1. 概述
與關係數據庫中的大型數據集一起工作可能會對查詢性能構成挑戰。雖然 Hibernate 提供了實體映射的優化,但隨着數據集的擴展,分區變得至關重要。
在本教程中,我們將探討如何使用 Spring Boot 與分區表一起工作。我們將使用 Hibernate 和 Spring Data JPA 處理交互,但我們會看到實際的分區配置是在數據庫本身中進行的,例如 PostgreSQL。
2. 分區鍵的作用
當我們將一個非常大的表分割成更小、更易於管理的小表時,這被稱為分區。每個分區包含一部分數據,通常由分區鍵確定。
在 Hibernate 中,我們可以將特定列映射為分區鍵,以便查詢可以僅針對相關的分區,從而顯著提高查詢速度。
分區創建了每個數據片段的單獨物理表。例如,一個按 saleDate 分區的 Sales 表,我們可能會有 sales_2024_q1、sales_2024_q2 等。這種物理隔離是實現性能提升的關鍵。
我們不能簡單地對現有的、大型表進行分區。該過程需要遷移策略。這通常涉及創建新的分區表結構,然後將舊錶中的數據遷移到新表中。這確保了數據完整性和一致性。
分區方案的真正優勢體現在當我們的查詢包含分區鍵在 WHERE 子句中時。如果查詢未指定分區鍵,則數據庫查詢優化器很可能會搜索所有分區,從而抵消了性能優勢。
3. 設置 PostgreSQL 數據庫
我們將使用 PostgreSQL 作為我們的數據庫。讓我們創建一個包含 分區表 語句的表,在 PostgreSQL 中,我們可能將其定義為:
CREATE TABLE sales (
id BIGINT PRIMARY KEY,
sale_date DATE NOT NULL,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2024_q1 PARTITION OF sales
FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
CREATE TABLE sales_2024_q2 PARTITION OF sales
FOR VALUES FROM ('2024-04-01') TO ('2024-07-01');
-- And so on for other partitions4. 所需依賴
為了創建我們的 REST 端點,我們需要使用 spring-boot-starter-web。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>我們的主要依賴是 spring-boot-starter-data-jpa,用於數據庫交互。它包含了 Spring Data JPA 和 Hibernate,Hibernate 是默認的 JPA 提供者。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>這是用於 PostgreSQL 的 JDBC (Java Database Connectivity) 驅動程序。 JDBC 驅動程序是一個關鍵的軟件組件,它允許我們的 Java 應用程序連接到並與 PostgreSQL 數據庫進行交互:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>5. 設置 Spring Boot 項目
以下是一個清晰的示例,展示瞭如何在 Spring Boot 和 Hibernate 設置中表示分區鍵。
5.1. 數據庫實體設置
首先,讓我們查看實體。我們將創建一個 Sales 實體,並使用 @PartitionKey 註解標記 saleDate 字段,以啓用 Hibernate 的優化:
@Entity
@Table(name = "sales")
public class Sales {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@PartitionKey
private LocalDate saleDate;
private BigDecimal amount;
public Sales(Long id, LocalDate saleDate, BigDecimal amount) {
this.id = id;
this.saleDate = saleDate;
this.amount = amount;
}
public Sales() {
}
}@PartitionKey 是一個自定義註解,指示 Hibernate 該列將作為數據庫表分區的基礎。此註解僅存在於 Hibernate 6.2 及更高版本中。
接下來,我們定義我們的 Repository,它擴展了 JpaRepository 以利用 Spring Data JPA 的強大功能進行數據訪問:
@Repository
public interface SalesRepository extends JpaRepository<Sales, Long> {
}5.2. 設計控制器以測試分區
現在,讓我們創建一個控制器來與我們的 Sales 數據進行交互。<strong><em>testPartition()</em> 和 <em>getAllPartition()</em> 方法演示了保存一個新 Sales 記錄的方式。需要注意的是,在分區表的情況下,數據庫將自動將此記錄放入正確的分區中,基於 saleDate:
@RestController
public class Controller {
@Autowired
SalesRepository salesRepository;
@GetMapping
public ResponseEntity<List<Sales>> getAllPartition() {
return ResponseEntity.ok()
.body(salesRepository.findAll());
}
@GetMapping("add")
public ResponseEntity testPartition() {
return ResponseEntity.ok()
.body(salesRepository.save(new Sales(104L, LocalDate.of(2025, 02, 01),
BigDecimal.valueOf(Double.parseDouble("8476.34d")))));
}
}最後,我們有application.properties文件,其中配置了我們的數據庫連接。同時,還需要根據數據庫更新用户名和密碼。
spring.application.name=partitionKeyDemo
# PostgreSQL connection properties
spring.datasource.url=jdbc:postgresql://localhost:5432/salesTest
spring.datasource.username=username
spring.datasource.password=password5.3. 輸出
現在,當我們運行應用程序並訪問 http://localhost:8080/add 時,我們可以看到行已正確分區到 PostgreSQL 數據庫中:
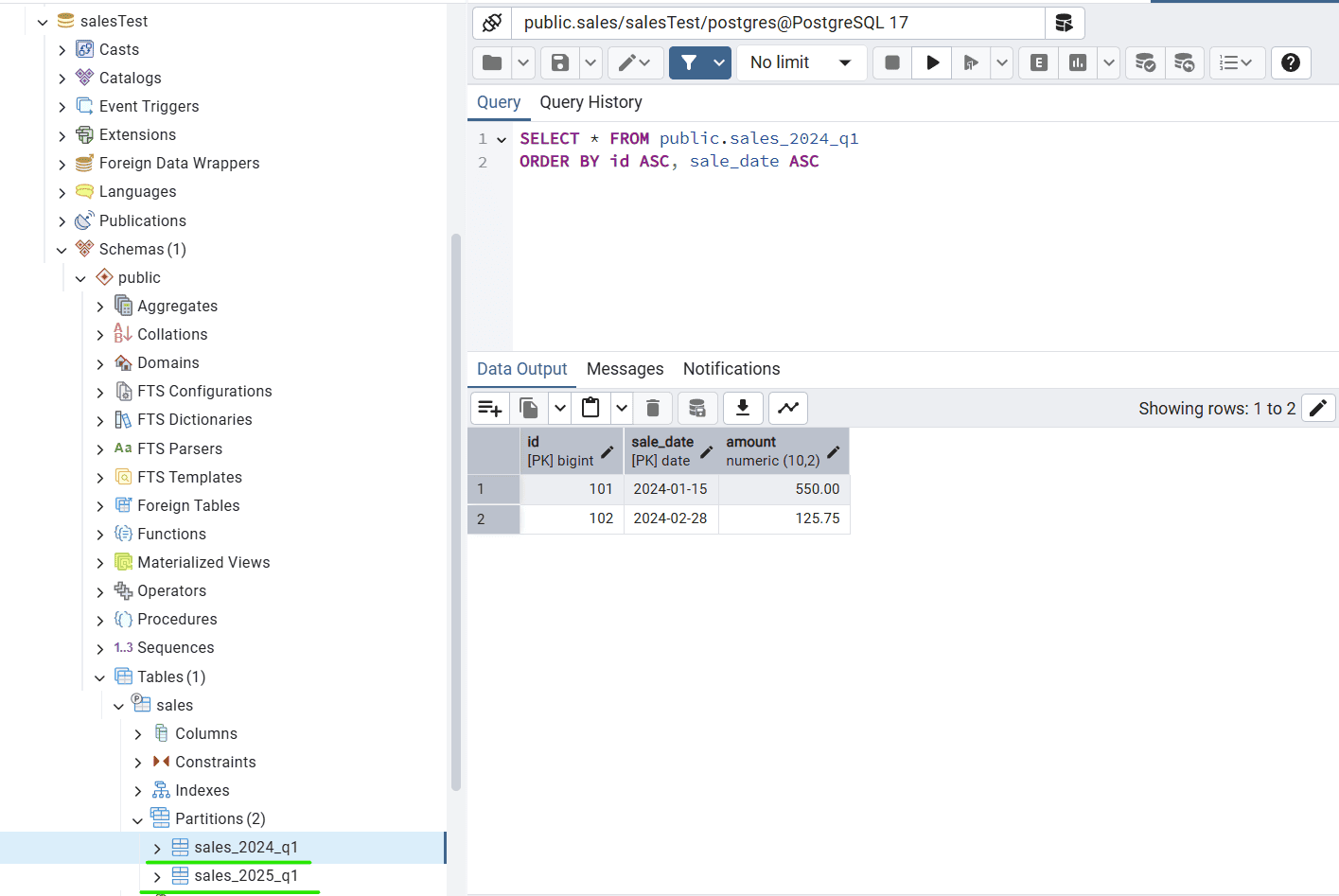
在這裏,我們看到左側面板創建了兩個分區。然後,我們可以運行查詢以自動檢索在正確分區中插入的行:
SELECT * FROM public.sales_2025_q1;6. 通過分表優化查詢
為了充分利用分表的好處,我們必須仔細設計查詢語句。 讓我們考慮一個場景,即我們要查找特定日期的所有銷售額。 一個精心設計的查詢語句可能如下所示:
SELECT * FROM sales WHERE sale_date = '2025-02-01';在這種情況下,數據庫可以利用分區鍵(sale_date)立即識別並搜索僅對應於‘2025-02-01’的分區,完全忽略所有其他分區。這是一個非常高效的操作。
但是,如果運行不包含分區鍵的查詢,例如:
SELECT * FROM sales WHERE amount > 5000;數據庫將強制掃描所有分區以查找匹配的記錄。這種類型的查詢被稱為全局掃描,並且它很可能比在未分區的、正確索引的表中執行的查詢性能要差得多。
7. 結論
在本教程中,我們探討了如何將 Hibernate 的實體映射與數據庫級別的分區結合使用,以在數據增長時保持性能的一致性。分區是一種強大的技術,可用於擴展我們的關係數據庫以處理大型數據集。
雖然實現方式位於數據庫層面,但 Hibernate 和 Spring Boot 提供了必要的工具,以便無縫地與這些結構進行交互。同時,為了充分利用分區鍵的優勢,需要構建涉及分區列的查詢。
