1. 簡介
在本教程中,我們將探討反應式程序中併發的概念,特別是使用 Spring WebFlux 編寫的反應式程序中的併發。
我們將首先討論併發與反應式編程之間的關係。然後,我們將學習 Spring WebFlux 如何提供對不同反應式服務器庫的併發抽象。
2. 反應式編程的動機
典型的 Web應用程序由多個複雜的、相互作用的部分組成。 其中許多交互是阻塞性的,例如涉及數據庫調用以檢索或更新數據的情況。 另一些交互則獨立且可以並行執行,可能在並行環境中進行。
例如,兩個指向Web服務器的用户請求可以由不同的線程處理。 在 多核 平台上,這在整體響應時間方面具有明顯的優勢。 因此,這種 線程一請求一 的併發模型被稱為:

如圖所示,每個線程一次處理一個請求。
雖然基於線程的併發性解決了我們的一部分問題,但它並不能解決我們單個線程內部大多數交互仍然是阻塞性的事實。 此外,我們用於在Java中實現併發的本機線程會以上下文切換的顯著成本為代價。
與此同時,隨着Web應用程序面臨越來越多的請求,線程一請求一 模型開始無法滿足預期。
因此,我們需要一種能夠幫助我們使用相對較少的線程處理越來越多的請求的併發模型。 這就是採用反應式編程的主要動機之一。
3. 反應式編程中的併發
反應式編程幫助我們從數據流和通過這些數據流傳播的變化的角度來組織程序。 在完全非阻塞的環境中,這可以使我們實現更高的併發性,並更好地利用資源。
然而,反應式編程是否完全脱離了基於線程的併發? 雖然這是一個大膽的説法,反應式編程無疑對實現併發的方式有很大不同。 因此,反應式編程帶來的根本區別在於異步性。
換句話説,程序流程從同步操作的序列轉變為異步事件流。
例如,在反應式模型中,對數據庫的讀取調用不會阻塞調用線程,數據獲取完成後,調用方立即返回一個可訂閲的發佈者,訂閲者可以在事件發生後處理它,甚至可以進一步生成事件:
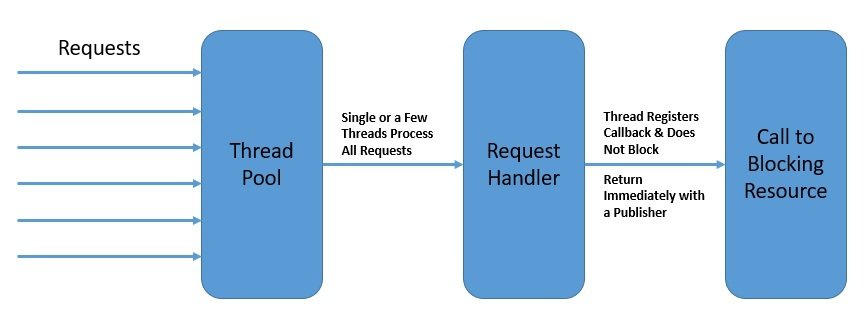
總而言之,反應式編程並不強調哪些線程應該生成和消費事件。 相反,重點在於將程序組織成異步事件流。
發佈者和訂閲者不必位於同一個線程中。 這有助於我們更好地利用可用的線程,從而實現更高的整體併發性。
4. 事件循環
存在多種編程模型來描述反應式併發的方法。
在本節中,我們將研究其中一些,以瞭解如何通過更少的線程實現更高的併發性。
其中一種反應式異步編程模型,用於服務器端,是 事件循環 模型:
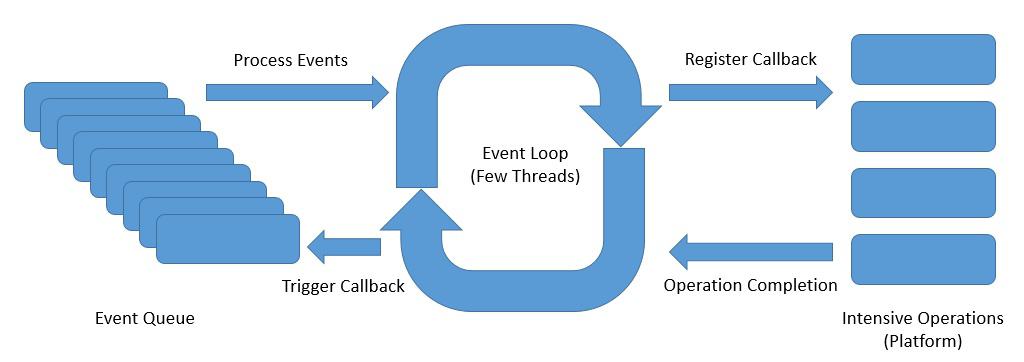
上面是 事件循環 的抽象設計,它呈現了反應式異步編程的思想:
- 事件循環 在一個單線程中持續運行,儘管我們可以有與可用核心數量相同的多個 事件循環。
- 事件循環 順序處理來自 事件隊列 的事件,並在註冊 回調 後立即返回,與 平台 關聯。
- 平台 可以觸發操作的完成,例如數據庫調用或外部服務調用。
- 事件循環 可以根據 操作完成 的通知觸發 回調 並將結果返回給原始調用者。
事件循環 模型 已在多種平台實現,包括 Node.js、Netty 和 Ngnix。它們比傳統的平台,如 Apache HTTP Server、Tomcat 或 JBoss 具有更好的可擴展性。
5. 使用 Spring WebFlux 進行響應式編程
現在我們對響應式編程及其併發模型有了足夠的瞭解,可以探索它在 Spring 中的應用。
Spring WebFlux 是 Spring 的 響應式棧 Web 框架,自 5.0 版本開始引入。
讓我們探索 Spring WebFlux 的服務端棧,以瞭解它如何補充傳統的 Spring Web 棧:
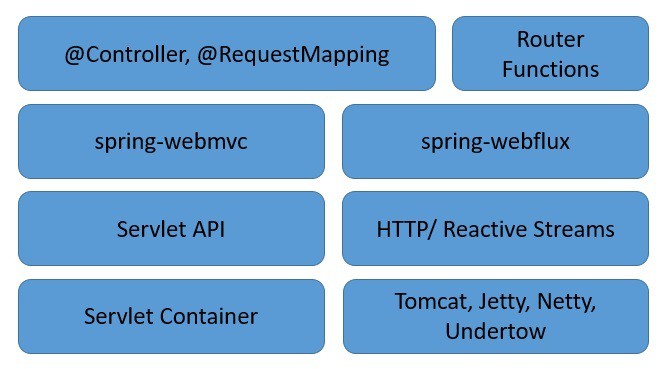
正如我們所見,Spring WebFlux 與傳統的 Spring Web 框架並存,並不一定取代它。
以下是一些需要注意的重要要點:
- Spring WebFlux 擴展了傳統的基於註解的編程模型,並引入了函數式路由。
- 此外,它還適應了底層的 HTTP 運行時,使其符合 Reactive Streams API,從而使運行時相互兼容。
- 它能夠支持多種響應式運行時,包括 Servlet 3.1+ 容器,如 Tomcat、Reactor、Netty 或 Undertow。
- 最後,它包含 WebClient,一個響應式且非阻塞的 HTTP 請求客户端,它提供了功能型和流暢的 API。
6. 支持運行時中的線程模型
正如我們之前討論的,反應式程序通常僅使用少量線程並充分利用它們。但是,線程的數量和類型取決於我們選擇的實際 Reactive Stream API 運行時。
為了更清楚地説明,Spring WebFlux 可以通過 HttpHandler 提供的通用 API 來適應不同的運行時:這個 API 只是一個簡單的約定,僅包含一個方法,它提供了一個對不同服務器 API 的抽象,例如 Reactor Netty、Servlet 3.1 API 或 Undertow API。
讓我們來考察一下其中幾個的線程模型。
雖然 Netty 是 WebFlux 應用程序的默認服務器,但只需聲明正確的依賴項即可切換到任何其他受支持的服務器:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-reactor-netty</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>雖然可以通過多種方式觀察 Java 虛擬機中創建的線程,但從 Thread 類本身直接獲取線程信息非常簡單:
Thread.getAllStackTraces()
.keySet()
.stream()
.collect(Collectors.toList());6.1. Reactor Netty
正如我們所説,Reactor Netty 是 Spring Boot WebFlux starter 的默認嵌入式服務器。 讓我們看看 Netty 默認創建的線程。 為了開始,我們不會添加任何其他依賴項或使用 WebClient。 因此,如果使用其 SpringBoot starter 創建的 Spring WebFlux 應用程序啓動,我們預計將看到它創建的一些默認線程:

請注意,除了用於服務器的正常線程外,Netty 還會為請求處理創建大量的 worker 線程。 這些通常是可用的 CPU 核心。 這是在四核機器上的輸出。 我們還會看到典型的 JVM 環境中的大量 housekeeping 線程,但它們在這裏不重要。
Netty 使用事件循環模型,以高度可擴展的方式提供反應式異步併發。 讓我們看看 Netty 如何實現事件循環 利用 Java NIO 提供這種可擴展性:
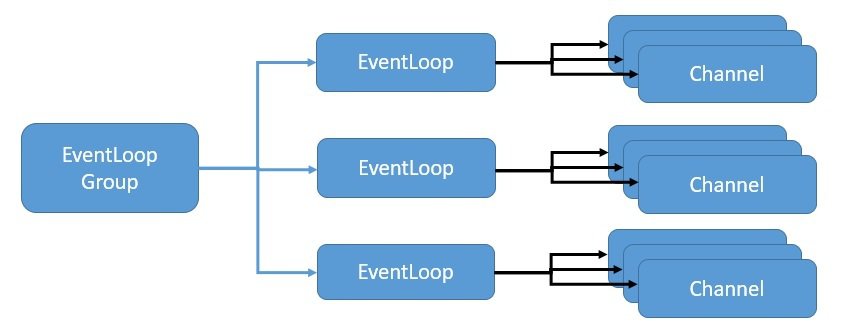
在此,EventLoopGroup 管理一個或多個 EventLoop,這些 EventLoop 必須持續運行。 因此,不建議創建比可用核心數量更多的 EventLoop。
EventLoopGroup 進一步將一個 EventLoop 分配給每個新創建的 Channel。 因此,在 Channel 的整個生命週期中,所有操作都由相同的線程執行。
6.2. Apache Tomcat
Spring WebFlux 也可在傳統的 Servlet 容器上進行支持,例如 Apache Tomcat。
WebFlux 依賴於 Servlet 3.1 API 和非阻塞 I/O。 雖然它在低級適配器後面使用了 Servlet API,但 Servlet API 不可直接使用。
讓我們看看在 Tomcat 上運行的 WebFlux 應用程序中我們期望的線程數量:
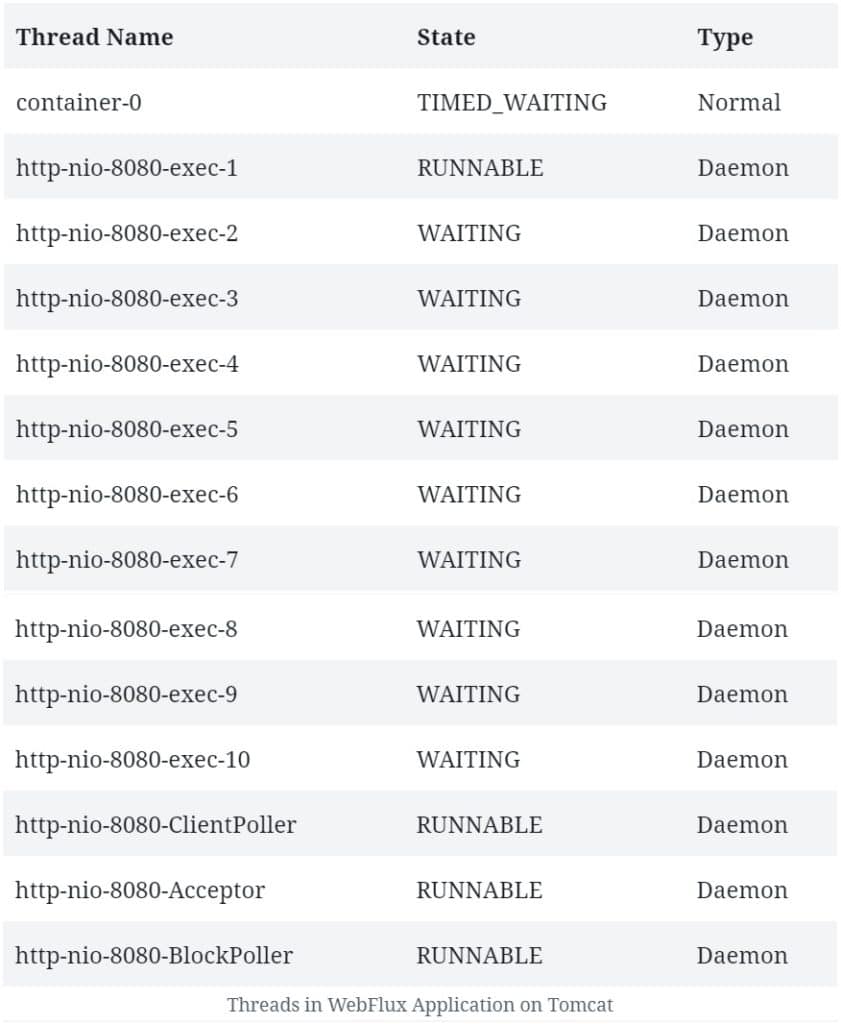
我們在這裏看到的線程數量和類型與我們之前觀察到的差異很大。
首先,Tomcat 啓動了更多的 worker 線程,默認值為十個。 當然,我們還會看到一些典型的 JVM 和 Catalina 容器的 housekeeping 線程,這些線程對於我們的討論來説可以忽略不計。
我們需要了解 Tomcat 與 Java NIO 的架構,以便將其與我們上面看到的線程相關聯。
Tomcat 5 及更高版本支持 NIO 在 Connector 組件中的使用,該組件主要負責接收請求。
Tomcat 的另一個組件是 Container 組件,負責容器管理功能。
我們感興趣的點是 Connector 組件實現的線程模型,它由 Acceptor、Poller 和 Worker 作為 NioEndpoint 模塊的一部分組成:
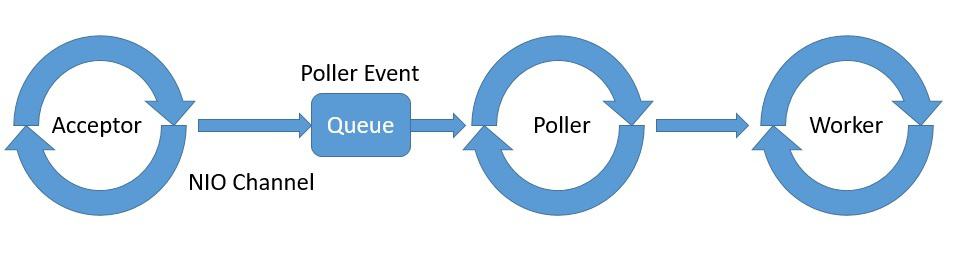
Tomcat 啓動一個或多個用於 Acceptor、Poller 和 Worker 線程,通常使用一個專門用於 Worker 的線程池。
雖然對 Tomcat 架構的詳細討論超出了本文的範圍,但我們現在應該有足夠的見解來理解我們之前看到的線程。
7. WebClient 中的線程模型
WebClient 是 Spring WebFlux 中的一個反應式 HTTP 客户端。我們可以在需要進行基於 REST 的通信的任何時候使用它,從而使我們能夠創建 端到端 反應式應用程序。
正如我們之前所見,反應式應用程序僅使用少量線程,因此任何應用程序的部分都不能阻塞任何線程。因此,WebClient 在幫助我們充分發揮 WebFlux 的潛力方面發揮着至關重要的作用。
7.1. 使用 WebClient
使用 WebClient 非常簡單。 我們不需要包含任何特定的依賴項,因為它屬於 Spring WebFlux 的一部分。
讓我們創建一個簡單的 REST 端點,它返回一個 Mono:
@GetMapping("/index")
public Mono<String> getIndex() {
return Mono.just("Hello World!");
}然後,我們將使用 WebClient 調用該 REST 端點並以反應式方式消耗數據:
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.doOnNext(s -> printThreads());我們在這裏還打印了使用我們之前討論過的方法的線程。
7.2. 理解線程模型
那麼,在 <em >WebClient</em> 的情況下,線程模型是如何工作的呢?
實際上,<em >WebClient</em> 同樣使用 <em >事件循環模型</em> 實現併發。當然,它依賴於底層運行時提供必要的基礎設施。
如果我們在 Reactor Netty 上運行 <em >WebClient</em>,它將共享 Netty 為服務器使用的事件循環。因此,在這種情況下,我們可能不會注意到創建的線程數量上有什麼不同。
然而,<em >WebClient</em> 還可以在 Servlet 3.1+ 容器(如 Jetty)上運行,但此時其工作方式有所不同。
如果我們比較在運行 WebFlux 應用程序時,使用 Jetty 以及不使用 <em >WebClient</em> 時創建的線程數量,我們會注意到一些額外的線程。
在這裏,<em >WebClient</em> 必須創建其自身的 <em >事件循環</em>。因此,我們可以看到這個事件循環創建的固定數量的處理線程:
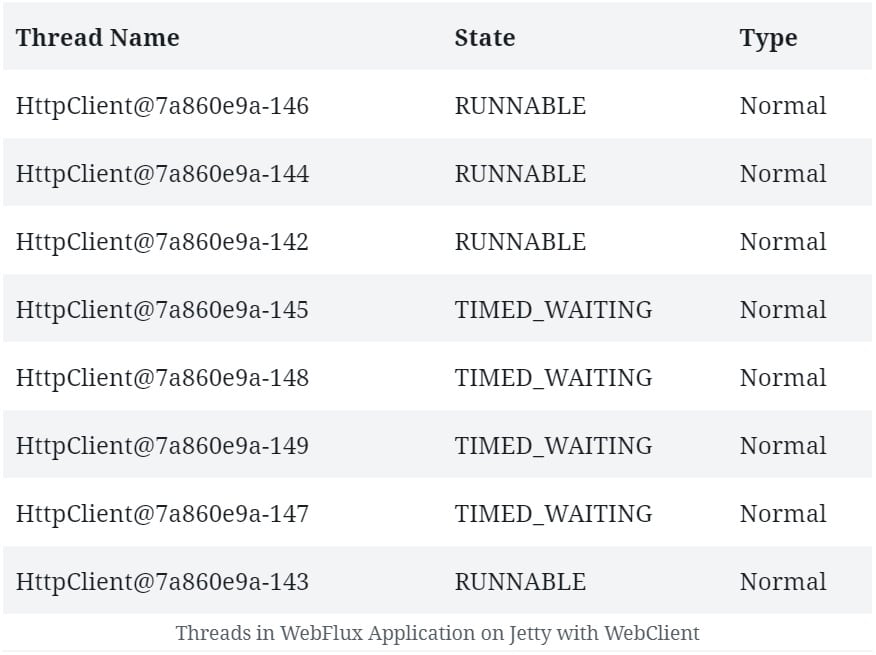
在某些情況下,為客户端和服務器分別使用獨立的線程池可以提供更好的性能。雖然這並非 Netty 的默認行為,但如果需要,仍然可以為 <em >WebClient</em> 聲明一個專門的線程池。
我們將如何在後面的章節中看到這一點。
8. 數據訪問庫中的線程模型
正如我們之前所見,即使一個簡單的應用程序通常由多個需要連接的部分組成。
這些部分中的典型示例包括數據庫和消息代理。目前連接到許多這些庫仍然是阻塞式的,但這種情況正在迅速變化。
現在有幾個數據庫提供用於連接的反應式庫。許多這些庫在 Spring Data 中可用,我們也可以直接使用它們。
這些庫使用的線程模型對我們來説尤其重要。
8.1. Spring Data MongoDB
Spring Data MongoDB 提供基於 MongoDB Reactive Streams 驅動程序的反應式存儲庫支持。 尤其值得注意的是,該驅動程序完全實現了 Reactive Streams API,以提供異步流處理和非阻塞背壓。
在 Spring Boot 應用程序中設置 MongoDB 反應式存儲庫支持,只需添加一個依賴項即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>這將使我們能夠創建一個存儲庫,並使用它以非阻塞的方式對 MongoDB 執行一些基本操作:
public interface PersonRepository extends ReactiveMongoRepository<Person, ObjectId> {
}
.....
personRepository.findAll().doOnComplete(this::printThreads);我們能看到什麼類型的線程當我們在 Netty 服務器上運行這個應用程序呢?
當然,正如預料的那樣,由於 一個 Spring Data 反應式倉庫 利用了與服務器相同的事件循環,因此不會有太大的差異。
8.2. Reactor Kafka
Spring 仍在積極構建對 Reactive Kafka 的全面支持。 不過,我們也有一些在 Spring 之外的選項。
Reactor Kafka 是基於 Reactor 的 Reactive API,用於 Kafka。Reactor Kafka 允許使用函數式 API 發佈和消費消息,並具有 非阻塞背壓。
首先,我們需要在應用程序中添加所需的依賴項,才能開始使用 Reactor Kafka:
<dependency>
<groupId>io.projectreactor.kafka</groupId>
<artifactId>reactor-kafka</artifactId>
<version>1.3.10</version>
</dependency>這將使我們能夠以非阻塞的方式向 Kafka 生產消息:
// producerProps: Map of Standard Kafka Producer Configurations
SenderOptions<Integer, String> senderOptions = SenderOptions.create(producerProps);
KafkaSender<Integer, String> sender = KafkaSender.create(senderOptions);
Flux<SenderRecord<Integer, String, Integer>> outboundFlux = Flux
.range(1, 10)
.map(i -> SenderRecord.create(new ProducerRecord<>("reactive-test", i, "Message_" + i), i));
sender.send(outboundFlux).subscribe();同樣,我們應該能夠以非阻塞的方式消費來自 Kafka 的消息:
// consumerProps: Map of Standard Kafka Consumer Configurations
ReceiverOptions<Integer, String> receiverOptions = ReceiverOptions.create(consumerProps);
receiverOptions.subscription(Collections.singleton("reactive-test"));
KafkaReceiver<Integer, String> receiver = KafkaReceiver.create(receiverOptions);
Flux<ReceiverRecord<Integer, String>> inboundFlux = receiver.receive();
inboundFlux.doOnComplete(this::printThreads)這非常簡單且自解釋。
我們訂閲了 Kafka 中的主題 reactive-test,並接收到一條 Flux 消息流。
對我們來説最有趣的是創建的線程:
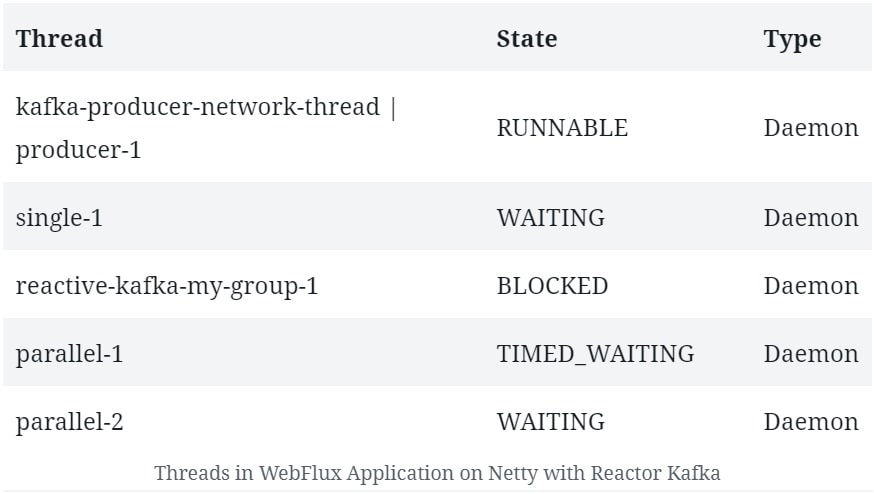
我們可以看到一些與 Netty 服務器不常見的線程。
這表明 Reactor Kafka 自身管理線程池,其中包含一些參與 Kafka 消息處理的工進程。當然,我們還會看到與 Netty 和 JVM 相關的其他線程,這些線程可以忽略不計。
Kafka 生產者使用單獨的網絡線程來向 broker 發送請求。 此外,它們使用一個 單線程池調度器 將響應傳遞給應用程序。
Kafka 消費者,另一方面,為每個消費者組都有一個線程,該線程會阻塞以監聽傳入的消息。 傳入的消息隨後會安排在另一個線程池中進行處理。
9. WebFlux 中的調度選項
我們已經瞭解到,在完全非阻塞的環境中,僅使用少量線程,反應式編程真正發光發熱。但這同時也意味着,如果確實存在阻塞的部分,它會導致性能大幅下降。這是因為阻塞操作會完全凍結事件循環。
因此,我們如何處理反應式編程中的長時間運行進程或阻塞操作?
誠然,最佳方案是儘量避免它們。然而,這並非總是可行的,我們可能需要為應用程序中的某些部分制定專門的調度策略。
Spring WebFlux 提供了一種機制,可以在數據流鏈之間切換到不同的線程池。這使我們能夠對某些任務的調度策略進行精確控制。當然,WebFlux 能夠基於底層反應式庫中提供的調度器(即線程池抽象)來實現這一點。
9.1. 反應器 (Reactor)
在 反應器 (Reactor) 中,<strong><em>調度器 (Scheduler)</em> 類定義了執行模型,以及執行的地點。
<a href="https://projectreactor.io/docs/core/release/api/reactor/core/scheduler/Schedulers.html">調度器 (Schedulers)</strong> 類提供了多種執行上下文,例如 <em>immediate</em>、<em>single</em>、<em>elastic</em> 和 <em>parallel</em>。 這些提供了不同類型的線程池,對於不同的任務很有用。 此外,我們始終可以創建一個具有預現有 ExecutorService 的自定義 Scheduler。
雖然 <em>Scheduler</em> 提供了多種執行上下文,但反應器 <strong>還提供了不同的切換執行上下文的方式</strong>。 這些是publishOn和subscribeOn` 方法。
我們可以使用 <em>publishOn</em> 與鏈中的任何 <em>Scheduler</em> 結合使用,該 <em>Scheduler</em> 會影響所有後續操作符。
雖然我們也可以使用 <em>subscribeOn</em> 與鏈中的任何 <em>Scheduler</em> 結合使用,但它只會影響發射源的上下文。
如果回想一下,WebClient 在 Netty 上共享了服務器端創建的相同 事件循環 (event loop) 作為默認行為。 但是,我們可能出於有充分理由創建 WebClient 的專用線程池。
Scheduler scheduler = Schedulers.newBoundedElastic(5, 10, "MyThreadGroup");
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.publishOn(scheduler)
.doOnNext(s -> printThreads());此前,我們並未觀察到在 Netty 中使用或不使用 WebClient 時線程創建方面存在差異。但是,如果現在運行上述代碼,我們將會觀察到一些新的線程被創建:
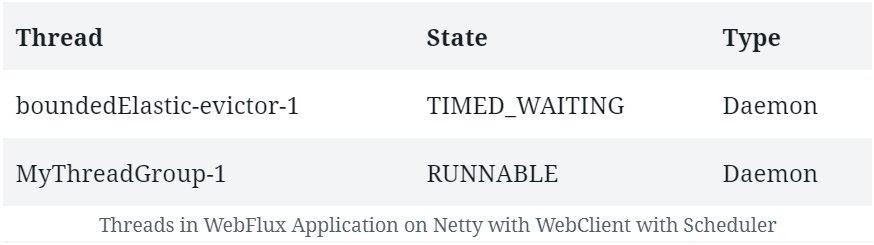
在這裏 我們可以看到這些線程是作為我們 有限彈性線程池 的一部分創建的。這是 WebClient 的響應發佈在此處的環節。
這使得主線程池可以用於處理服務器請求。
9.2. RxJava
默認情況下,RxJava的行為與Reactor非常相似。
Observable及其上應用的所有運算符將在訂閲被調用時執行工作並通知觀察者。 就像Reactor一樣,RxJava也提供了一種在鏈中引入前綴或自定義調度策略的方式。
RxJava還包含一個類<a href="http://reactivex.io/RxJava/javadoc/io.reactivex.schedulers.Schedulers.html">Schedulers</a>,該類提供了對<a href="http://reactivex.io/RxJava/javadoc/io.reactivex.Observable.html"><em>Observable</em></a>鏈的多種執行模型。 這些模型包括<em>new thread</em>、<em>immediate</em>、<em>trampoline</em>、<em>io</em>、<em>computation</em>和<em>test</em>。 當然,它還允許我們定義一個<a href="http://reactivex.io/documentation/scheduler.html">Scheduler</a>,該Scheduler來自Java的<a href="https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/util/concurrent/Executor.html"><em>Executor</em></a>。
此外,RxJava還提供兩個擴展方法來實現這一點,即<em>subscribeOn</em>和<em>observeOn</em>。
<em>subscribeOn</em>方法通過指定<em>Observable</em>應該運行的不同的<em>Scheduler</em>來改變默認行為。 另一方面,<em>observeOn</em>方法指定<em>Observable</em>可以使用該<em>Scheduler</em>向觀察者發送通知。
正如我們之前討論的,Spring WebFlux默認使用Reactor作為其響應式庫。 但是,由於它與Reactive Streams API完全兼容,因此可以切換到另一個Reactive Streams實現,例如RxJava(對於RxJava 1.x及其Reactive Streams適配器)。
我們需要顯式添加依賴:
<dependency>
<groupId>io.reactivex.rxjava2</groupId>
<artifactId>rxjava</artifactId>
<version>2.2.21</version>
</dependency>然後我們可以開始在我們的應用程序中使用 RxJava 類型,例如 Observable,以及 RxJava 相關的 調度器:
io.reactivex.Observable
.fromIterable(Arrays.asList("Tom", "Sawyer"))
.map(s -> s.toUpperCase())
.observeOn(io.reactivex.schedulers.Schedulers.trampoline())
.doOnComplete(this::printThreads);因此,如果運行該應用程序,除了常規的 Netty 和 JVM 相關的線程之外,我們應該看到一些與 RxJava 調度器相關的線程:
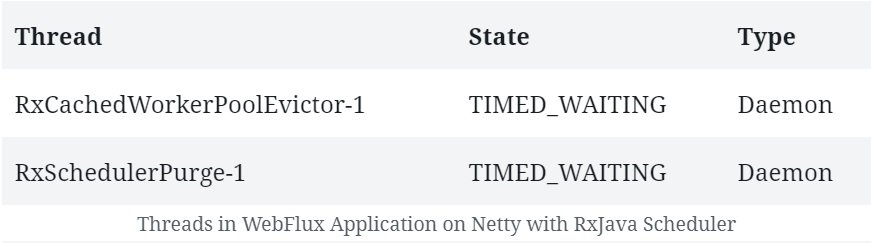
10. 結論
在本文中,我們從併發的角度探討了響應式編程的 premises。我們觀察到傳統響應式編程與併發模型之間的差異,從而得以研究 Spring WebFlux 中的併發模型及其實現方式。
隨後,我們結合了 WebFlux 中的線程模型與不同的 HTTP 運行時和響應式庫,並學習了使用 WebClient 與使用數據訪問庫時線程模型之間的差異。
最後,我們探討了在 WebFlux 中控制程序調度策略的選項。
