編者按: 在 RAG 系統中,一味追求更高維的嵌入模型真的意味着更好的性能嗎?
文章重點介紹了 MyClone 將原有 1536 維的 OpenAI text-embedding-3-small 模型替換為 512 維的 Voyage 3.5 Lite 嵌入模型,從而實現 RAG 延遲與存儲成本的大幅降低,還能在保持甚至提升檢索質量的同時,明顯改善用户體驗。
技術的選擇從來不只是參數的高低,更是與產品目標緊密對齊的戰略決策。在追求高效、輕量與實時響應的今天,適合的模型往往比複雜的模型更能推動用户體驗與業務價值的雙重提升。
作者 | MyClone Engineering Team
編譯 | 嶽揚

在 MyClone.is,我們的使命是打造真正個性化的數字人格。我們通過檢索增強生成(RAG)技術,為每位用户構建一個內容豐富、可交互的"知識分身" ------ 該分身基於用户上傳的文檔、筆記與知識庫,將它們編碼後存入向量數據庫,為聊天對話和語音助手提供支持。
01 數字人格需要快速、可靠的檢索
每當用户通過語音或文字與自己的數字人格互動時,系統都會在毫秒級時間內,基於這些向量做 RAG 檢索,精準鎖定知識庫中最相關的知識片段,並用"像本人"的語氣作答。在這一架構中,嵌入模型處於核心地位:它決定了系統對用户內容的理解深度、所需的向量存儲空間,以及相關信息的檢索與排序速度。畢竟,延遲是對自然對話最大的破壞。
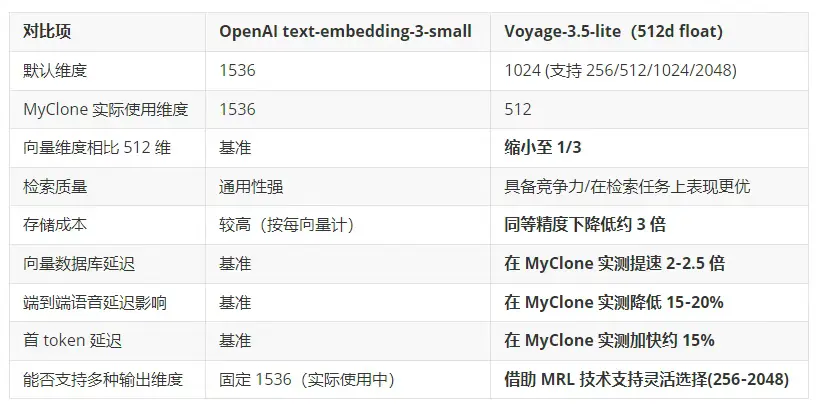
此前,MyClone 使用的是 OpenAI 的 text-embedding-3-small 模型,該模型生成 1536 維的浮點向量,專為通用語義相似度任務優化。該模型在常見檢索基準測試中表現出色,且價格相對低廉,但其默認的 1536 維向量尺寸相比低維替代方案,意味着更高的存儲和帶寬開銷。
在高吞吐量的 RAG 系統中,1536 維向量會大幅增加內存佔用、磁盤使用量和每次查詢的 I/O 負載。隨着用户數量和知識條目不斷增長,這可能成為延遲和成本方面的瓶頸。
我們最近在 RAG 流程中識別出這一瓶頸,並果斷採取行動:將 OpenAI 的 text-embedding-3-small(1536 維)替換為 Voyage-3.5 Lite(512 維)。這一改動大幅降低了存儲需求和延遲,同時在用户數字人格的檢索質量上不僅得以保持,甚至常常有所提升。 這類基礎設施的優化,為用户帶來了更快、更便宜、對話體驗更自然的 AI 助手。
接下來,讓我們深入探討一下這項優化。
02 為什麼 512 維的 Voyage 3.5 Lite 能媲美甚至超越 1536 維的 OpenAI 模型?
表面上看,從 1536 維降至 512 維像是一種妥協。維度更少,信息理應更少,檢索質量也該下滑。然而,嵌入模型領域正因諸如 Voyage AI 所採用的 Matryoshka Representation Learning (MRL) 等創新而飛速演進。
Voyage‑3.5‑lite 採用了 Matryoshka training 和量化感知(quantization‑aware)技術,其前 256 或 512 個維度便能捕獲絕大多數的語義信號,而非簡單地對高維向量進行粗暴截斷。公開基準測試和廠商數據表明,在降低維度後,Voyage‑3.5‑lite 仍能保持非常接近其完整維度版本的檢索性能,並與主流商業模型相媲美。
相比之下,OpenAI 的嵌入模型主要設計為固定輸出 1536 維,其降維通常是事後進行的(例如使用 PCA 或直接截斷),除非針對每個領域進行精細調優,否則可能會丟失信息。正因如此,在"成本與延遲敏感、質量又不能打折"的場景裏,Voyage-3.5-lite 顯得更具吸引力。
03 MyClone 更換嵌入模型帶來的收益
3.1 向量數據庫效率:省存儲空間,也省錢
最直接的收益體現在存儲層。通過將向量維度從 1536 降至 512,我們將存儲全部用户知識庫所需的向量數據庫存儲空間減少了約 66%。
- 影響:這直接轉化為更低的基礎設施成本和更小的系統整體佔用空間,使我們能夠更高效地支撐不斷增長的用户規模。
3.2 檢索速度:釋放 RAG 性能
向量數據庫依賴於計算查詢向量與數百萬個已存儲文檔向量之間的相似度(通常為餘弦相似度)。這種搜索的計算開銷與向量的維度大小正相關。
- 計算更快:向量維度大小縮減至 512/1536 ≈ 1/3,使得搜索索引時的核心數學運算大大加速。
- 負載更輕:從向量數據庫到 RAG 服務之間傳輸的向量更小,也進一步降低了網絡延遲。
這項優化使檢索延遲直接降低 50%(速度提升 2 倍)。
3.3 用户體驗提升:實現自然對話
對於主打語音交互功能的數字人格而言,每一毫秒都至關重要。用户提問後若出現明顯停頓,就會破壞"真實對話"的沉浸感。
檢索延遲的大幅下降直接提升了整個系統的響應速度:
- 端到端語音延遲:從用户説完話到數字人格開始迴應的總時間減少了 15% 至 20%。
- 首 Token 延遲:無論是文字對話還是語音界面,系統首次返回響應的時間平均縮短了 15%。 這個指標非常重要 ------ 它決定了用户多快能看到或聽到系統已開始處理其請求。
04 這兩款模型的並列對比圖
05 為什麼底層嵌入模型的選擇對數字人格來説非常重要
在數字人格平台中,用户滿意度與助手在聊天對話和語音交互中是否響應迅速、回答精準密切相關。更低的向量維度能有效降低檢索的尾延遲(tail latency),從而直接縮短"首 Token 延遲"(time to first token),讓語音對話更流暢自然,減少了"機器人般的停頓感"。
與此同時,用户又期待數字人格能準確回憶自己上傳的知識內容。這意味着,任何旨在節約成本的優化,都不能犧牲檢索質量,也不能引發幻覺(hallucinations)。Voyage‑3.5‑lite 專為檢索場景而設計,使 MyClone 能夠在"輕量級檢索架構"和"高保真知識錨定"之間取得理想平衡。
06 此次優化為 MyClone 帶來的業務與產品價值
從產品與業務角度來看,這次嵌入模型的優化帶來了多重優勢:
- 在大規模場景下提供更優的用户體驗:更快的響應速度提升了用户對系統"智能感"和"可信度"的感知,尤其是在語音交互中 ------ 人類對延遲極其敏感。
- 數字人格的基礎設施成本更低:3 倍的存儲空間節省加上更快的查詢速度,意味着向量數據庫和計算資源的成本更低,MyClone 能在相同預算下託管更多用户知識。
- 給更多、更復雜的功能預留空間:節省下來的延遲與成本可重新投入更復雜的 RAG pipeline,例如更強的重排序(reranking)或多步推理(multi‑step reasoning),而不會超出用户可接受的延遲上限。
- 面向未來的靈活性:Voyage‑3.5‑lite 支持多維度輸出與多種量化方案(如 int8、binary 等),為諸如"超低成本的歸檔存儲"或"混合了二進制向量加浮點向量的檢索策略"等進一步的優化敞開了大門。
對 MyClone 而言,這些收益是疊加放大的:每位用户的數字人格都能引用更多文檔、響應更快、運行成本更低,同時始終忠於用户本人的語言風格、表達習慣與知識內容。
07 戰略層面的啓示
從 OpenAI 的 1536 維嵌入模型切換到 Voyage‑3.5‑lite 的 512 維嵌入模型,表明嵌入模型的選擇本質上是一項產品決策,而不僅僅是基礎設施細節。 通過將嵌入模型與大規模 RAG 的核心需求(快速、低成本、高語義質量的檢索)對齊,MyClone 一舉提升了用户體驗與單位經濟效益。
隨着 RAG 系統走向成熟,像 Voyage‑3.5‑lite 這類明確針對"按需選用嵌入維度"、"支持多種量化方案"與"檢索質量"進行優化的嵌入模型,將在數字人格這類對延遲敏感、知識密集型的產品中,成為默認選擇。
END
本期互動內容 🍻
❓在你們的 RAG 系統中,選擇嵌入模型時最優先考慮哪個指標?是延遲、成本、檢索質量,還是易於集成?
原文鏈接:
https://www.myclone.is/blog/voyage-embedding-migration/
