近日,生數科技與清華大學 TSAIL 實驗室聯合發佈並開源視頻生成加速框架:TurboDiffusion。
開源地址:https://github.com/thu-ml/TurboDiffusion
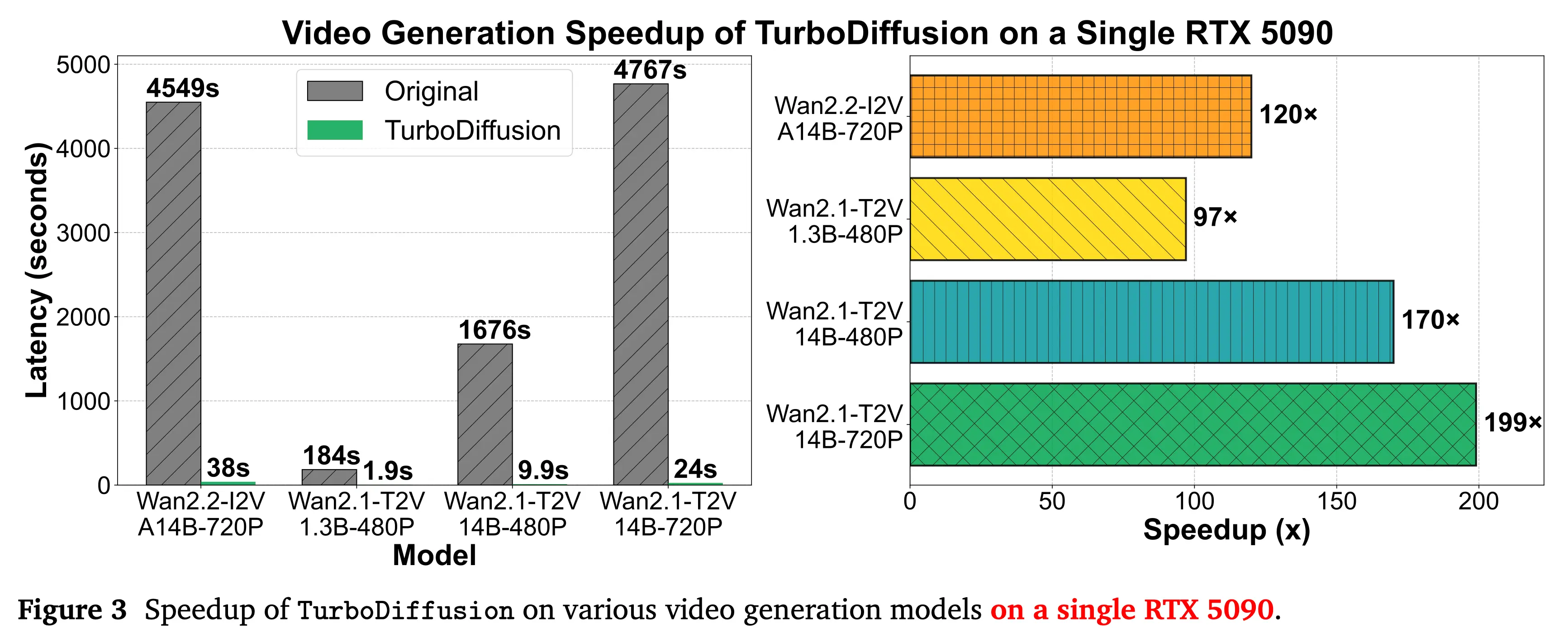
據介紹,在幾乎不影響生成質量的前提下,該框架可實現最高達200倍的視頻生成推理加速。TurboDiffusion的核心技術優勢精準擊中了視頻生成領域的一個關鍵轉折點。此前,視頻擴散模型雖然具備強大的創造能力,但始終受限於計算複雜度高、效率受限的狀態。

不同於單點優化方案,TurboDiffusion 通過多項關鍵技術的協同配合,從模型計算方式、注意力機制以及推理流程等多個層面,對視頻生成進行整體提速。
TurboDiffusion 並非單一優化,而是通過多項前沿加速技術的系統化組合:
-
低比特注意力加速 採用 SageAttention 將注意力的計算執行在低比特的 Tensor Core 上,以無損且數倍地加速注意力計算。
-
稀疏-線性注意力加速 採用可訓練的稀疏注意力 Sparse-Linear Attention (SLA) 進行注意力的稀疏加速,最高可在 SageAttention 的基礎上進一步實現 17-20 倍的注意力稀疏加速。
-
採樣步數蒸餾加速 通過目前最先進的蒸餾方法 rCM,讓模型僅用 3-4 步即可完成高質量的視頻生成。
-
線性層加速 將模型的線性層中的參數以及激活都進行8 比特的128x128的塊粒度量化,即通過 W8A8 不僅加速模型的線性層計算,也大幅減少了模型的顯存佔用。
TurboDiffusion的發佈,在保持高質量輸出的前提下大幅壓縮生成速度,首次讓高質量視頻生成逼近實時交互的可行區間,被視為視頻大模型發展的 “DeepSeek Moment”,推動行業從“技術探索期”加速邁向“規模化與商業化落地階段”,也標誌着 AI 視頻創作正式邁入“實時生成”時代。
參考鏈接:
TurboDiffusion:https://github.com/thu-ml/TurboDiffusion
SageAttention:https://github.com/thu-ml/SageAttention
Sparse-Linear Attention:https://github.com/thu-ml/
SLArCM:https://github.com/NVlabs/rcm
