1. 引言
在本文中,我們將使用 Spring 和 Java 17 構建一個由 Fauna 數據庫服務 驅動的博客後端服務。
注意: 本文使用了 Fauna Query 語言的舊版本。請參考 Fauna 的文檔 以獲取最新的查詢語言版本。
2. 項目設置
我們需要在開始構建服務之前執行一些初始設置步驟,具體來説,我們需要創建一個 Fauna 數據庫和一個空白的 Spring 應用。
2.1. 創建 Fauna 數據庫
在開始之前,我們需要一個 Fauna 數據庫進行操作。 如果我們還沒有一個,則需要創建一個新的 Fauna 賬户。
完成創建賬户後,我們可以創建一個新的數據庫。 為此指定一個名稱和區域,並選擇不包含演示數據,因為我們希望構建自己的模式:
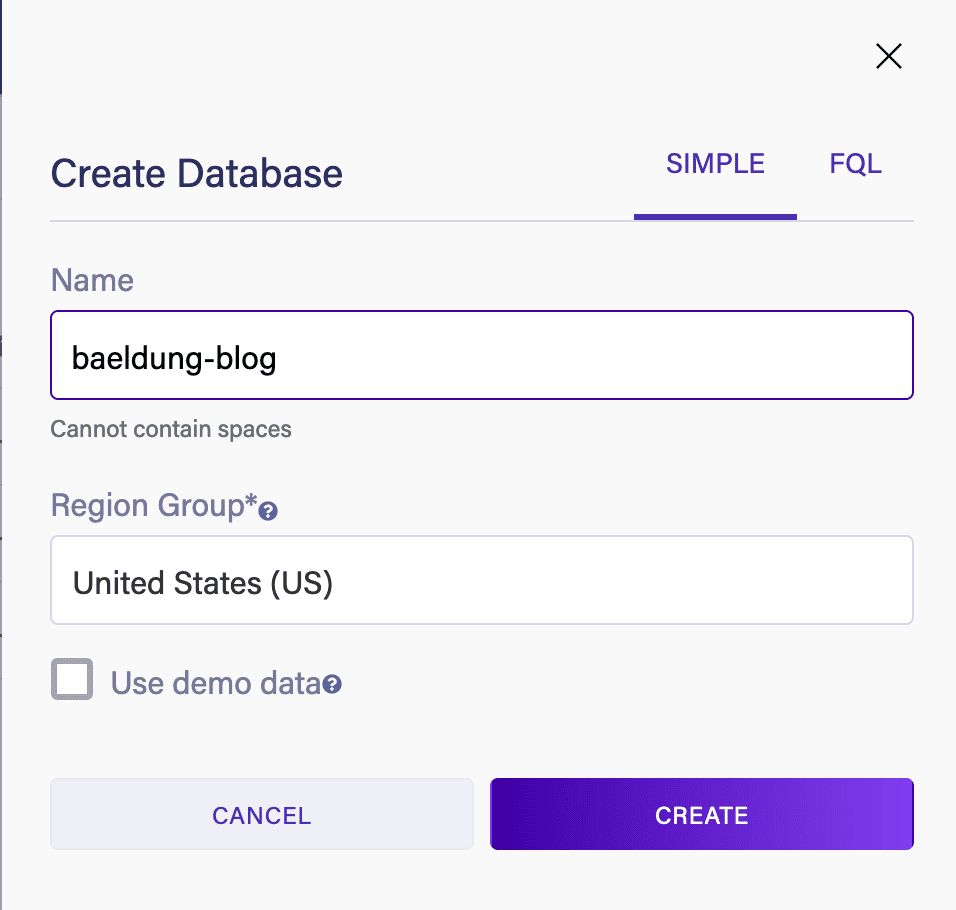
接下來,我們需要創建一個安全密鑰以從我們的應用程序訪問它。 可以在數據庫的“安全”選項卡中完成此操作:
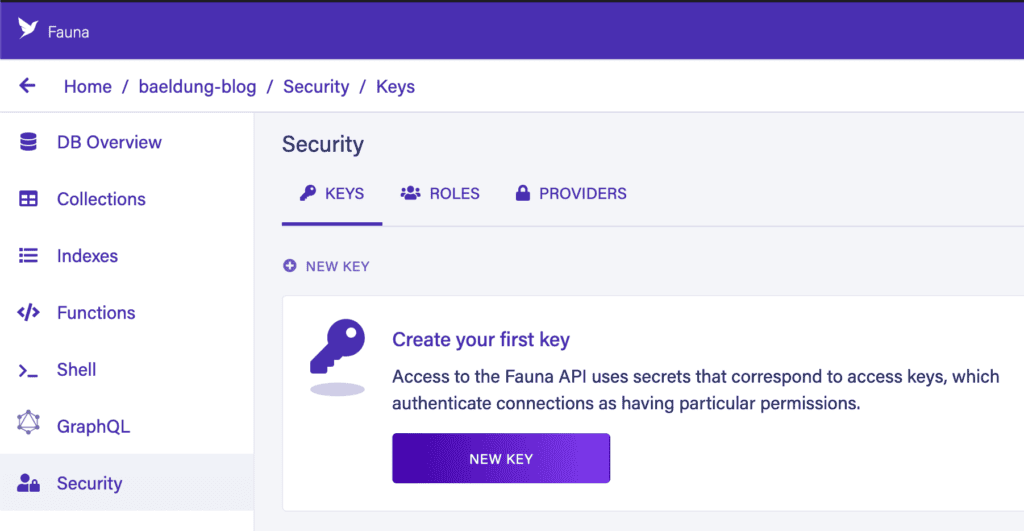
在這裏,我們需要選擇“角色”為“Server”,並且可以選擇為密鑰指定一個名稱。 這意味着密鑰可以訪問此數據庫,但僅此數據庫。 此外,我們還有一個“Admin”選項,可用於訪問帳户中的任何數據庫:
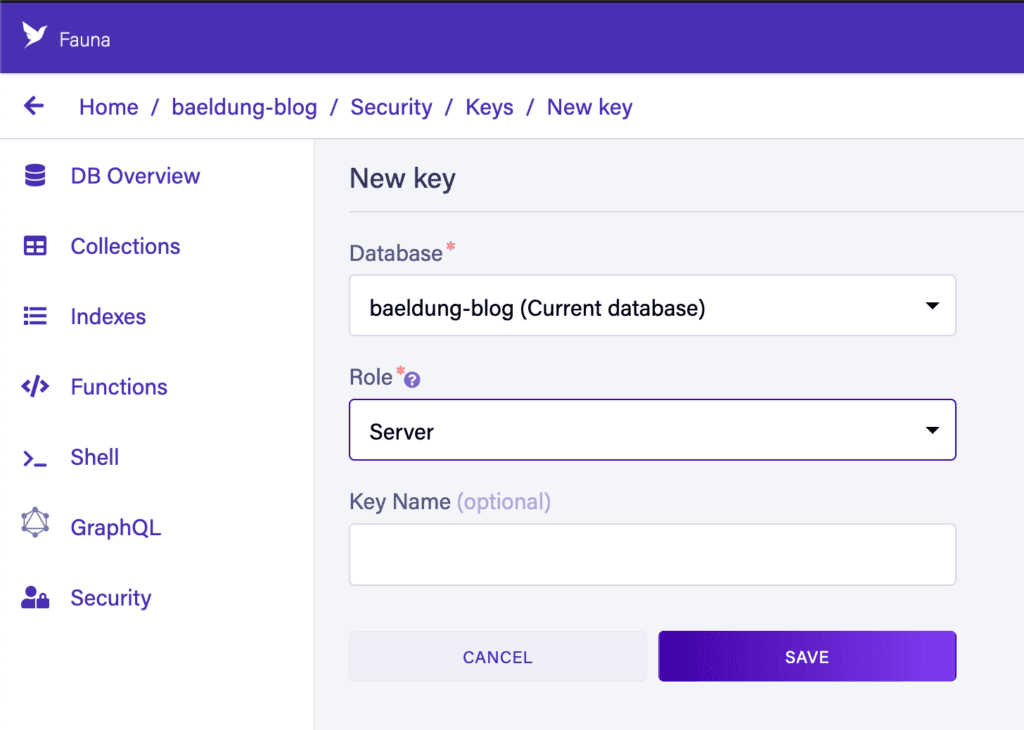
完成這些步驟後,我們需要記錄我們的密鑰。 這對於訪問服務是必需的,但離開此頁面後將無法再次獲取它,出於安全原因。
2.2. 創建 Spring 應用
在我們擁有數據庫之後,我們可以創建我們的應用程序。由於這將是一個 Spring Web 應用,因此最好從 Spring Initializr 進行啓動。
我們希望選擇使用最新版本的 Spring 和最新 LTS 版本的 Java(當時編寫時,這些是 Spring 2.6.2 和 Java 17)創建一個 Maven 項目:
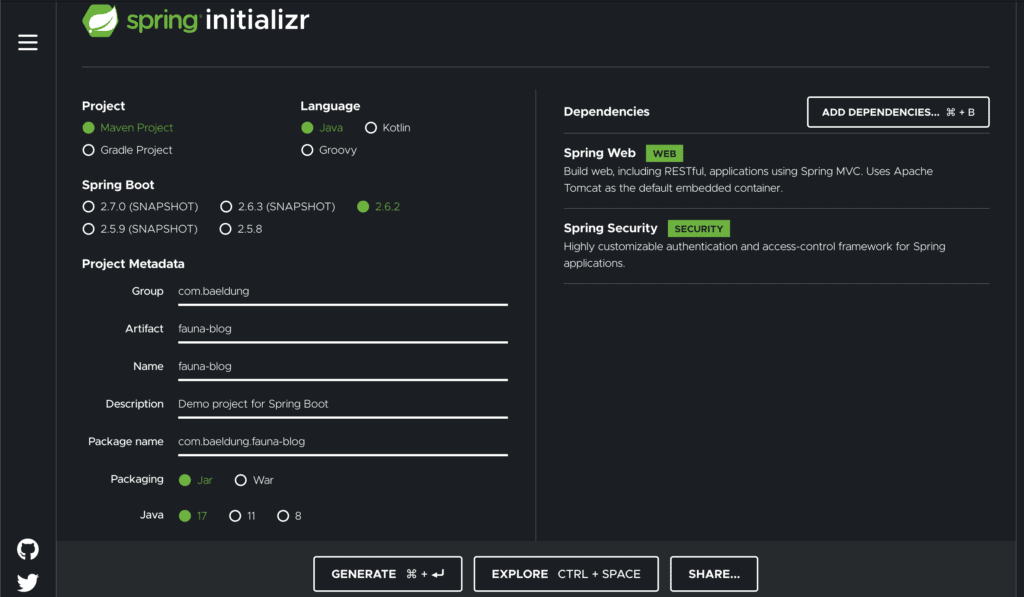
完成這些步驟後,我們可以點擊“Generate”按鈕下載我們的啓動項目。
接下來,我們需要將 Fauna 驅動程序添加到我們的項目中。這通過將依賴項添加到生成的 pom.xml 文件中來實現:
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>此時,我們應該能夠執行 mvn install 命令,併成功下載所需的所有內容。
2.3. 配置 Fauna 客户端
在擁有一個 Spring Web 應用後,我們需要一個 Fauna 客户端來使用數據庫。
首先,我們需要進行一些配置。為此,我們將向我們的 application.properties 文件添加兩個屬性,提供數據庫的正確值:
fauna.region=us
fauna.secret=<Secret>然後,我們需要一個新的 Spring 配置類來構建 Fauna 客户端:
@Configuration
class FaunaConfiguration {
@Value("https://db.${fauna.region}.fauna.com/")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
@Bean
FaunaClient getFaunaClient() throws MalformedURLException {
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}
}這使得 FaunaClient 實例對 Spring 容器可用,供其他 Bean 使用。
3. 添加用户支持
在為我們的 API 添加帖子支持之前,我們需要支持將編寫這些帖子的人員。為此,我們將使用 Spring Security 並將其連接到表示用户記錄的 Fauna 集合。
3.1. 創建用户集合
首先,我們想要創建集合。這通過在數據庫中導航到“集合”屏幕,使用“新建集合”按鈕,並填寫表單來完成。在本例中,我們想要創建一個名為“users”的集合,並使用默認設置:
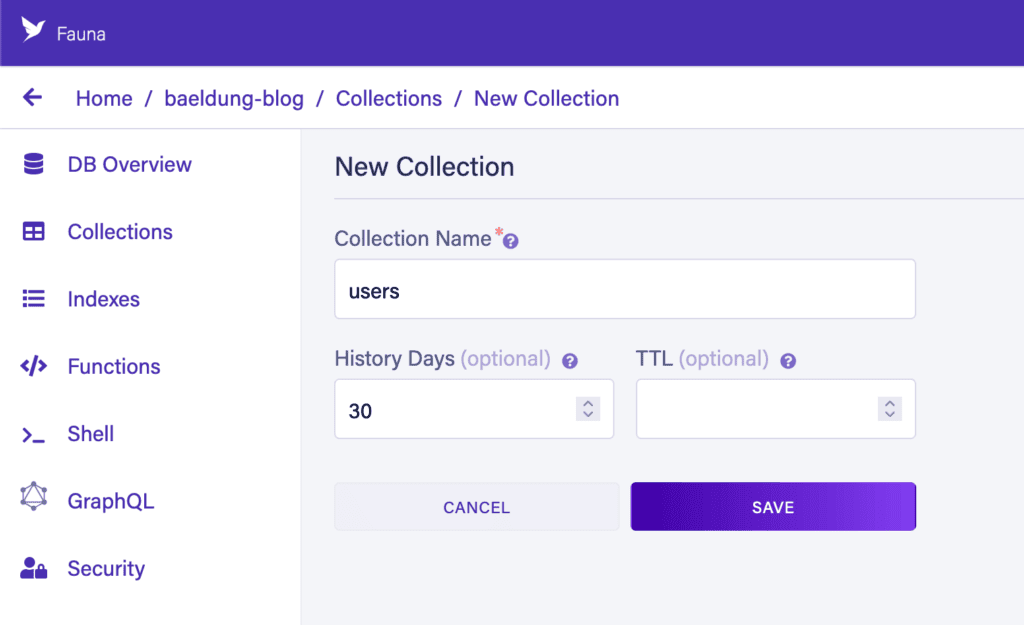
接下來,我們將添加一個用户記錄。為此,我們在集合中的“新建文檔”按鈕上進行操作,並提供以下 JSON:
{
"username": "baeldung",
"password": "Pa55word",
"name": "Baeldung"
}請注意,我們在這裏以明文形式存儲密碼。請務必記住,這種做法非常糟糕,僅為本教程的便利性而做。
最後,我們需要建立索引。 每次我們想通過除了參考字段之外的任何字段訪問記錄時,都需要創建一個索引,以便我們能夠執行此操作。 在這裏,我們想通過用户名訪問記錄。 這通過按下“新建索引”按鈕並填寫表單來完成:
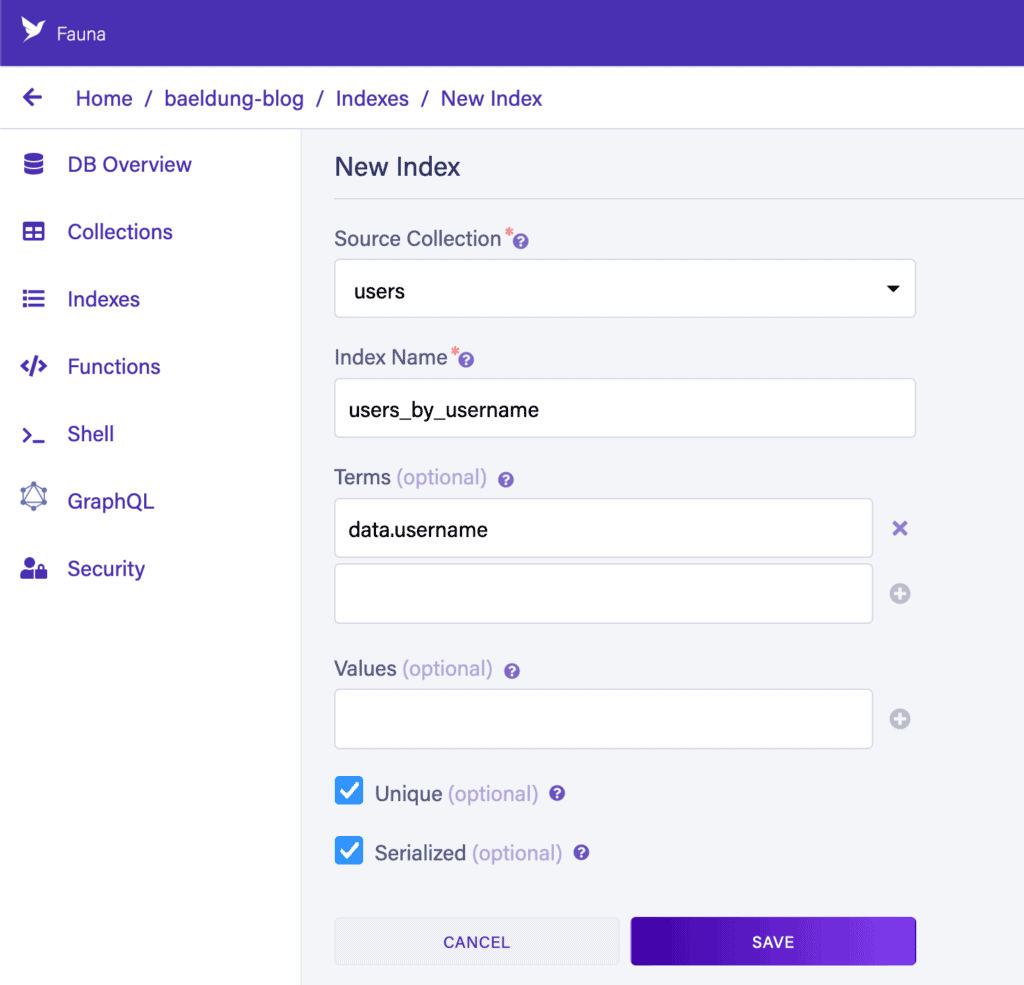
現在,我們就可以使用“users_by_username”索引編寫FQL查詢來查找我們的用户。 例如:
Map(
Paginate(Match(Index("users_by_username"), "baeldung")),
Lambda("user", Get(Var("user")))
)以上將返回我們之前創建的記錄。
3.2. 使用Fauna進行身份驗證
現在我們已經擁有一個Fauna中的用户集合,可以配置Spring Security來使用它進行身份驗證。
要實現這一點,首先需要一個UserDetailsService,該類用於在Fauna中查找用户:
public class FaunaUserDetailsService implements UserDetailsService {
private final FaunaClient faunaClient;
// standard constructors
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
try {
Value user = faunaClient.query(Map(
Paginate(Match(Index("users_by_username"), Value(username))),
Lambda(Value("user"), Get(Var("user")))))
.get();
Value userData = user.at("data").at(0).orNull();
if (userData == null) {
throw new UsernameNotFoundException("User not found");
}
return User.withDefaultPasswordEncoder()
.username(userData.at("data", "username").to(String.class).orNull())
.password(userData.at("data", "password").to(String.class).orNull())
.roles("USER")
.build();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException(e);
}
}
}接下來,我們需要一些 Spring 配置來設置它。這是標準的 Spring Security 配置,用於連接上述 UserDetailsService:
@Configuration
@EnableWebSecurity
@EnableMethodSecurity
public class WebSecurityConfiguration {
@Autowired
private FaunaClient faunaClient;
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http.csrf(CsrfConfigurer::disable)
.authorizeHttpRequests(requests -> requests.requestMatchers("/**")
.permitAll())
.httpBasic(Customizer.withDefaults());
return http.build();
}
@Bean
public UserDetailsService userDetailsService() {
return new FaunaUserDetailsService(faunaClient);
}
}此時,我們可以將標準 @PreAuthorize 註解添加到我們的代碼中,並根據請求的認證詳情是否存在於我們的“users”集合中,決定接受或拒絕請求。
4. 支持列表帖功能
我們的博客服務如果不能支持“帖子”的概念,那就不具有突出的特點。 這些是實際撰寫並可供他人閲讀的博客文章。
4.1. 創建 Posts 集合
正如之前所述,首先需要一個集合來存儲帖子。這個集合創建方式相同,只是名稱改為“posts”,而不是“users”。 我們將包含四個字段:
- title – 帖子的標題。
- content – 帖子的內容。
- created – 帖子創建的時間戳。
- authorRef – 帖子的作者“users”記錄的引用。
我們還需要兩個索引。第一個索引是“posts_by_author”,它將允許我們搜索具有特定作者的“posts”記錄:
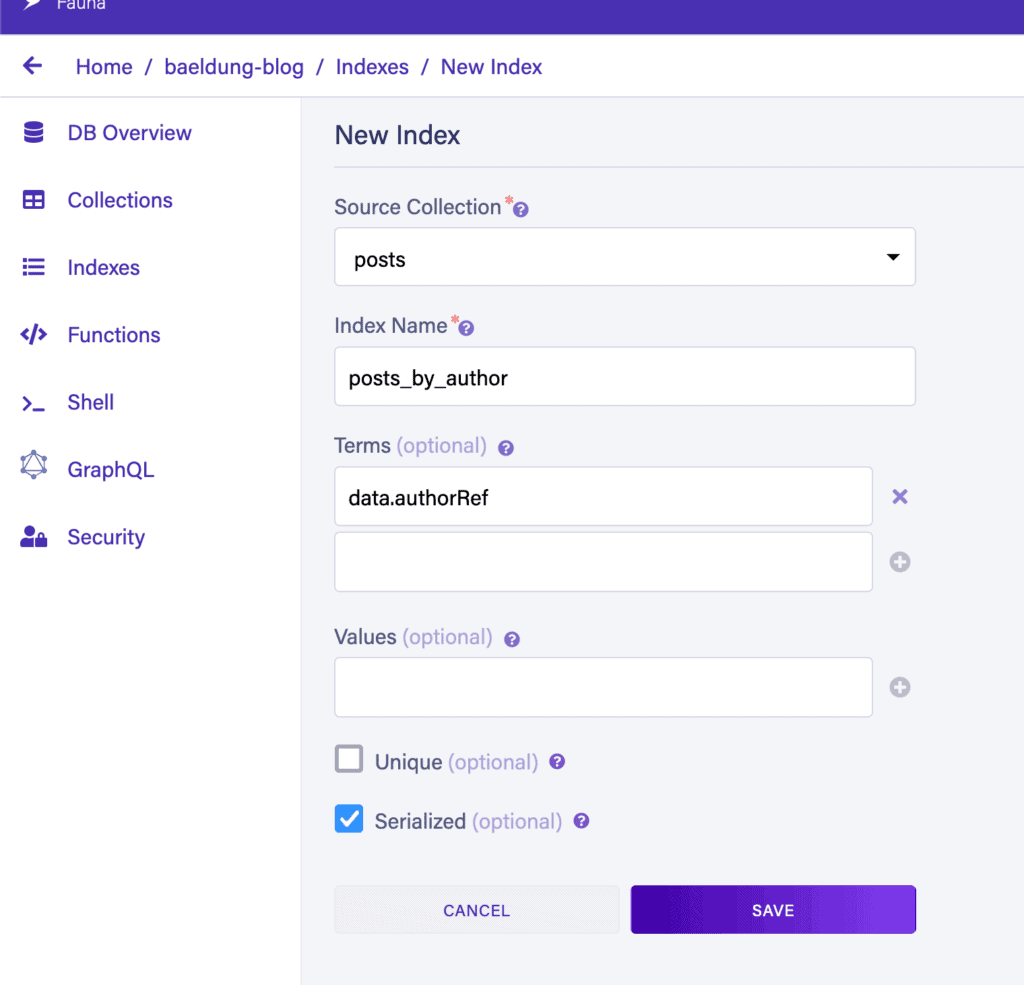
第二個索引是“posts_sort_by_created_desc”。這將允許我們按創建日期對結果進行排序,以便首先返回最近創建的帖子。由於它依賴於 web UI 中不可用的功能,因此創建方式不同——索引存儲值的方式是反向的。
為此,我們需要在 Fauna Shell 中執行一段 FQL:
CreateIndex({
name: "posts_sort_by_created_desc",
source: Collection("posts"),
terms: [ { field: ["ref"] } ],
values: [
{ field: ["data", "created"], reverse: true },
{ field: ["ref"] }
]
})網頁 UI 執行的所有操作,同樣可以通過這種方式實現,從而對確切執行的內容進行更精細的控制。
然後,我們可以使用 Fauna Shell 創建一個帖子,以獲取一些初始數據:
Create(
Collection("posts"),
{
data: {
title: "My First Post",
contents: "This is my first post",
created: Now(),
authorRef: Select("ref", Get(Match(Index("users_by_username"), "baeldung")))
}
}
)在這裏,我們需要確保“authorRef”的值是我們在之前創建的“users”記錄中的正確值。我們通過查詢“users_by_username”索引來獲取ref,通過查找我們的用户名來獲取。
4.2. Posts 服務
現在我們已經支持在 Fauna 中使用帖子,因此可以在應用程序中構建一個服務層來與之交互。
首先,我們需要一些 Java 記錄來表示我們獲取的數據。這將包括一個 作者 (Author) 和一個 帖子 (Post) 記錄類:
public record Author(String username, String name) {}
public record Post(String id, String title, String content, Author author, Instant created, Long version) {}現在,我們可以開始我們的 Posts 服務。這將是一個 Spring 組件,它封裝了 FaunaClient 並使用它來訪問數據存儲:
@Component
public class PostsService {
@Autowired
private FaunaClient faunaClient;
}
4.3. 獲取所有帖子
在我們的 PostsService 中,我們現在可以實現一個方法來獲取所有帖子。 在這一階段,我們不關心分頁和使用默認值——這意味着從結果集中取前 64 個文檔。
要實現這一點,我們將向我們的 PostsService 類添加以下方法:
List<Post> getAllPosts() throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Documents(Collection("posts")),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}這會執行一個查詢,從“posts”集合中檢索所有文檔,並按照“posts_sort_by_created_desc”索引進行排序。
然後,它應用了一個 Lambda 函數來構建響應,該響應包含每個條目的兩個文檔——帖子本身和帖子的作者。
現在,我們需要能夠將此響應轉換回我們的 Post 對象:
private Post parsePost(Value entry) {
var author = entry.at("author");
var post = entry.at("post");
return new Post(
post.at("ref").to(Value.RefV.class).get().getId(),
post.at("data", "title").to(String.class).get(),
post.at("data", "contents").to(String.class).get(),
new Author(
author.at("data", "username").to(String.class).get(),
author.at("data", "name").to(String.class).get()
),
post.at("data", "created").to(Instant.class).get(),
post.at("ts").to(Long.class).get()
);
}它從我們的查詢結果中提取單個結果,提取所有其值,並構建出更豐富的對象。
請注意,“ts”字段是記錄上次更新的時間戳,但它不是 Fauna 的 Timestamp 類型。 而是 Long 類型,表示自 UNIX 紀元以來微秒數。 在本例中,我們將其視為一個不透明的版本標識符,而不是將其解析為時間戳。
4.4. 獲取單個作者的文章
我們還希望檢索特定作者的所有文章,而不是所有已發佈的文章。 這需要使用我們的“posts_by_author”索引,而不是簡單地匹配每個文檔。
我們還會鏈接到“users_by_username”索引,以便按用户名查詢,而不是按用户記錄的引用。
為此,我們將向 PostsService 類添加一個新的方法:
List<Post> getAuthorPosts(String author) throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Match(Index("posts_by_author"), Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}4.5. Posts 控制器
現在,我們能夠編寫 Posts 控制器,它將允許 HTTP 請求訪問我們的服務以檢索帖子。該控制器將監聽“/posts” URL,並根據是否提供“author”參數,返回所有帖子或單個作者的帖子。
@RestController
@RequestMapping("/posts")
public class PostsController {
@Autowired
private PostsService postsService;
@GetMapping
public List<Post> listPosts(@RequestParam(value = "author", required = false) String author)
throws Exception {
return author == null
? postsService.getAllPosts()
: postsService.getAuthorPosts(author);
}
}此時,我們可以啓動我們的應用程序並向 /posts 或 /posts?author=baeldung 發送請求,並獲取結果:
[
{
"author": {
"name": "Baeldung",
"username": "baeldung"
},
"content": "Introduction to FaunaDB with Spring",
"created": "2022-01-25T07:36:24.563534Z",
"id": "321742264960286786",
"title": "Introduction to FaunaDB with Spring",
"version": 1643096184600000
},
{
"author": {
"name": "Baeldung",
"username": "baeldung"
},
"content": "This is my second post",
"created": "2022-01-25T07:34:38.303614Z",
"id": "321742153548038210",
"title": "My Second Post",
"version": 1643096078350000
},
{
"author": {
"name": "Baeldung",
"username": "baeldung"
},
"content": "This is my first post",
"created": "2022-01-25T07:34:29.873590Z",
"id": "321742144715882562",
"title": "My First Post",
"version": 1643096069920000
}
]5. 創建和更新帖子
目前,我們擁有一個完全只讀的服務,可以檢索最新的帖子。 但是,為了提供更好的幫助,我們也希望能夠創建和更新帖子。
5.1. 創建新帖子
首先,我們將支持創建新帖子。為此,我們將向我們的 PostsService 添加一個新的方法:
public void createPost(String author, String title, String contents) throws Exception {
faunaClient.query(
Create(Collection("posts"),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents),
"created", Now(),
"authorRef", Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))
)
)
)
).get();
}如果這看起來很熟悉,那它就是我們在 Fauna 殼中創建新帖子的 Java 對應版本。
接下來,我們可以添加一個控制器方法,允許客户端創建帖子的內容。為此,我們首先需要一個 Java 記錄來表示傳入的請求數據:
public record UpdatedPost(String title, String content) {}現在,我們可以創建一個新的控制器方法在 PostsController 中來處理請求:
@PostMapping
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void createPost(@RequestBody UpdatedPost post) throws Exception {
String name = SecurityContextHolder.getContext().getAuthentication().getName();
postsService.createPost(name, post.title(), post.content());
}請注意,我們使用@PreAuthorize註解來確保請求已進行身份驗證,然後使用已驗證用户名的值作為新帖子的作者。
此時,啓動服務並向端點發送 POST 請求將導致在我們的集合中創建一個新記錄,我們可以使用之前的處理程序來檢索該記錄。
5.2. 更新現有文章
同時,我們也可以更新現有文章,而不是創建新的文章。 我們將通過接受帶有新標題和內容的新 PUT 請求來管理它,並更新文章以包含這些值。
正如之前一樣,我們需要在 PostsService 中添加一個新的方法來支持此功能:
public void updatePost(String id, String title, String contents) throws Exception {
faunaClient.query(
Update(Ref(Collection("posts"), id),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents)
)
)
)
).get();
}接下來,我們向 PostsController 添加我們的處理程序:
@PutMapping("/{id}")
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void updatePost(@PathVariable("id") String id, @RequestBody UpdatedPost post)
throws Exception {
postsService.updatePost(id, post.title(), post.content());
}請注意,我們使用相同的請求體來創建和更新帖子。這完全沒問題,因為它們具有相同的結構和含義——即要更新的帖子的新詳細信息。
此時,啓動服務並向正確的 URL 發送 PUT 請求將導致該記錄被更新。但是,如果使用未知的 ID 調用,則會返回錯誤。我們可以使用異常處理方法來解決此問題:
@ExceptionHandler(NotFoundException.class)
@ResponseStatus(HttpStatus.NOT_FOUND)
public void postNotFound() {}這現在會導致嘗試更新一個未知帖子的請求返回 HTTP 404 錯誤。
6. 檢索舊帖子版本
現在我們能夠更新帖子,查看舊版本的帖子會很有幫助。
首先,我們將向我們的 PostsService 添加一個新方法,用於檢索帖子。該方法接受帖子的 ID,以及可選的,我們想要獲取的版本號——換句話説,如果我們提供版本“5”,我們想要返回版本“4”:
Post getPost(String id, Long before) throws Exception {
var query = Get(Ref(Collection("posts"), id));
if (before != null) {
query = At(Value(before - 1), query);
}
var postResult = faunaClient.query(
Let(
"post", query
).in(
Obj(
"post", Var("post"),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Var("post")))
)
)
).get();
return parsePost(postResult);
}
這裏,我們介紹 At 方法,它將使 Fauna 返回指定時間點的具體數據。
我們的版本號只是微秒級別的時間戳,因此我們可以通過簡單地請求在我們要的數據前 1μs 的值來獲取指定時間點的具體數據。
再次強調,我們需要一個控制器方法來處理這些請求。我們將它添加到我們的 PostsController 中:
@GetMapping("/{id}")
public Post getPost(@PathVariable("id") String id, @RequestParam(value = "before", required = false) Long before)
throws Exception {
return postsService.getPost(id, before);
}現在,我們可以獲取單個帖子的獨立版本。調用 /posts/321742144715882562 可以獲取該帖子的最新版本,但調用 /posts/321742144715882562?before=1643183487660000 可以獲取該版本立即之前的版本。
7. 結論
在這裏,我們探討了 Fauna 數據庫的一些特性以及如何使用它們構建應用程序。Fauna 還有很多功能尚未在本指南中涵蓋,為什麼不嘗試將其應用於您下一次的項目呢?
正如往常一樣,這裏展示的所有代碼均可在 GitHub 上找到。
