本文由騰訊技術團隊顏勇分享,原題“騰訊新聞PUSH架構升級之路”,有修訂和重新排版。
1、引言
68 萬行代碼精簡到8.6 萬;Golang 重寫大部分 C++模塊;解決過度微服務化問題…… 這是新聞 PUSH 架構團隊取得的技術收益。
PUSH 是騰訊新聞精品資訊的重要分發途徑,也是新聞 App 重要的促活手段。作為 PUSH 架構團隊,我們一方面在積極支持好新聞護盤,同時也在對 PUSH 架構進行不斷的升級與進化,以持續提升 PUSH 系統的穩定性與質量、研發效率,同時持續減少運營成本。
本文主要分享的是騰訊技術團隊近年來對騰訊新聞消息推送PUSH系統做的架構優化和技術實踐。

2、Push平台介紹
2.1 概述
PUSH 是騰訊新聞內容重要的分發渠道,新聞 PUSH 平台承擔着將新聞資訊觸達到新聞用户、滿足用户及時獲取精品資訊的需求。
總體上,新聞 PUSH 鏈路分為下面兩部分。
2.2 PUSH觸發
按觸發方式的不同,新聞 PUSH 分為三類:
- 1)人工 PUSH:運營在 push cms 系統指定要發送的文章、要觸達的人羣包,人工觸發push發送;這類 PUSH 目前主要用於推送熱點事件/熱點資訊等;
- 2)自動化 PUSH:週期性地給用户計算他可能感興趣的內容,這類推送由後台自動觸發;
- 3)功能性 PUSH:由業務系統觸發,主要是為了實現一些業務功能通知,比如評論通知、關注通知等。
2.3 PUSH下發
對於所有 PUSH 觸發 的PUSH 進行調度(包括避讓、打散和頻控等)和觸達(通過自有通道或廠商通道推送給用户)。
新聞業務對新聞 PUSH 平台最重要的要求是:
1)要保證精品諮訊觸達的及時性:
新聞 PUSH 最重要的是要體現“新”,因為騰訊新聞用户有及時獲取熱點/突發資訊的訴求,用户經常有這樣的體感,有熱點突發事件時,所有 App 都會嘗試第一時間向用户發起推送,用户大概率會點擊收到的第一個推送。在瞭解了相關熱點事件後,對於後續其它 App 的推送,對用户而言就沒信息量了,大概率會被忽略,甚至可能會被用户視為一種打擾,影響用户體驗。從我們實驗數據來看,當P USH 下發延遲降低 50%,PUSH 點擊量會提升 10%。
所以新聞 PUSH 一直以來的目標是:熱點資訊需要第一時間觸達給用户,要做到“全網首推”。
2)要保證推送的用户體驗和較好的拉起效率:
PUSH 是新聞重要的促活手段,需要有較好的促活效率,這要求保證用户較好的推送體驗,因為用户如果感覺推送體驗不好,用腳投票,把 App 的 PUSH 系統開關給關了,這對 PUSH 而言就基本上就永遠喪失了給這個用户推送的機會了。這就要求要儘量保證在合適的時間點給推送用户感興趣的內容,推送要有合理的頻次,相鄰 PUSH 之間要有合理的時間間隔,推送內容要做合適的打散。
其實這兩個要求其實在一定層面上是有衝突的:
- a.如果要保證推送的及時性,就要求儘量減少計算,拿到消息消息後無腦推到消息通道,這個肯定最快;
- b.如果要保證良好的推送用户體驗,就需要做很多的判斷、考量和計算,這些考慮越多就需要做更多的計算和 io 操作,會影響推送的及時性;最近幾年,業務成本的考慮也是 PUSH 關注的重點,需要削減使用的機器和資源,就要求用更少的機器如何發得更快更好。
總結而言,之前新聞 PUSH 業務的突出問題主要有兩個方面,請繼續往下閲讀。
3、Push平台問題1:推送速度慢
我們團隊從 2022 年年中開始接手新聞 PUSH 平台。交接工作剛啓動,就遇到了一次 S 級熱點事件——一個國際級突發新聞。那天晚上,全網用户都在密切關注它的最新進展。
這個事件有兩個特點:熱度極高、且並非完全突發——早在一個月前就已經有明確預告,因此運營部門提前佈置了應急預案。我們剛接手系統時,對整個下發鏈路還不夠熟悉,只能憑直覺擴容機器,希望能抗住峯值。結果現實很快給了我們一記當頭棒喝。
當晚,很多內部同事都裝着多個新聞 App,一眼能看到誰家的推送更快。那晚我們的延遲問題非常明顯,甚至有用户在熱點過去一個多小時後才收到通知。事後有專門的評測團隊做了分析,指出“PUSH 下發耗時過長,高活用户 P90 均值達 20 分鐘”,報告還發到了高層羣裏——對我們來説,那無疑是一次刻骨銘心的教訓。
4、Push平台問題2:開發效率和問題排查效率低
之前 PUSH 鏈路特別長,新聞 PUSH 內部有 30+ 個模塊,同時還依賴其它兩個跨業務團隊。經常一個需求開發要改多個模塊,要團隊幾個人一起開發,約定交互協議,開發後再聯調測試,在多個模塊起聯合實驗;然後還得給中台提需求,然後匹配中台的排期後,才能完成需求上線;這一系列操作就拉長了 push 需求的leadtime。
線上有 case 時,問題排查也需要串聯多個模塊,關聯多個模塊數據,甚至需要跨部門拉上其它這邊來一起來排查,排查效率非常低。push case 非常多,比如用户為什麼收到了/沒收到某條 push 之類的典型 case,之前需要關聯鏈路20來個模塊的日誌,還要聯合中台一起排查,每次 case 排查時間都在天級;之前在case 排查上,每天都耗費我們大量的人力。
既要持續提升 PUSH 觸達的及時性、又要持續提升推送的用户體驗和拉活效率,還要持續降低運營成本,客觀而言,在技術上是一個較大的挑戰。本文主要詳述,我們如何通過技術架構升級來支撐這個既要&又要&還要的目標。
5、老Push架構的問題梳理
5.1 模塊鏈路過長,內耗過多
一條快速PUSH,從推送內容過審後,到最終發出去,最長要經過18個模塊,另外還需要經過中台多個模塊。一條待推送的數據最多要經歷 17 次內部 rpc 轉發,多個模塊之間騰挪流轉,各種網絡 rpc,各種內耗,肯定發得慢。
一個最典型的例子:原架構有個模塊叫scheduler,它主要負責決定一個push該不該發,直觀上感覺它裏面應該囊括了各種過濾策略,但是原架構做成了多個微服務。scheduler 模塊裏本身有一些過濾邏輯,另外有一個叫做 filter 的模塊,專門負責品牌、開關等硬規則過濾;另外有一個叫做 policy 的模塊,專門負責配額等軟規則過濾;所有過濾規則都通過後,進入一個叫做 channer 模塊,就決定下這次推送走哪個通道;然後又走到一個叫 worker 的模塊裏,而它只做對接下游中台的協議適配。
總體上看,原鏈路就是過度微服務化了:
- 1)模塊多會導致數據流轉的低效,模塊間網絡 rpc 會浪費處理耗時;
- 2)其次會影響迭代效率,模塊數不是越多越好,因為經常一個需求需要改多個模塊,做多次上線;
- 3)同時模塊過多也對聯調&測試效率,影響線上 case 排查效率。
這就違反了“模塊內高內聚,模塊間低耦合”的架構設計原則,進而會影響業務迭代效率。
5.2 依賴服務有瓶頸
上文提到的 S 級熱點事件時,我們將下發服務機器擴了一倍,但是下發速度並沒有提升,説明瓶頸不在下發服務本身下,而是在依賴服務上;通過鏈路debug,我們定位到了鏈路瓶頸:號碼包拉取。
在發送人工 push,運營會指定受眾人羣包(幾百萬到幾億不等),這時候需要分頁拉取該號碼包數據進行處理。
之前老架構使用了底層平台的人羣包服務,新聞所有 push 人羣包都上傳到了該人羣包服務,當發送指定人羣包,需要請求平台側接口分頁拉取人羣包數據,當時因為平台側人羣包功能實現比較複雜,能支持一些比較高級的能力,因此這個分頁接口耗時比較長。但其實我們只用到了最簡單的數據分頁的功能,完全可以採用更簡單的實現方案,以減少接口耗時。
5.3 鏈路穩定性不好
5.3.1)容錯能力差:
之前鏈路基本無容錯能力,發生了過一次因上游未按約定協議跟我們請求交互,導致我們服務掛了半天,是一次典型的 P0 級事故。
5.3.2)缺少節點自動故障轉移:
scheduler 負責 push 調度,原架構為了提升處理效率,scheduler 裏做了本地緩存;為了避免緩存失效,起了一個服務 dispatch 消費觸發側生產的待推送的消息,然後按照用户設備號一致性哈希來 sharding,通過 rpc 請求對應的 scheduler,scheduler接受到請求後,塞入到它本地的內存隊列裏,如果隊列滿了就直接丟棄。
它原來存在有這些問題:dispatch無腦往下游轉發,sharding規則非常僵硬,一個用户的push一定要打到某個節點,未做故障轉移;當某節點異常滿載時,dispatch還是會往這個節點打,導致丟消息或者是 push發送得慢。而且當節點滿載時,有限的cpu還需要耗費在rpc解包、無法插入內存隊列而丟棄之類的無用消耗上。
5.4 鏈路處理無優先級區分
運營人工發的 PUSH 和自動化 PUSH 都使用同一個下發鏈路,熱點突發事件資訊多由運營人工發送,而自動化 PUSH 多發一些用户可能感興趣的內容,其實它對於推送速度並沒那麼敏感;當有人工推送的熱點突發內容時,自動化 PUSH 會和它一起爭搶有限的鏈路資源。
另外,在鏈路總吞吐量一定的情況下,其實處理順序可以調整,讓鏈路資源有限保證人工推送的熱點突發內容的發送;
5.5 技術棧不統一
之前 push 下發鏈路有 C++/Go 兩種技術棧,技術棧不統一不利於代碼複用,影響需求迭代效率。push下發鏈路本質上是一個高 io 型的流程,其實可以完全可以統一到 Golang 技術棧。
5.6 鏈路測試效率低
push 鏈路業務邏輯比較多,在日常密集業務需求迭代中,新功能我們可以在線上通過構造對應的功能 case 來進行冒煙測試,但是比較難評估是否影響了線上已有的業務邏輯。
之前缺乏有效的迴歸測試手段,由於擔心影響線上業務指標,為了驗證是否影響線上已有業務邏輯,我們大的修改都會開比較長的小流量實驗驗證,比如我們在做調度架構升級時,開了一個近兩個月的小流量實驗,測試效率比較低也會導致需求迭代效率比較低。
6、新Push架構優化1:消息通道自建
之前新聞 PUSH 依賴於平台側的消息通道,業務側主要負責 PUSH 調度,即業務側決定觸發和過濾,平台側負責 PUSH 觸達給用户終端。
由於 PUSH 是新聞增長護盤的重點方向,有較頻繁的業務迭代,對底層消息通道我們有較多的業務需求,在業務迭代過程中我們發現平台側需求 leadtime 比較長,無法滿足業務側迭代效率的要求;在經平台側這邊商量且同意後,我們完成新聞push消息通道的自研,直接對接廠商推送並搭建了長鏈接通道,實現了 push 全鏈路在業務側的全閉環。
我們在自建 push 消息通道時,對原來的架構做了重寫:
1)精簡鏈路,模塊整合,減少系統複雜度:去掉我們不關心的無用功能,將原鏈路15個模塊,代碼 68 萬行整合為了6個模塊,代碼共8.6萬行;通過代碼精簡能減少系統複雜度,有助於提升業務迭代效率;同時能避免模塊之間的rpc通信開銷,提升鏈路處理效率。
2)客户端/服務端交互接口整合,提升數據通信成功率:以前 PUSH 註冊依賴於註冊&綁定&上報三個接口請求,任何一次請求出錯,push 註冊就會失敗;我們在新流程裏將註冊&綁定&上報需要的所有數據,都一起傳給新接口,由服務端在一個接口裏實現註冊、綁定和上報;將註冊成功率從90%提升到了99.9%。
3)與新聞技術技術架構保持統一:將原架構發現/rpc技術棧的基礎組件升級為騰訊新聞自用的基礎組件,儘量使用我們熟練使用的技術棧,以提升業務開發&運維效率。
4)優化了原來鏈路一些不合理的地方:對原來鏈路的限流機制、通道選擇策略做了優化,增加了必要的功能,比如小流量實驗環境的支持。
7、新Push架構優化2:統一技術棧
之前 push 鏈路有 C++/Golang 兩種技術棧,除了 push 推薦服務外, 其它 C++鏈路模塊全部使用 Golang 模塊進行了重寫,以提升業務迭代效率和鏈路穩定性。
8、新Push架構優化3:鏈路整合升級,提升效率
一個架構如果如果過度微服務化了,會帶來各種問題:
- 1)模塊間耦合嚴重,影響研發效率:本來是一個模塊應該完成的工作,硬拆成了2個模塊,有改動需要都需要改兩個模塊,需要模塊間聯調測試,影響需求迭代效率。
- 2)架構效率低:拆成微服務後,函數本地調用變成了RPC網絡調用,需要增加大量的拆包、解包的操作,資源白白浪費在這些無用的內耗上了。
對於頻繁迭代的地方,單獨抽成單獨的微服務是有助於提升迭代效率的;但是我們review歷史push需求,都比較分散,沒有集中到一個特定的地方,我們按照“一個需求儘量只用改一個模塊”的原則,對原來的push鏈路的所有模塊進行了整合升級。
具體的升級內容是:
- a. 觸發側合併為了1個模塊:將原來觸發側的5個模塊合併為1個模塊;
- b. 調度側合併為了1個模塊:將原來調度側的5個模塊合併為了1個模塊;
- c. 將消息通道側模塊做了整合:如上所述,我們將push消息通道原來15個模塊合併為了5個。
經過鏈路整合後:以前一個 PUSH 消息最多要經過 18 個模塊,17次內部鏈路rpc轉發;升級後,只用經過 3 個模塊,只用經過 2 次 rpc 轉發;這樣就顯著提升了鏈路效率;而且模塊減少後,業務需要迭代無需開發多個模塊,避免模塊之間聯調和測試,提升了業務迭代效率;同時,線上 case 排查時,無需做多模塊的日誌 join,提升了 case 排查效率。
9、新Push架構優化4:自建號碼包服務,提升號碼包獲取速度
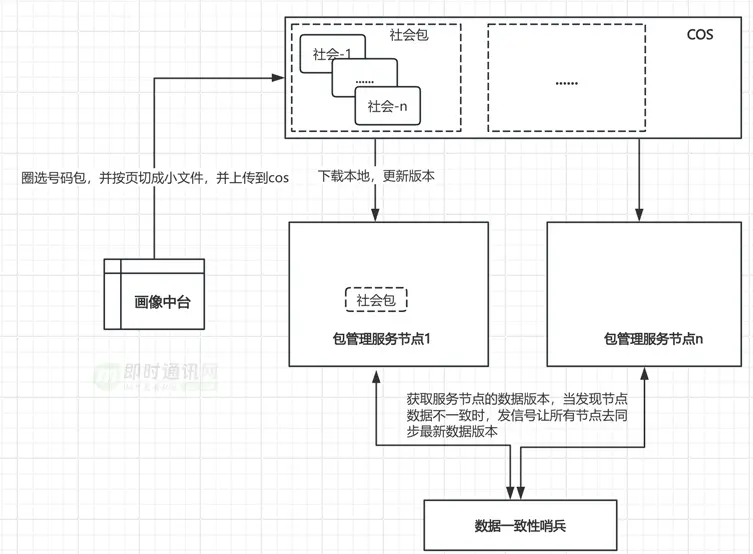
如上文所述:之前號碼包的拉取慢是系統的主要瓶頸所在,而在我們這個場景比較簡單,因此我們考慮自建號碼包服務,針對於我們自己的需求來定製開發,以提升服務性能。我們的需求只有一個,就是對離線包進行分頁,並提供服務接口返回指定頁的數據。
1)畫像中台圈選興趣包,並按頁切成若干個小文件,每個興趣包一個文件夾,並上傳到cos,興趣包裏帶着數據版本號;
2)構建包管理服務,提供獲取指定興趣包指定頁數據的能力;包管理服務定期從cos上check是否有更新的數據(比較本地數據版本和cos最新的數據版本),如果有,則拉取最新的數據更新本地數據;當接收到拉取指定包指定頁數據的請求後,則定位到對應文件夾讀取對應頁文件數據並返回;
3)集羣有個數據一致性哨兵,定期檢查集羣節點的數據版本,當發現集羣數據版本不一致時,給集羣所有節點發信號,強制讓每個節點同步cos上的最新數據,讓集羣所有節點數據跟最新數據保持一致。
10、新Push架構優化5:在線過濾改成離線預處理,避免在線處理耗時
運營在發PUSH時會選擇受眾人羣包,同時會指定系統、品牌等篩選項,之前的處理流程是先把人羣包一股腦發到鏈路裏,然後在下發鏈路里根據用户畫像數據,對數據進行實時過濾。在線過濾增加了鏈路下發的耗時。
其實系統&品牌過濾完全可以前置到離線側,我們將號碼包按品牌和系統維度進行了拆分,比如“社會”包按 android/ios、huawei/oppo/vivo/honor/xiaomi,拆成了13個包,當運營選擇指定的篩選項時,直接拉取對應的號碼包,這樣就避免了在線過濾的耗時,減少了下發的延時。
11、新Push架構優化6:將單IO操作自動聚合成批量操作
push下發鏈路有大量io操作,比如獲取用户維度的多路數據(比如用户系統、品牌、下發&曝光&點擊歷史等),獲取文章維度的多路數據(文章正排數據等)。鏈路其實主要耗時還是在io部分,如果能提升io吞吐量,就能提升PUSH鏈路的吞吐量,減少下發延時;io操作批處理肯定能提升吞吐量。
但是在具體業務流程中,不同push類型、不用品牌用户,處理邏輯會有不同,因為每個push的處理流程可能都不一樣,無法直接批處理。所以之前調度主鏈路流程是從隊列裏按單個消費進行處理的。
為了提升鏈路吞吐量,我們對每一類io操作做了一個類,對外暴露一個單個io請求接口,外部調用該接口後,將請求壓入一個異步隊列,同時開始等待結果的返回;這樣該類io請求都會在該異步隊列裏進行了匯聚。
下層會開若干個處理協程,批量從異步隊列消費出若干請求任務,拼成批量的io請求,然後拿到批量io結果,按序向上層返回io結果;
這樣對上層而言,看到的還是單個的同步io接口,上層業務邏輯開發流程無需做改造,底層其實已經自動做了io的批量聚合,顯著提升了鏈路吞吐量。
12、新Push架構優化7:優先推送熱點突發內容,優先保證高價值用户及時性體驗
在鏈路吞吐量一定的情況下,一個推送任務小到幾百萬,大到一兩億的發送量,都需要處理時間。這時候先處理比後處理的時延要少。
其實可以考慮對鏈路發送進行調度:
- 1)鏈路優先保障熱點突發PUSH的發送,我們建立了任務優先級隊列,當有熱點突發PUSH在發送時,其它PUSH延遲發送;
- 2)同一個PUSH任務,對用户推送順序也做了排序:活躍度高、歷史push點擊率高、預估商業化價值高、對push時延敏感的用户優先發送。
通過優先級調度,最大程度保障了熱點突發內容和高價值用户的推送及時性的體感。
13、新Push架構優化8:增加自動故障恢復能力
為了提升鏈路吞吐量,調度節點進程通過 LRU cache 緩存了大量數據,所以在推送消息處理的 sharding 方式上採用了按設備號一致性哈希。
很多時候某個節點異常時,會出現慢而不死的情況:處理能力陡降,但是節點存活正常。北極星未能把它摘掉,相當一部分設備會打到該節點,即使該節點已經滿載了,之前架構為了避免緩存失效而導致處理耗時增加,還是會一致性哈希將流量打往該節點,導致這部分用户處理耗時異常增加,甚至發送失敗。
新架構對於推送任務sharding做了優化:在一致性哈希的基礎上,每個節點計算出4個固定的backup;當某節點的失敗率或處理耗時超過一定閾值時,將該節點的流量均勻低分給他的backup。通過這種方式就支持單節點異常時的自動故障恢復。
14、新Push架構優化9:構建push鏈路自動化測試能力
構建了接口自動化迴歸測試流程:
- 1)case覆蓋push鏈路的核心邏輯;
- 2)合併master時自動觸發迴歸測試流程的執行。
構建了自動化diff測試流程:
diff流程大體思路都類似,通過錄制線上流量的真實請求和返回結果,在測試環境進行回放,觀察同一請求下,返回結果是否會有差別;如果無差別,説明測試環境跟線上一樣,上線不會引起線上數據異常;如果有差別,就需要分析這些差別是否是符合預期的。
diff測試基本能迴歸到線上所有業務邏輯分支,能彌補迴歸測試覆蓋度有限的問題。
主要挑戰:
push依賴的數據變化比較快,導致在同一時間,同一請求的返回結果會不同;比如push為了避免重複下發同一篇文章,會依賴於下發歷史數據,線上錄製了剛下發的某篇文章,在測試環境去回放肯定就不能下發了,因為線上剛把這篇文章寫入到下發歷史裏,導致回放請求時返回結果是不能下發了,這樣自然就產生了diff。
解決方案:
在流量錄製時,除了錄製請求之外,同時錄製各個依賴數據,在回放時,依賴數據以依賴數據為準,通過這種方案就避免了依賴數據易變而引入diff的問題。
15、架構升級後的系統表現
1)push運營成本顯著降低:通過持續的 push 架構優化,新聞 push 總運營成本下降70%;
2)PUSH鏈路性能(吞吐量)顯著提升:通過持續的 push 架構優化,顯著提升了 push 鏈路的性能,push推送量(出口)峯值吞吐量提升了3.5倍;
3)熱點突發(全國/快速)PUSH全鏈路耗時下降明顯:
- a. 熱點突發(全國/快速)PUSH內部鏈路耗時P90下降了90%;
- b. 內部鏈路耗時指的是從push審核通過到推送給廠商的時間,即我們內部鏈路總的耗時時長;
- c. 熱點突發(全國/快速)PUSH全鏈路耗時(包括內部鏈路耗時和廠商鏈路耗時)下降了90%
- d. 全鏈路耗時指的是從push審核通過到用户收到PUSH時間,即包括內部鏈路和廠商鏈路總的耗時時長.
我們完成一些架構升級後,還是評測團隊對了評測,騰訊新聞的PUSH已經領先於競品1~4分鐘了。
4)提升了PUSH點擊效果:
push推送速度提升後,push點擊數據也能看到明顯受益,熱點突發PUSH點擊pv提升了10%,push大盤點擊UV也能看到顯著的正向收益;
線上收不到PUSH的用户客訴也減少到25年H1 0 例,提升了用户產品體驗。
5)穩定性良好:push鏈路主要重構完成後,PUSH鏈路穩定性&質量明顯提升,2025.02以後 0 故障。
16、參考資料
[1] 極光推送系統大規模高併發架構的技術實踐分享
[2] 魅族2500萬長連接的實時消息推送架構的技術實踐分享
[3] 專訪魅族架構師:海量長連接的實時消息推送系統的心得體會
[4] 一個基於長連接的安全可擴展的訂閲/推送服務實現思路
[5] 實踐分享:如何構建一套高可用的移動端消息推送系統?
[6] Go語言構建千萬級在線的高併發消息推送系統實踐(來自360公司)
[7] 騰訊信鴿技術分享:百億級實時消息推送的實戰經驗
[8] 百萬在線的美拍直播彈幕系統的實時推送技術實踐之路
[9] 京東京麥商家開放平台的消息推送架構演進之路
[10] 技術乾貨:從零開始,教你設計一個百萬級的消息推送系統
[11] 長連接網關技術專題(四):愛奇藝WebSocket實時推送網關技術實踐
[12] 喜馬拉雅億級用户量的離線消息推送系統架構設計實踐》
[13] 直播系統聊天技術(四):百度直播的海量用户實時消息系統架構演進實踐
[14] 消息推送技術乾貨:美團實時消息推送服務的技術演進之路
[15] 揭秘vivo百億級廠商消息推送平台的高可用技術實踐
[16] 得物從零構建億級消息推送系統的送達穩定性監控體系技術實踐
[17] B站千萬級長連接實時消息系統的架構設計與實踐
[18] 轉轉千萬級用户量消息推送系統的架構演進之路
[19] 企業級實時消息推送系統的架構設計,一文即懂!
即時通訊技術學習:
- 移動端IM開發入門文章:《新手入門一篇就夠:從零開發移動端IM》
- 開源IM框架源碼:https://github.com/JackJiang2011/MobileIMSDK(備用地址點此)
(本文已同步發佈於:http://www.52im.net/thread-4883-1-1.html)
