據通義大模型官方消息,通義百聆宣佈其語音大模型Fun-CosyVoice3與Fun-ASR完成重大升級並同步開源。此次升級聚焦核心性能與實用性,為開發者與企業提供更強大的語音AI工具。
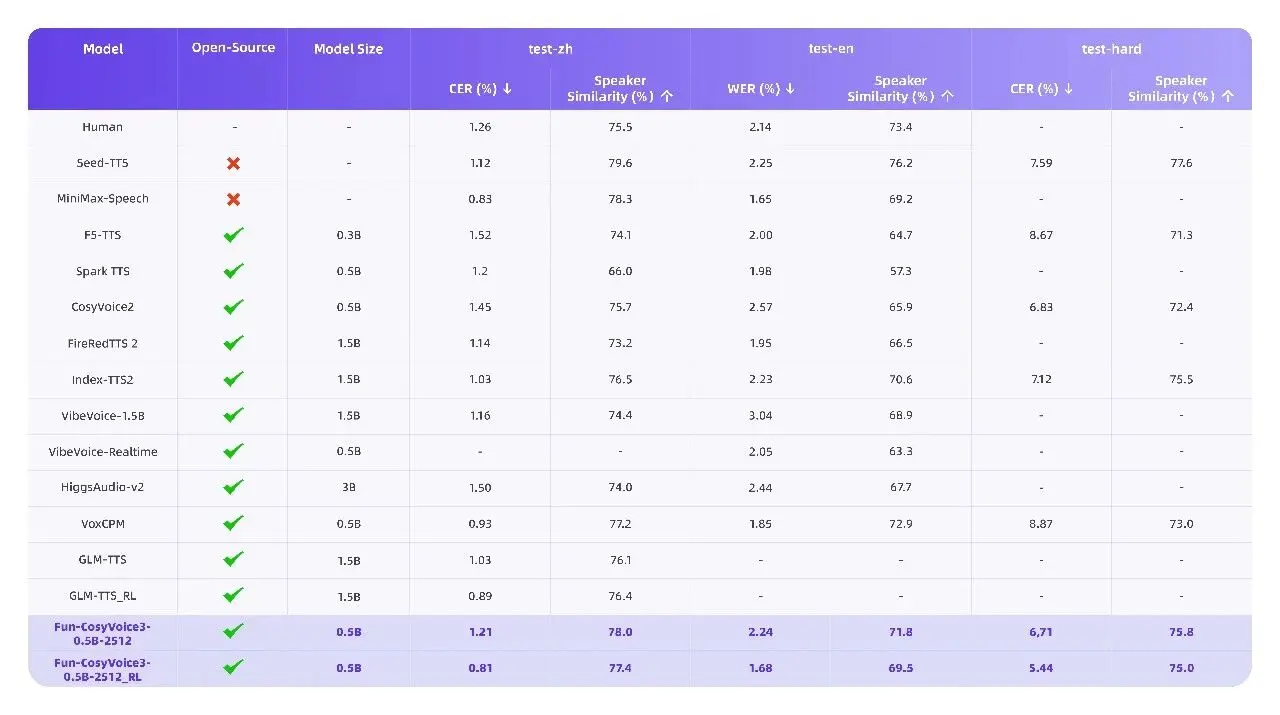
Fun-CosyVoice3:實時、精準的語音合成
模型首包延遲降低50%,實現“輸入即發聲”。中英混説錯誤率大幅下降56.4%,並支持9種語言、18種方言及情感控制。其開源版本Fun-CosyVoice3-0.5B具備優秀的zero-shot音色克隆能力。
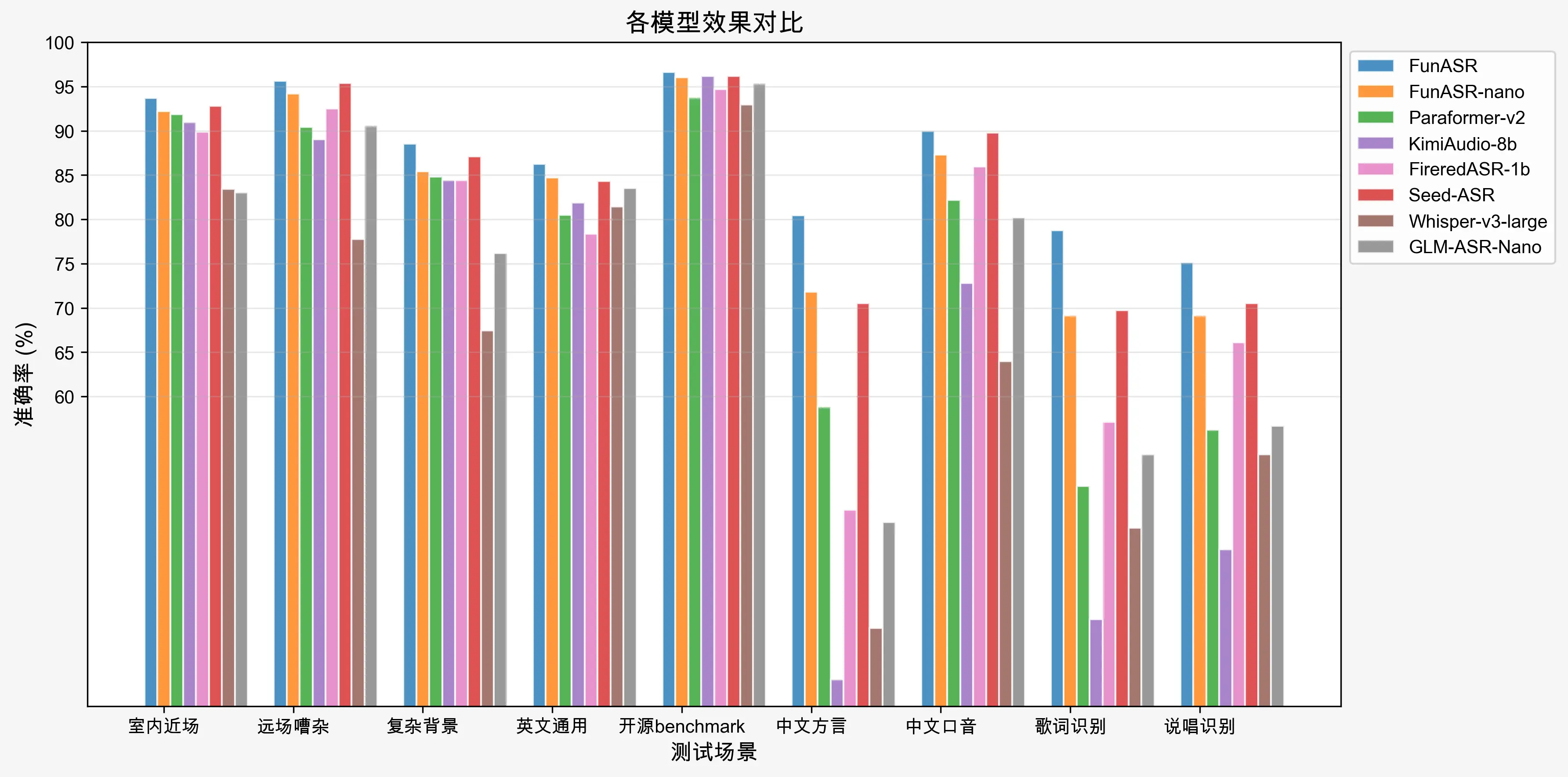
Fun-ASR:強悍抗干擾的語音識別
該模型在嘈雜環境下準確率達93%,新增歌詞與説唱識別功能。支持31種語言自由混説與多種中文方言,流式識別首字延遲僅160毫秒。輕量化版本Fun-ASR-Nano-0.8B同步開源,推理成本更低。
模型已在魔搭、HuggingFace及GitHub等平台開源,支持本地部署與二次開發。
https://github.com/FunAudioLLM/Fun-ASR(GitHub)
https://funaudiollm.github.io/funasr/(GitHub.io)
https://modelscope.cn/studios/FunAudioLLM/Fun-ASR-Nano/(國內體驗demo)
https://huggingface.co/spaces/FunAudioLLM/Fun-ASR-Nano(海外體驗demo)
https://modelscope.cn/models/FunAudioLLM/fun-asr-nano-2512(國內模型倉庫)
https://huggingface.co/FunAudioLLM/Fun-ASR-Nano-2512(海外模型倉庫)
