編者按: 在構建基於大語言模型的 RAG 系統時,您是否曾思考過:究竟哪種表格數據格式能讓 LLM 最準確高效地理解和提取信息?
我們今天為大家帶來的文章,作者通過一項對照實驗指出:表格格式對 LLM 的理解能力有顯著影響,其中 Markdown-KV 格式在準確率上表現最佳,但也伴隨着更高的 token 消耗。
文章詳細介紹了作者針對 GPT-4.1-nano 模型進行的對照實驗,測試了包括 CSV、JSON、Markdown Table、YAML 等在內的 11 種常見表格格式,使用 1000 條員工記錄和對應問題,系統性地評估了各種格式在準確率和 token 消耗兩個維度的表現。研究發現,雖然 Markdown-KV 格式準確率最高(60.7%),但也消耗了更多 token,而常見的 CSV 和 JSONL 格式表現不佳。
作者 | Improving Agents
編譯 | 嶽揚
在討論基於 AI 的系統的可靠性時,有一個簡單卻常被忽視的問題:究竟用什麼格式向大語言模型傳遞表格數據最合適?
應該用 Markdown table 還是 CSV?
選 JSON 抑或是 YAML?
或者有沒有其他格式比上述這些都更優?
01 為什麼這個問題很重要
當前許多 RAG pipeline 都需要處理含表格的文檔,並將這些表格信息輸入大語言模型。
1.1 系統準確性
若未能以易於大語言模型解析的格式呈現表格信息,可能會降低整個系統的準確性。
1.2 Token 成本
某些格式表示相同數據所需的 token 數量可能是其他格式的數倍。如果你按處理的 token 數量付費,那麼格式的選擇將直接影響你的 LLM 推理成本。
02 我們的實驗方法
我們設計了一個對照實驗,測試數據格式如何影響 LLM 回答該數據相關問題的準確性。
測試過程包含向大語言模型輸入 1000 條記錄,要求其根據數據回答問題,隨後逐條評估是否回答正確。
我們針對 1,000 個問題,分別使用了 11 種不同的數據格式重複了這一過程。
- 數據集:包含 8 個屬性(ID、姓名、年齡、城市、部門、薪資、工作經驗、項目數量)的 1000 條虛擬員工記錄
- 問題設置:1000 個針對具體數據點的隨機查詢
- 測試模型:GPT-4.1-nano
- 格式驗證:11 種不同的數據呈現格式
2.1 示例問答對
問:"Grace X413 有多少年工作經驗?(只需返回數字,例如'12')"
答:"15"
問:"Alice W204的薪資是多少?(只需返回數字,例如'85200')"
答:"131370"
2.2 實驗方法説明
我們選擇向大語言模型傳遞相對大數量的記錄來測試其極限。在實際應用中,處理大型結構化數據集時,通常需要對其進行分塊處理和通過查詢提取最相關的記錄或信息,僅將精簡後的上下文內容傳遞給大語言模型。
使用包含表頭的表格格式(如 CSV、HTML table 和 Markdown table)時,建議定期重複表頭(例如每 100 條記錄重複一次)以增強理解。 為簡化實驗流程,本次實驗未採用該做法。
03 大語言模型對不同表格格式的理解程度如何?
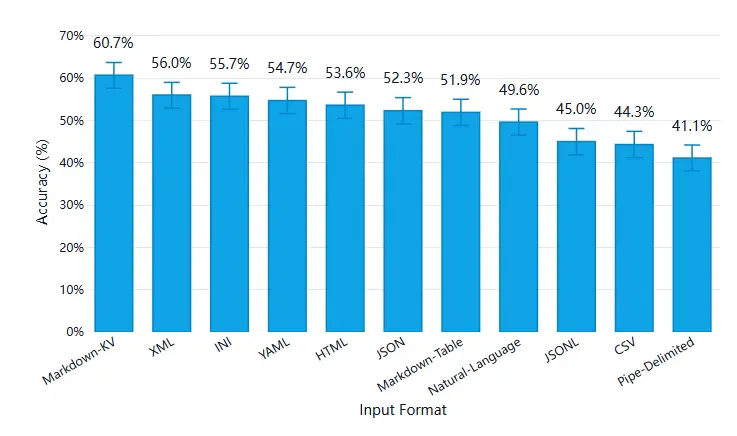
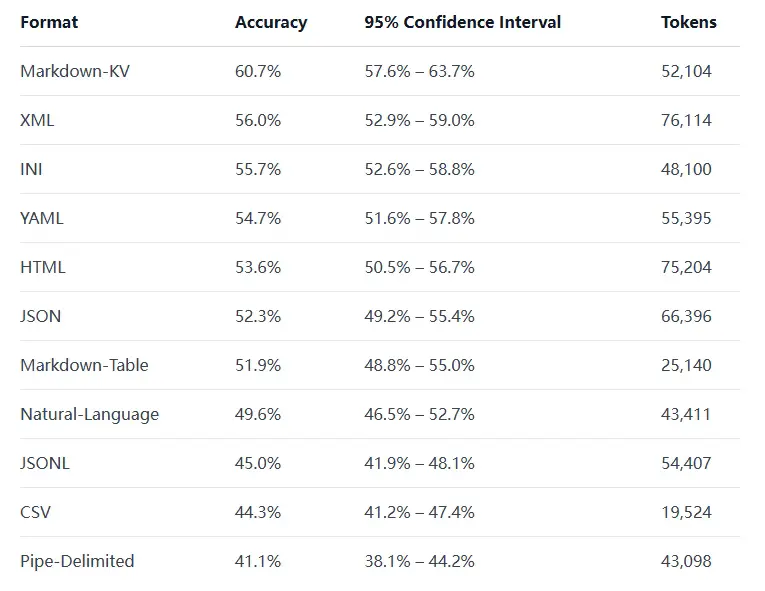
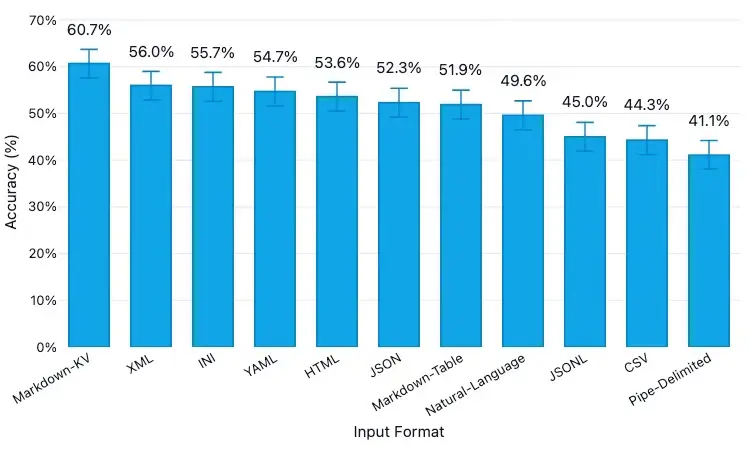
04 Highlights
- 表格格式似乎很重要:我們在不同格式之間觀察到了明顯的理解差異。
- CSV 和 JSONL 表現不佳:如果你目前默認使用其中一種格式,更換格式可能帶來立竿見影的改進效果。
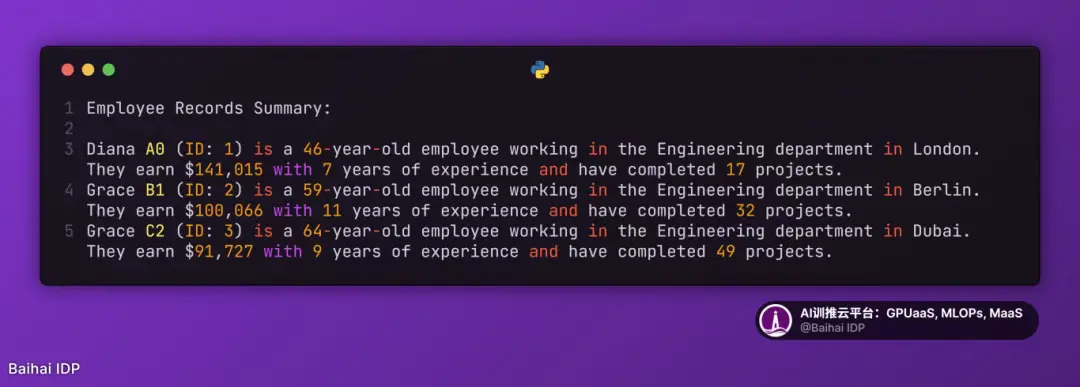
- Markdown-KV 表現最佳,準確率達到 60.7%,比 CSV 高出約 16 個百分點。(Markdown-KV 是我們對一種非標準化格式的稱呼,該格式在 Markdown 中使用"key: value"鍵值對。)
- 提升準確率需要以 token 的消耗為代價:表現最佳的 Markdown-KV 格式所使用的 token 數量是 token 效率最高的格式(CSV)的 2.7 倍。
4.1 準確率與 token 成本的權衡
下圖可視化了準確率與 token 使用量之間的關係(採用對數刻度),有助於説明這兩個關鍵指標之間的平衡關係:
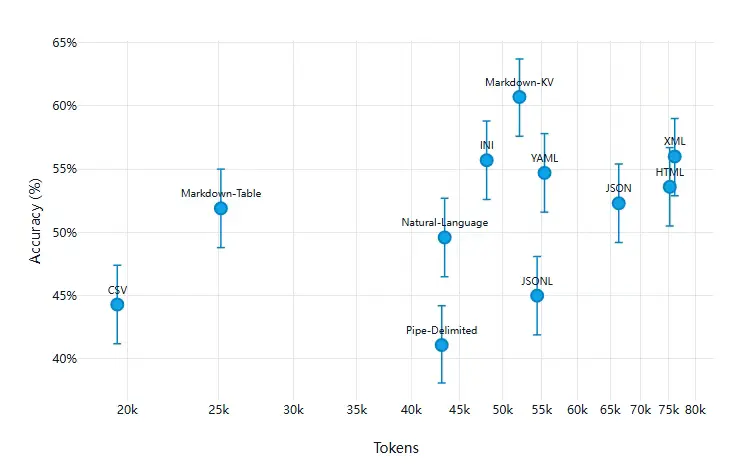
如圖所示,總體趨勢是 token 使用得越多,準確率越高,但並非線性相關。 有些格式表現超常(如 Markdown-KV),而另一些格式則在兩個維度上都表現低效(如 Pipe-Delimited)。
05 所評估的數據格式
1)JSON
2)CSV
3)XML
4)YAML
5)HTML
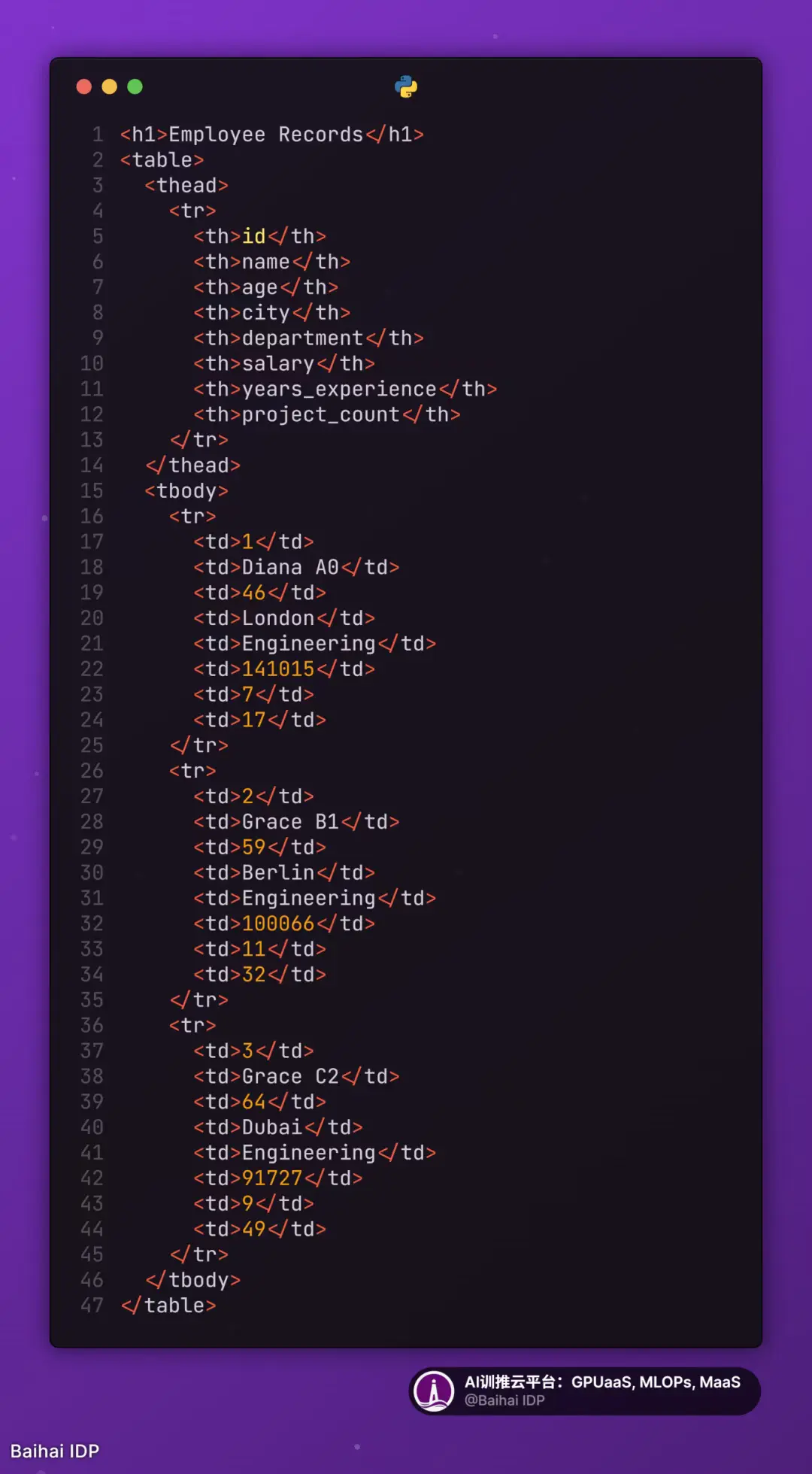
6)Markdown Table
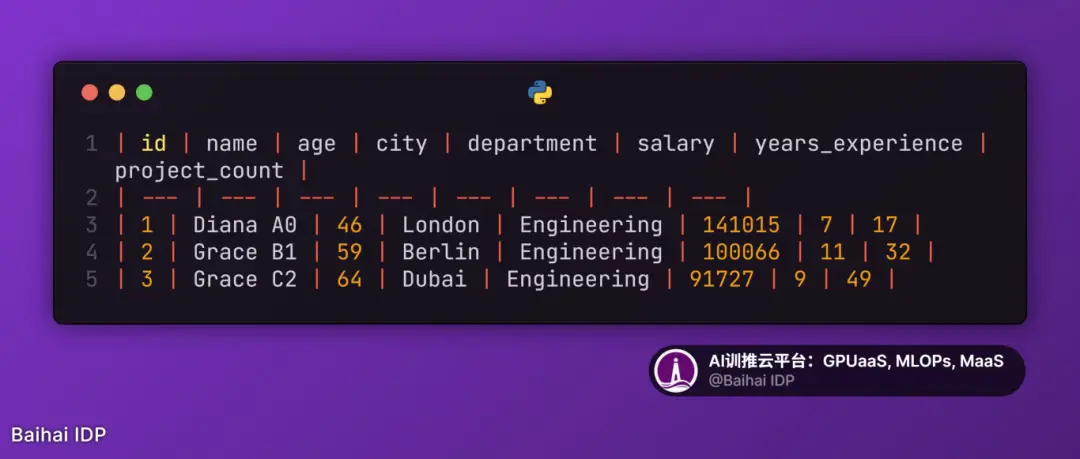
7)Markdown KV
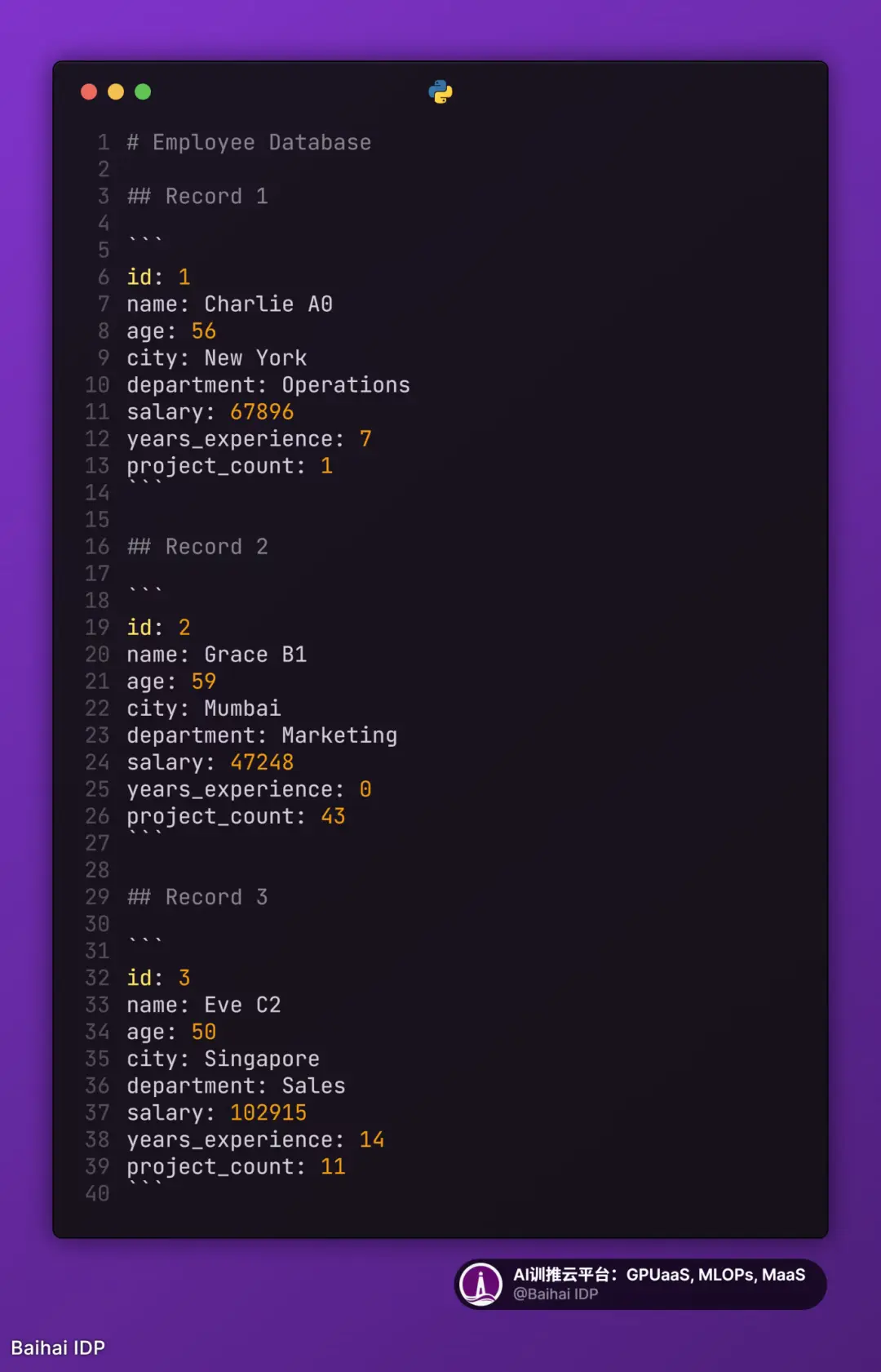
8)INI
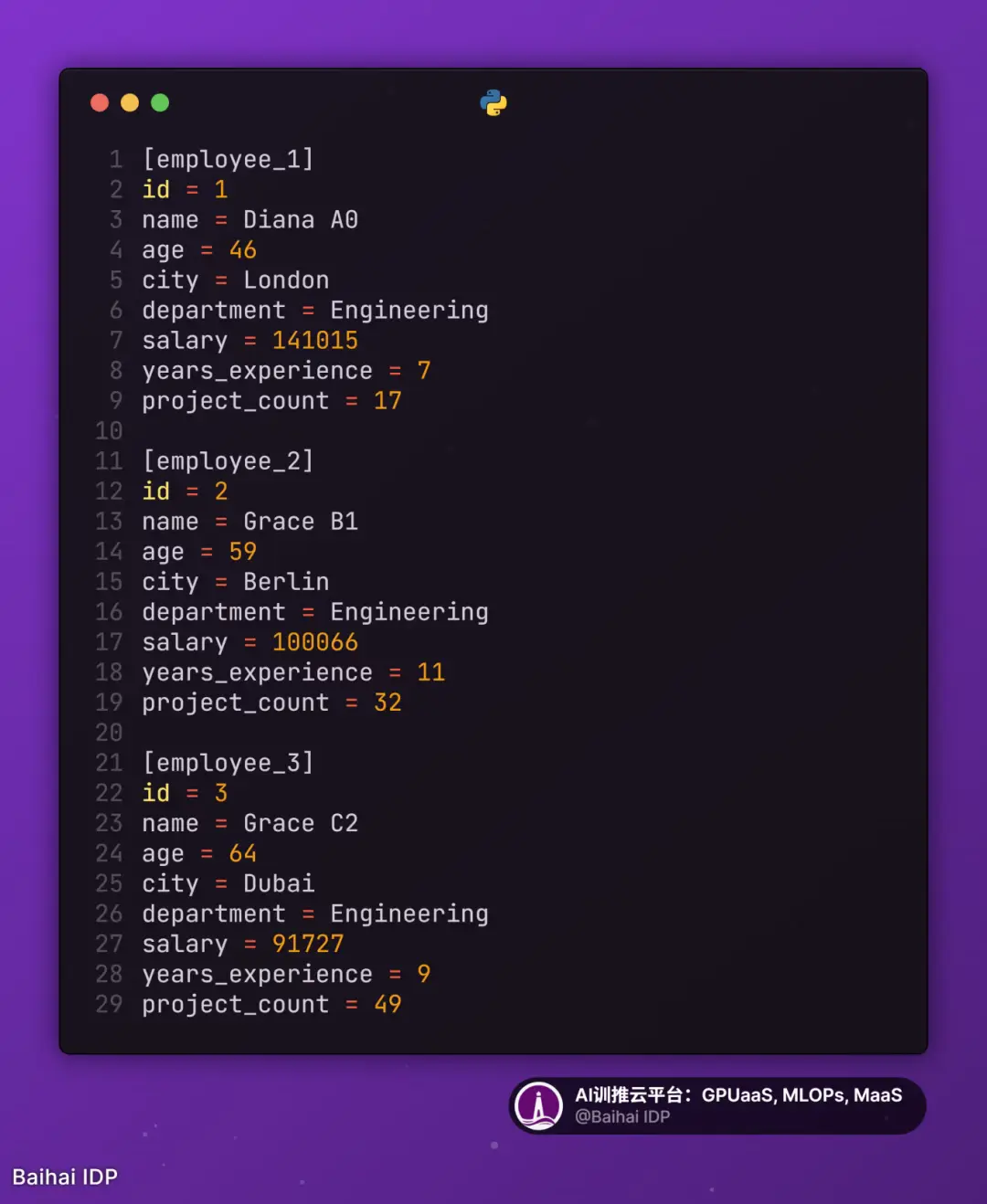
9)Pipe-Delimited

10)JSONL

11)Natural Language
06 實用建議
根據我們的實驗結果:
- 如果你大量使用表格數據,請考慮測試將數據轉換為其他格式是否能提升準確率。
- 在準確率比較重要的場景下,Markdown-KV 可作為首選格式。
- 若需平衡可讀性與成本,Markdown 的表格格式值得考慮。
- 慎將 CSV 或 JSONL 作為默認格式 ------ 這些常見格式可能會影響系統的準確性。
07 該實驗的侷限性與後續研究方向
- 模型與模型提供商: 我們僅測試了 OpenAI 的 GPT-4.1 nano。其他模型(尤其是來自其他提供商的模型)可能在不同數據格式下表現更佳(例如該模型訓練時使用最多的格式)。
- 數據內容: 我們僅測試了一種數據模式。使用其他數據模式時,結果可能不同。
- 數據結構: 我們僅測試了簡單的表格數據。若測試嵌套數據(如 JSON 配置文件)或包含合併單元格的表格,結果可能更有趣。
- 表格尺寸與表頭重複: 為測試模型性能極限,我們使用了相對較大的數據表,且未重複表頭。我們預計,更小的表格以及重複表頭行會帶來更高的準確率,尤其對於 CSV、HTML 和 Markdown table 等依賴表頭行的格式。
- 問題類型: 我們的每個測試問題都對應於檢索某條記錄中某個字段的值。測試其他類型的問題也將很有意義。
END
本期互動內容 🍻
❓你最常使用哪種表格格式?看到 Markdown-KV 格式準確率領先 16% 的結果後,會考慮改變現有實踐嗎?為什麼?
原文鏈接:
https://www.improvingagents.com/blog/best-input-data-format-for-llms
