1. 簡介
本文將構建一個由 Fauna 和 Spring 驅動的物聯網應用程序。
注意: 本文使用了 Fauna 查詢語言的舊版本。請參閲 Fauna 的文檔 以獲取查詢語言的最新版本。
2. 物聯網應用 – 邊緣計算與分佈式數據庫
物聯網應用與用户緊密協作。它們負責消費和處理大量實時數據,並實現低延遲。為了實現低延遲和最大性能,這些應用需要強大的邊緣計算服務器和分佈式數據庫。
此外,物聯網應用還處理非結構化數據,主要源於數據來源的多樣性。物聯網應用需要能夠高效處理這些非結構化數據的數據庫。
在本文中,我們將構建一個負責處理和存儲個人健康指標(如體温、心率、血氧飽和度等)的物聯網應用後端。該物聯網應用可以通過攝像頭、紅外掃描儀或智能手錶等可穿戴設備,消費健康指標。
3. 使用Fauna於物聯網應用
在上一節中,我們學習了典型物聯網應用的特性,並且也理解了人們對用於物聯網空間的數據庫所期望的功能。
Fauna,由於其以下特性,非常適合作為物聯網應用的數據庫:
分佈式: 當我們在Fauna中創建應用時,它會自動分佈到多個雲區域。這對於使用諸如Cloudflare Workers或Fastly Compute @ Edge等技術進行邊緣計算的應用具有巨大益處。對於我們的用例,該特性可以幫助我們以最低的延遲快速訪問、處理和存儲來自全球各地個人的健康指標。
文檔關係型: Fauna將JSON文檔的靈活性和熟悉性與傳統關係數據庫的關聯性和查詢能力相結合。這種能力有助於大規模處理非結構化物聯網數據。
無服務器: 通過Fauna,我們可以完全專注於構建我們的應用程序,而無需擔心與數據庫相關的管理和基礎設施開銷。
4. 應用程序的高級請求流程
在總體上,我們的應用程序的請求流程如下所示:
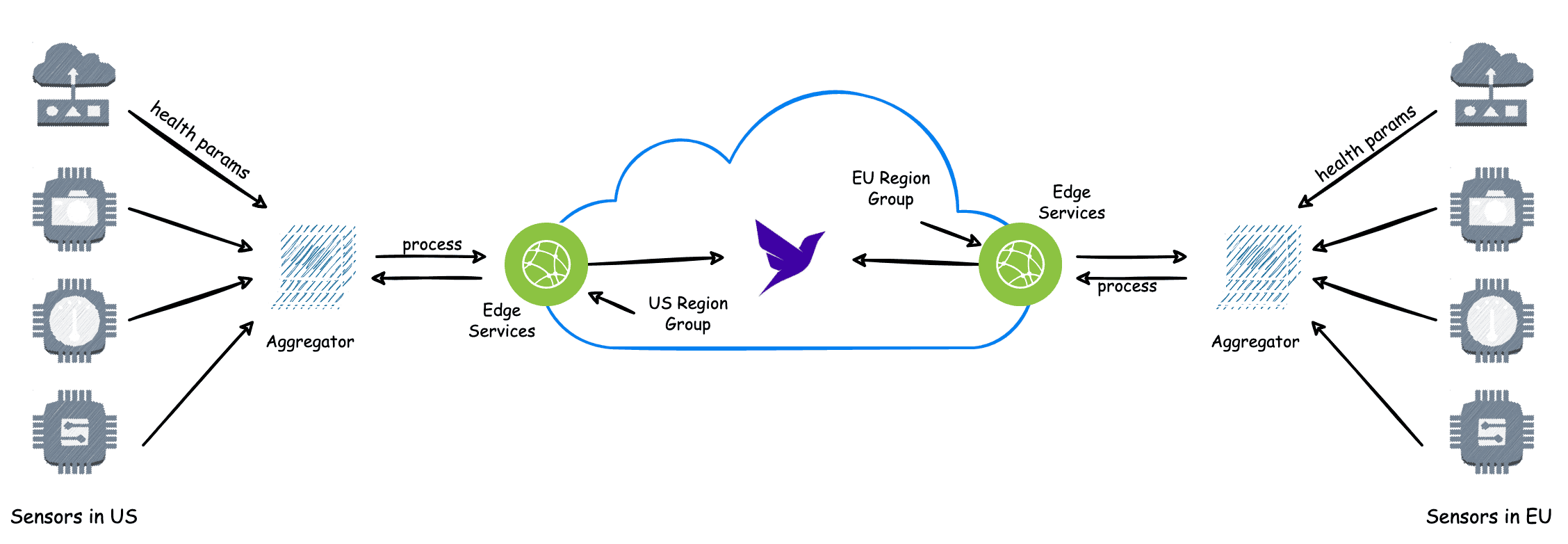
聚合器是一個簡單的應用程序,它從各種傳感器聚合接收到的數據。 在本文中,我們將不關注如何構建聚合器,但可以通過在雲端部署一個簡單的 Lambda 函數來解決它的目的。
接下來,我們將使用 Spring Boot 構建邊緣服務,並使用不同的區域組設置 Fauna 數據庫,以處理來自不同區域的請求。
5. 使用 Spring Boot 創建 Edge 服務
讓我們使用 Spring Boot 創建 Edge 服務,該服務將從健康傳感器中消費數據並將其推送到適當的 Fauna 區域。
在我們的 Fauna 教程中,包括《FaunaDB 入門與 Spring》和《使用 Fauna 和 Spring 構建您的第一個 Web 代理客户》,我們探討了如何創建與 Fauna 互動的 Spring Boot 應用程序。 歡迎查閲這些文章以獲取更多詳細信息。
5.1. 領域
首先,讓我們瞭解我們的邊緣服務所涉及的領域。
正如之前提到的,我們的邊緣服務將消費和處理健康指標,我們創建一個包含個人基本健康指標的記錄:
public record HealthData(
String userId,
float temperature,
float pulseRate,
int bpSystolic,
int bpDiastolic,
double latitude,
double longitude,
ZonedDateTime timestamp) {
}5.2. 健康服務
外部健康服務將負責處理健康數據,從請求中識別區域,並將其路由到適當的Fauna區域:
public interface HealthService {
void process(HealthData healthData);
}讓我們開始構建實現:
public class DefaultHealthService implements HealthService {
@Override
public void process(HealthData healthData) {
// ...
}
}接下來,我們添加識別請求區域的代碼,即請求發起地。
Java 中有幾個庫可以識別地理位置。但是,對於本文,我們將添加一個簡單的實現,為所有請求返回“US”區域。
讓我們添加接口:
public interface GeoLocationService {
String getRegion(double latitude, double longitude);
}以及返回“US”區域的所有請求的實現:
public class DefaultGeoLocationService implements GeoLocationService {
@Override
public String getRegion(double latitude, double longitude) {
return "US";
}
}接下來,讓我們在我們的 HealthService 中使用這個 GeoLocationService;讓我們注入它:
@Autowired
private GeoLocationService geoLocationService;並在 process 方法中使用它來提取區域:
public void process(HealthData healthData) {
String region = geoLocationService.getRegion(
healthData.latitude(),
healthData.longitude());
// ...
}確定區域後,必須查詢適當的Fauna區域組來存儲數據,但在此之前,我們先設置Fauna數據庫和區域組。完成之後我們將繼續進行集成。
6. 使用區域組與Fauna數據庫 – 設置
讓我們從在Fauna中創建新的數據庫開始。如果還沒有賬號,我們需要先創建一個。
6.1. 創建數據庫
登錄後,讓我們創建一個新的數據庫:
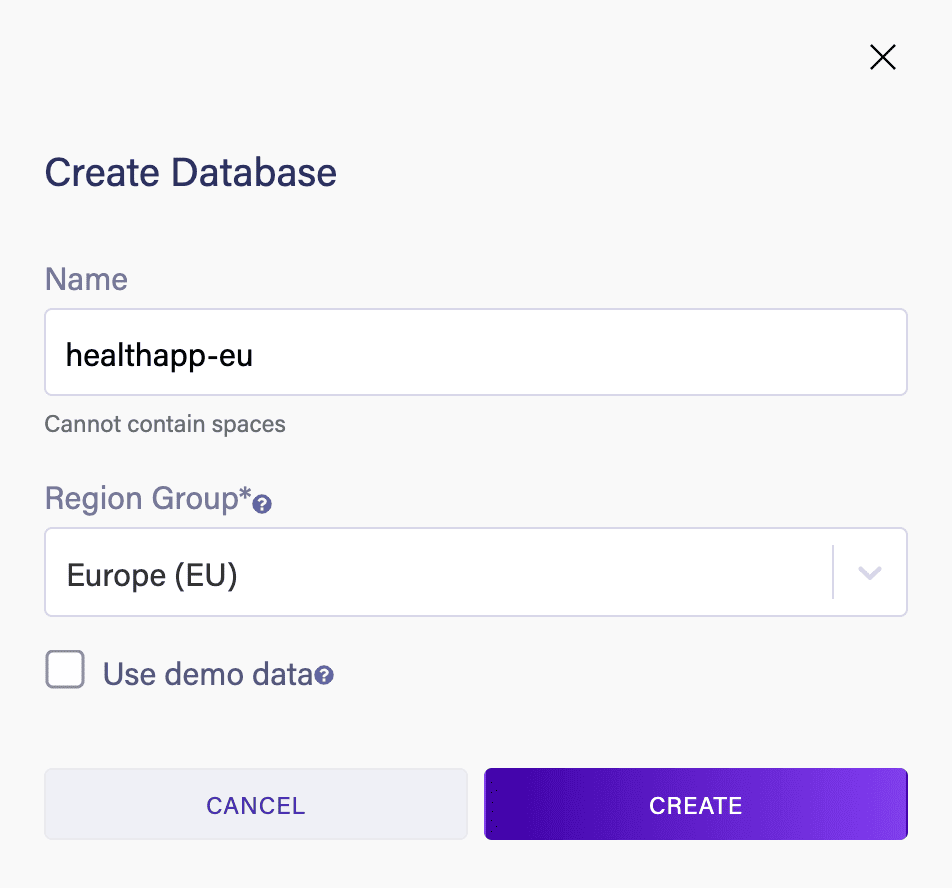
在這裏,我們將在 Europe (EU) 區域創建這個數據庫;讓我們在 US 區域創建相同的數據庫,以處理來自美國的需求:
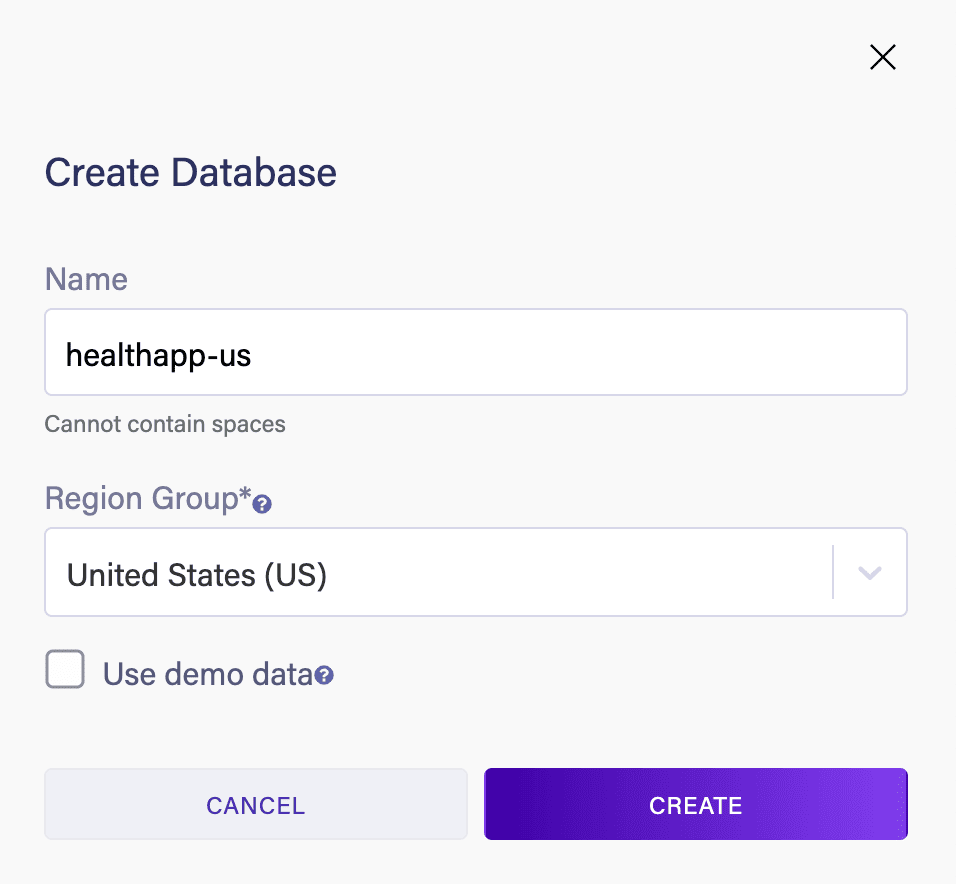
接下來,我們需要一個安全密鑰才能從外部訪問我們的數據庫,在本例中,是從我們創建的邊緣服務中訪問的。 我們將為兩個數據庫分別創建密鑰:
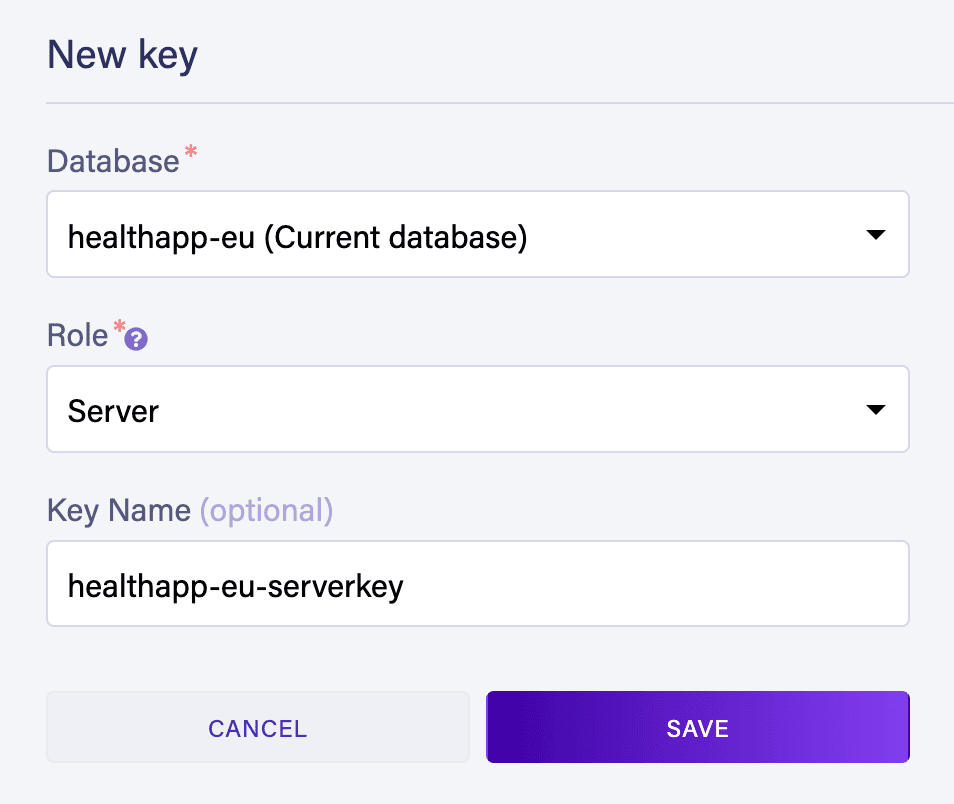
同樣,我們將為訪問 healthapp-us 數據庫創建密鑰。 有關在 Fauna 中創建數據庫和安全密鑰的詳細説明,請參閲我們的“FaunaDB 與 Spring 入門”文章。
密鑰創建完成後,我們將存儲區域特定的 Fauna 連接 URL 和安全密鑰,到我們 Spring Boot 服務的 application.properties 中:
fauna-connections.EU=https://db.eu.fauna.com/
fauna-secrets.EU=eu-secret
fauna-connections.US=https://db.us.fauna.com/
fauna-secrets.US=us-secret我們將在使用它們來配置 Fauna 客户端連接到 Fauna 數據庫時需要這些屬性。
6.2. 創建 HealthData 集合
接下來,讓我們在 Fauna 中創建 HealthData 集合,用於存儲個人的健康指標。
讓我們通過在數據庫儀表板的“集合”選項卡中導航並點擊“新建集合”按鈕來添加集合:
然後,讓我們在下一個屏幕上點擊“新建文檔”按鈕,在 JavaScript 控制枱中插入一個樣本文檔,並添加以下 JSON:
{
"userId": "baeldung-user",
"temperature": "37.2",
"pulseRate": "90",
"bpSystolic": "120",
"bpDiastolic": "80",
"latitude": "40.758896",
"longitude": "-73.985130",
"timestamp": Now()
}Now() 函數將插入當前時間戳到 timestamp 字段中。
當保存數據時,上述數據將被插入,並且可以在 healthdata 集合的 Collection 選項卡中查看所有插入的文檔:

現在我們已經擁有數據庫、密鑰和集合,接下來我們將集成我們的 Edge 服務與 Fauna 數據庫,並在它們上執行操作。
7. 將 Edge 服務與 Fauna 集成
為了將我們的 Spring Boot 應用程序與 Fauna 集成,我們需要將 Fauna 的 Java 驅動程序添加到我們的項目中。 讓我們添加依賴項:
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>我們始終可以找到 faunadb-java 的最新版本在此。
7.1. 創建針對特定區域的 Fauna 客户端
本驅動程序提供了一個 FaunaClient,我們可以通過指定連接端點和密鑰輕鬆配置它:
FaunaClient client = FaunaClient.builder()
.withEndpoint("connection-url")
.withSecret("secret")
.build();在我們的應用程序中,根據請求來自哪裏,我們需要連接到 Fauna 的歐盟和美國區域。我們可以通過分別預先配置針對這兩個區域的不同 FaunaClient 實例,或者在運行時動態配置客户端來解決這個問題。 讓我們採用第二種方法。
讓我們創建一個新的類,FaunaClients,該類接受一個區域並返回正確配置的 FaunaClient:
public class FaunaClients {
public FaunaClient getFaunaClient(String region) {
// ...
}
}我們已經將 Fauna 的區域特定端點和密鑰存儲在 application.properties 中,可以將其端點和密鑰注入為映射:
@ConfigurationProperties
public class FaunaClients {
private final Map<String, String> faunaConnections = new HashMap<>();
private final Map<String, String> faunaSecrets = new HashMap<>();
public Map<String, String> getFaunaConnections() {
return faunaConnections;
}
public Map<String, String> getFaunaSecrets() {
return faunaSecrets;
}
}在這裏,我們使用了 @ConfigurationProperties,它將配置屬性注入到我們的類中。為了啓用此註解,我們還需要添加:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>最後,我們需要從相應的地圖中拉取正確的連接端點和密鑰,並根據需要使用它們來創建 FaunaClient:
public FaunaClient getFaunaClient(String region) {
String faunaUrl = faunaConnections.get(region);
String faunaSecret = faunaSecrets.get(region);
log.info("Creating Fauna Client for Region: {} with URL: {}", region, faunaUrl);
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}我們還添加了一個日誌,用於檢查在創建客户端時是否正確選擇了 Fauna URL。
7.2. 在健康服務中使用區域特定物種客户端
一旦我們的客户端準備就緒,我們就可以在我們的健康服務中使用它們,將健康數據發送到 Fauna。
讓我們注入 FaunaClients:
public class DefaultHealthService implements HealthService {
@Autowired
private FaunaClients faunaClients;
// ...
}接下來,我們通過從先前從GeoLocationService中提取的區域信息,獲取特定區域的FaunaClient:
public void process(HealthData healthData) {
String region = geoLocationService.getRegion(
healthData.latitude(),
healthData.longitude());
FaunaClient faunaClient = faunaClients.getFaunaClient(region);
}一旦我們獲取了特定區域的 FaunaClient,我們就可以使用它將健康數據插入到特定的數據庫中。
我們將基於我們現有的 Faunadb Spring Web App 文章,該文章中我們編寫了多個 CRUD 查詢,以與 Fauna 配合使用 FQL(Fauna 查詢語言)。
讓我們添加一個用於在 Fauna 中創建健康數據的查詢;我們將從關鍵字 Create 開始,並提及用於插入數據的集合名稱:
Value queryResponse = faunaClient.query(
Create(Collection("healthdata"), //)
).get();接下來,我們將創建要插入的實際數據對象。我們將定義對象的屬性及其值作為Map 的條目,並使用 FQL 的 Value 關鍵字進行包裝:
Create(Collection("healthdata"),
Obj("data",
Obj(Map.of(
"userId", Value(healthData.userId())))))
)在這裏,我們正在從健康數據記錄中讀取 userId,並將其映射到我們插入的文檔中的 userId 字段。
同樣,我們也可以對所有剩餘的屬性執行相同的操作:
Create(Collection("healthdata"),
Obj("data",
Obj(Map.of(
"userId", Value(healthData.userId()),
"temperature", Value(healthData.temperature()),
"pulseRate", Value(healthData.pulseRate()),
"bpSystolic", Value(healthData.bpSystolic()),
"bpDiastolic", Value(healthData.bpDiastolic()),
"latitude", Value(healthData.latitude()),
"longitude", Value(healthData.longitude()),
"timestamp", Now()))))最後,讓我們記錄查詢的響應,以便在查詢執行過程中瞭解任何問題:
log.info("Query response received from Fauna: {}", queryResponse);
注意:為了本文的目的,我們已將 Edge 服務構建為 Spring Boot 應用程序。在生產環境中,這些服務可以使用任何語言構建,並由 Edge 提供商(如 Fastly、Cloudflare Workers、Lambda@Edge 等)在全球網絡上部署。
我們的集成已完成,現在讓我們使用集成測試來測試整個流程。
8. 端到端集成測試
讓我們添加一個測試,以驗證我們的集成是否正常工作,以及我們的請求是否發送到正確的 Fauna 區域。我們將對 GeoLocationService 進行模擬,以便在測試中切換區域:
@SpringBootTest
class DefaultHealthServiceTest {
@Autowired
private DefaultHealthService defaultHealthService;
@MockBean
private GeoLocationService geoLocationService;
// ...
} 讓我們添加一個針對歐盟地區的測試:
@Test
void givenEURegion_whenProcess_thenRequestSentToEURegion() {
HealthData healthData = new HealthData("user-1-eu",
37.5f,
99f,
120, 80,
51.50, -0.07,
ZonedDateTime.now());
// ...
}接下來,讓我們模擬區域並調用 process 方法:
when(geoLocationService.getRegion(51.50, -0.07)).thenReturn("EU");
defaultHealthService.process(healthData);當我們運行測試時,可以在日誌中查看正確 URL 已被 fetched,用於創建 FaunaClient:
Creating Fauna Client for Region:EU with URL:https://db.eu.fauna.com/我們還可以檢查來自 Fauna 服務器返回的響應,以確認記錄已正確創建:
Query response received from Fauna:
{
ref: ref(id = "338686945465991375",
collection = ref(id = "healthdata", collection = ref(id = "collections"))),
ts: 1659255891215000,
data: {bpDiastolic: 80,
userId: "user-1-eu",
temperature: 37.5,
longitude: -0.07, latitude: 51.5,
bpSystolic: 120,
pulseRate: 99.0,
timestamp: 2022-07-31T08:24:51.164033Z}}我們還可以通過在我們的Fauna儀表盤的 HealthData 集合中驗證同一記錄,用於歐盟數據庫:
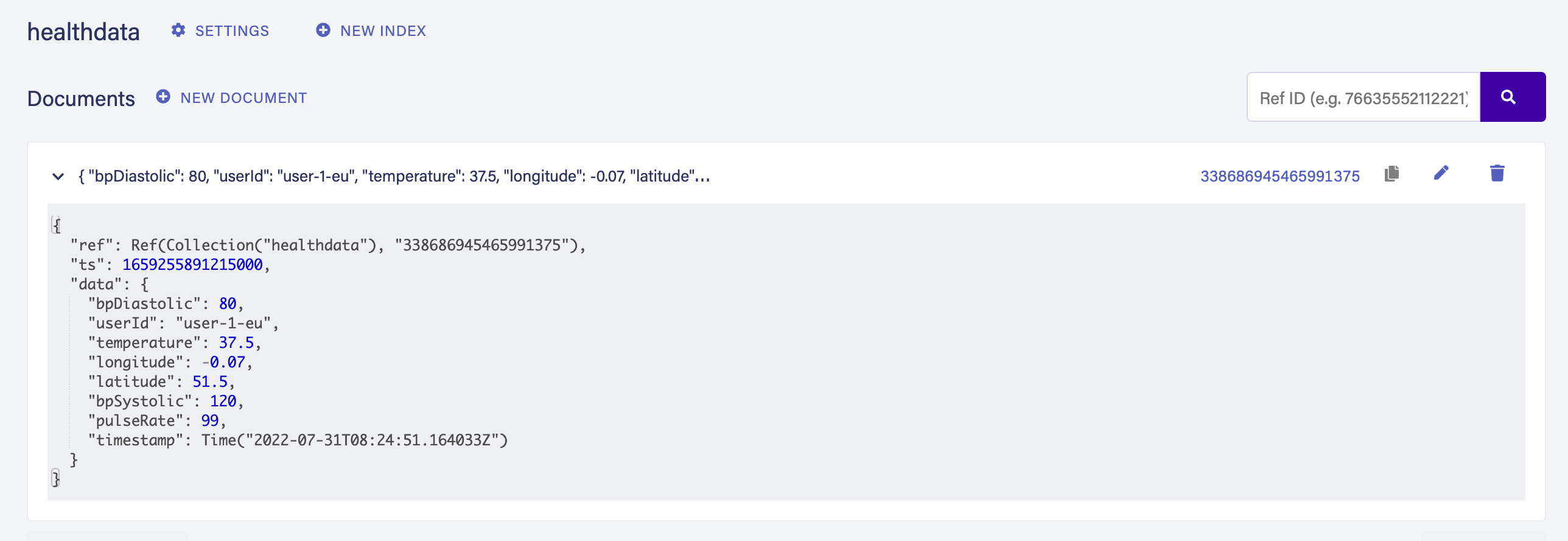
同樣,我們也可以添加針對美國地區的測試:
@Test
void givenUSRegion_whenProcess_thenRequestSentToUSRegion() {
HealthData healthData = new HealthData("user-1-us", //
38.0f, //
100f, //
115, 85, //
40.75, -74.30, //
ZonedDateTime.now());
when(geoLocationService.getRegion(40.75, -74.30)).thenReturn("US");
defaultHealthService.process(healthData);
}9. 結論
在本文中,我們探討了如何利用Fauna的分佈式、文檔關係型和無服務器特性,將其用作物聯網應用程序的數據庫。Fauna的區域組(Region groups)解決了基礎設施的地域問題,並減輕了邊緣服務器的延遲問題。
所有在此處展示的代碼均可在Github上找到。
