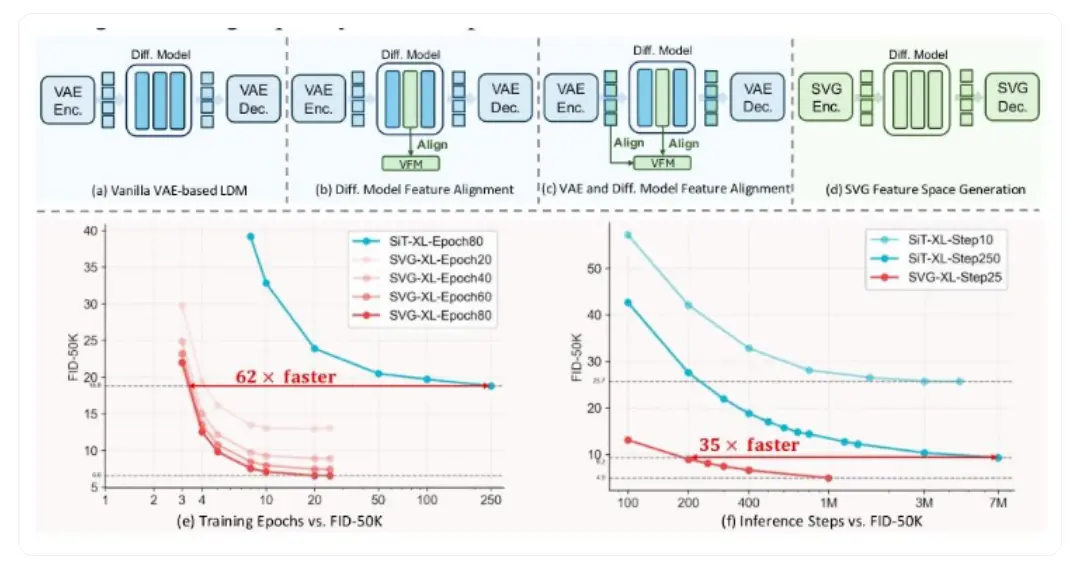
在 SVG 模型的設計中,團隊首先使用 DINOv3預訓練模型作為語義提取器,該模型經過大規模的自監督學習,能夠有效識別和分離不同類別的特徵,解決了傳統 VAE 模型中的語義混亂。此外,為了補充細節,團隊還特別設計了一個輕量級的殘差編碼器,確保細節信息不會與語義特徵相沖突。關鍵的分佈對齊機制則進一步增強了這兩種特徵的融合,保證了生成圖像的高質量。

實驗結果表明,SVG 模型在生成質量和多任務通用性方面,全面超越了傳統的 VAE 方案。在 ImageNet 數據集上,SVG 模型在僅訓練80個週期時,FID 值(衡量生成圖像與真實圖像相似度的指標)達到6.57,遠超同規模的 VAE 模型;而在推理效率上,SVG 模型也顯示出卓越的性能,在較少的採樣步驟下即可生成清晰圖像。此外,SVG 模型的特徵空間還可直接用於圖像分類、語義分割等多種視覺任務,無需額外微調,大大提高了應用的靈活性。