1. 概述
現代Web應用程序越來越多地與大型語言模型(LLM)集成,用於構建解決方案,這些解決方案不僅僅侷限於通用基於知識的問答。
為了增強人工智能模型的響應並使其更具上下文感知性,我們可以將其連接到外部源,如搜索引擎、數據庫和文件系統。但是,整合和管理多種格式和協議不同的數據源是一個挑戰。
模型上下文協議(MCP),由 Anthropic 引入,解決了這一集成挑戰,並提供了一種標準化的方法,將人工智能驅動的應用與外部數據源連接起來。通過 MCP,我們可以在原生 LLM 之上構建複雜的代理和工作流程。
在本教程中,我們將通過使用 Spring AI 實踐性地實現其客户端-服務器架構來理解 MCP 的概念。我們將創建一個簡單的聊天機器人,並通過 MCP 服務器擴展其功能,以執行 Web 搜索、執行文件系統操作和訪問自定義業務邏輯。
2. 模型上下文協議 101
在深入瞭解實現細節之前,讓我們更詳細地瞭解 MCP 及其各個組件:
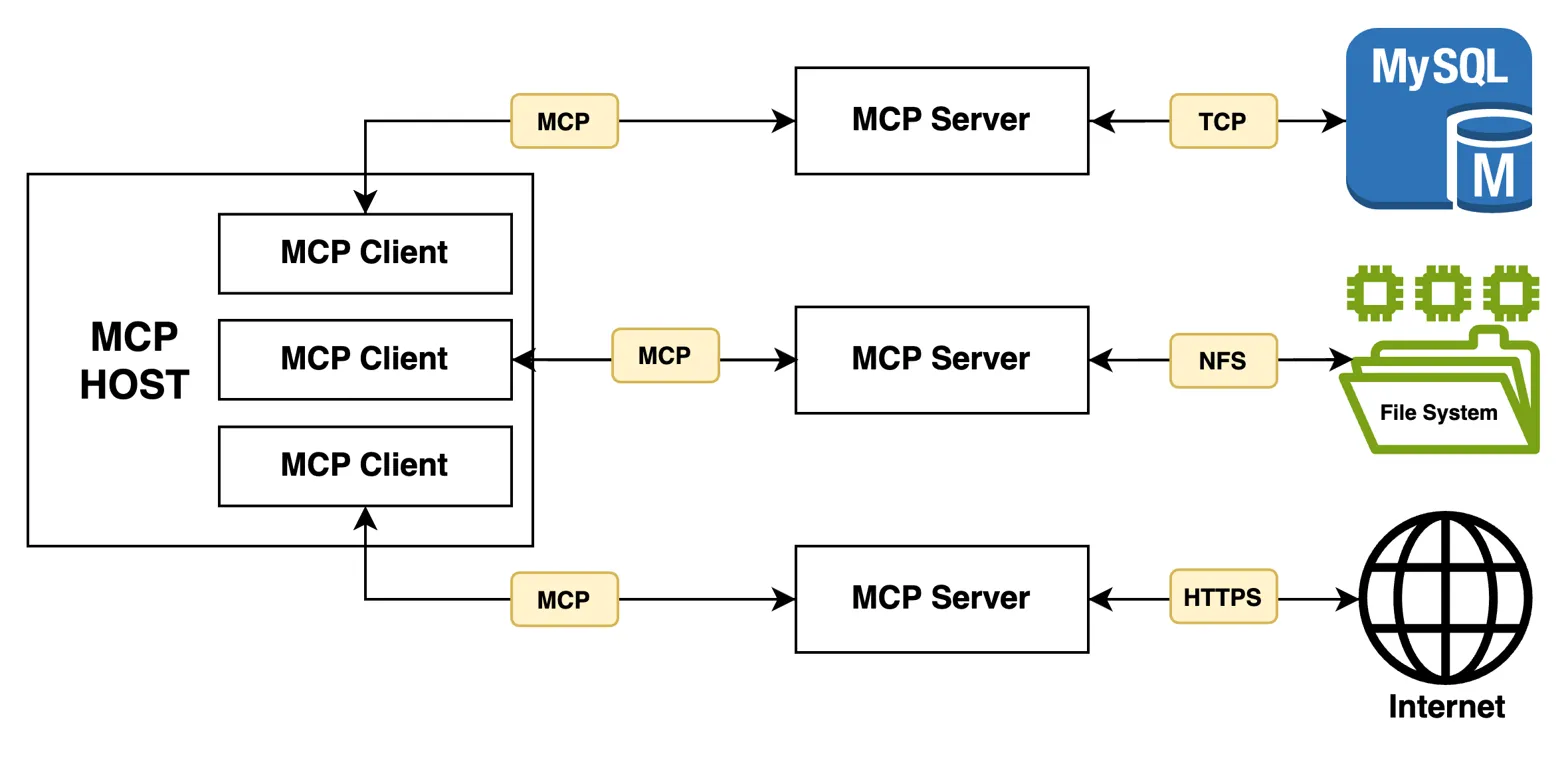
MCP 遵循客户端-服務器架構,圍繞着幾個關鍵組件展開:
- MCP 主機:是我們主要的應用程序,它與 LLM 集成,並需要與外部數據源進行連接。
- MCP 客户端:是組件,它們與 MCP 服務器建立並維護 1:1 連接。
- MCP 服務器:是組件,它們與外部數據源集成,並向客户端公開功能,以便與之交互。
- 工具:指 MCP 服務器向客户端提供的可執行函數/方法,供客户端調用。
此外,為了處理客户端與服務器之間的通信,MCP 提供兩個傳輸通道。
為了通過標準輸入/輸出流與本地進程和命令行工具進行通信,它提供了標準輸入/輸出 (stdio) 傳輸類型。 另一種選擇是,對於客户端和服務器之間基於 HTTP 的通信,它提供了服務器端事件 (SSE) 傳輸類型。
MCP 是一個複雜而龐大的主題,請參閲 官方文檔 以瞭解更多信息。
3. 創建 MCP 主機
現在我們對 MCP 有了初步的瞭解,接下來讓我們開始在實踐中實施 MCP 架構。
我們將使用 Anthropic 的 Claude 模型構建一個聊天機器人,該聊天機器人將作為我們的 MCP 主機。 此外,我們還可以通過 Hugging Face 或 Ollama 使用本地 LLM,因為具體的 AI 模型對本次演示並不重要。
3.1. 依賴項
讓我們首先添加必要的依賴項到我們項目的 pom.xml文件中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-anthropic</artifactId>
<version>1.0.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
<version>1.0.1</version>
</dependency>Anthropic starter依賴項 是對 Anthropic Message API 的封裝,我們將使用它來與我們的應用程序中的 Claude 模型進行交互。
此外,我們還導入了 MCP 客户端 starter 依賴項,該依賴項將允許我們在 Spring Boot 應用程序中配置與 MCP 服務器保持 1:1 連接的客户端。
鑑於我們項目中使用多個 Spring AI starter,我們還應該在 pom.xml 中包含 Spring AI Bill of Materials (BOM)。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>通過此次添加,我們現在可以將 版本 標籤從我們的啓動依賴項中移除。 BOM 消除了版本衝突的風險,並確保我們的 Spring AI 依賴項相互兼容。
接下來,讓我們在 Anthropic API 密鑰 和聊天模型在 application.yaml 文件中進行配置:
spring:
ai:
anthropic:
api-key: ${ANTHROPIC_API_KEY}
chat:
options:
model: claude-opus-4-20250514我們使用 ${} 屬性佔位符從環境變量中加載我們的 API 密鑰的值。
此外,我們指定了 Anthropic 的 Claude 4 Opus,使用 claude-opus-4-20250514 模型 ID。您可以根據需求自由探索和使用 不同的模型。
配置以上屬性時,Spring AI 自動創建一個類型為 ChatModel 的 Bean,從而使我們能夠與指定的模型進行交互。
3.2. 配置 MCP 客户端用於 Brave 搜索和文件系統服務器
現在,讓我們為以下兩個預構建的 MCP 服務器實現配置 MCP 客户端:Brave 搜索 和 文件系統。 這些服務器將使我們的聊天機器人能夠執行網絡搜索和文件系統操作。
讓我們首先在 application.yaml 文件中註冊一個 MCP 客户端用於 Brave 搜索 MCP 服務器:
spring:
ai:
mcp:
client:
stdio:
connections:
brave-search:
command: npx
args:
- "-y"
- "@modelcontextprotocol/server-brave-search"
env:
BRAVE_API_KEY: ${BRAVE_API_KEY}在這裏,我們配置了一個 客户端,使用 stdio 傳輸。 我們指定了 npx 命令來下載並運行基於 TypeScript 的 @modelcontextprotocol/server-brave-search 包,並使用 -y 標誌來確認所有安裝提示。
此外,我們提供了 BRAVE_API_KEY 作為環境變量。
接下來,讓我們為 Filesystem MCP 服務器配置一個 MCP 客户端:
spring:
ai:
mcp:
client:
stdio:
connections:
filesystem:
command: npx
args:
- "-y"
- "@modelcontextprotocol/server-filesystem"
- "./"類似於之前的配置,我們指定了用於運行 命令 和參數,以便運行 Filesystem MCP 服務器包。 這種設置允許我們的聊天機器人執行指定目錄中的創建、讀取和寫入文件等操作。
在這裏,我們僅配置當前目錄 (./) 用作文件系統操作,但是可以通過將它們添加到 args 列表中來指定多個目錄。
在應用程序啓動期間,Spring AI 將掃描我們的配置,創建 MCP 客户端並與它們的相應 MCP 服務器建立連接。 它還創建了一個類型為 SyncMcpToolCallbackProvider 的 Bean,該 Bean 提供配置的 MCP 服務器暴露的所有工具的列表。
3.3. 構建一個基本聊天機器人
有了我們的人工智能模型和 MCP 客户端配置完成,現在我們來構建一個簡單的聊天機器人:
@Bean
ChatClient chatClient(ChatModel chatModel, SyncMcpToolCallbackProvider toolCallbackProvider) {
return ChatClient
.builder(chatModel)
.defaultToolCallbacks(toolCallbackProvider.getToolCallbacks())
.build();
}我們首先通過使用 ChatClient 類型的 Bean 以及 ChatModel 和 SyncMcpToolCallbackProvider Bean 來創建一個 Bean。 ChatClient 類將作為我們與聊天完成模型(例如 Claude 4 Opus)交互的主要入口。
接下來,讓我們將 ChatClient Bean 注入,創建一個新的 ChatbotService 類:
String chat(String question) {
return chatClient
.prompt()
.user(question)
.call()
.content();
}我們創建了一個 chat() 方法,其中我們將用户的 問題 傳遞給 聊天客户端 Bean,並僅返回 AI 模型的響應。
現在我們已經實現了服務層,讓我們在之上暴露一個 REST API:
@PostMapping("/chat")
ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest chatRequest) {
String answer = chatbotService.chat(chatRequest.question());
return ResponseEntity.ok(new ChatResponse(answer));
}
record ChatRequest(String question) {}
record ChatResponse(String answer) {}我們稍後在教程中將使用上述 API 端點與我們的聊天機器人進行交互。
4. 創建自定義 MCP 服務器
除了使用預構建的 MCP 服務器外,我們可以創建自己的 MCP 服務器,以通過我們的業務邏輯擴展聊天機器人的功能。
讓我們探索如何使用 Spring AI 創建自定義 MCP 服務器。
在本節中,我們將創建一個新的 Spring Boot 應用程序。
4.1. 依賴項
首先,在我們的 pom.xml 文件中包含必要的依賴項:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
<version>1.0.0</version>
</dependency>我們導入了 Spring AI 的 MCP 服務器依賴項,它提供了創建支持基於 HTTP 的 SSE 傳輸的自定義 MCP 服務器所需的類。
4.2. 定義和暴露自定義工具
接下來,讓我們定義一些將暴露到我們的 MCP 服務器的自定義工具。
我們將創建一個 AuthorRepository 類,該類提供方法以檢索作者信息:
class AuthorRepository {
@Tool(description = "Get Baeldung author details using an article title")
Author getAuthorByArticleTitle(String articleTitle) {
return new Author("John Doe", "[email protected]");
}
@Tool(description = "Get highest rated Baeldung authors")
List<Author> getTopAuthors() {
return List.of(
new Author("John Doe", "[email protected]"),
new Author("Jane Doe", "[email protected]")
);
}
record Author(String name, String email) {
}
}為了演示,我們返回硬編碼的作者信息,但在實際應用中,工具通常會與數據庫或外部 API 交互。
我們對這兩個方法進行了 @Tool 註解,併為每個方法提供了一個簡短的 描述。 該 描述 幫助 AI 模型根據用户輸入決定何時以及何時調用工具,並將結果納入其響應中。
接下來,讓我們將作者工具註冊到 MCP 服務器上:
@Bean
ToolCallbackProvider authorTools() {
return MethodToolCallbackProvider
.builder()
.toolObjects(new AuthorRepository())
.build();
}我們使用 MethodToolCallbackProvider 創建一個 ToolCallbackProvider Bean,該 Bean 來自我們 AuthorRepository 類中定義的工具。 帶有 @Tool 註解的方法會在應用程序啓動時作為 MCP 工具暴露。
或者,我們可以根據特定條件在運行時動態註冊工具:
@Bean
CommandLineRunner commandLineRunner(
McpSyncServer mcpSyncServer,
@Value("${com.baeldung.author-tools.enabled:false}") boolean authorToolsEnabled
) {
return args -> {
if (authorToolsEnabled) {
ToolCallback[] toolCallbacks = ToolCallbacks.from(new AuthorRepository());
List<SyncToolSpecification> tools = McpToolUtils.toSyncToolSpecifications(toolCallbacks);
tools.forEach(tool -> {
mcpSyncServer.addTool(tool);
mcpSyncServer.notifyToolsListChanged();
});
}
};
}在這裏,我們注入了由 Spring AI 自動創建的 McpSyncServer Bean,用於根據配置屬性條件註冊我們的工具。 類似於 addTool() 方法,McpSyncServer 類也提供了 removeTool() 方法,用於移除某些工具。
為了演示目的,我們使用了 CommandLineRunner 接口;但是,當通過 REST API 調用或響應應用程序事件時,也可以添加/移除工具。 這對於根據用户權限、訂閲級別或其他業務邏輯啓用或禁用功能尤其 有用。
4.3. 為我們的自定義 MCP 服務器配置 MCP 客户端
要將我們的自定義 MCP 服務器集成到聊天機器人應用程序中,我們需要針對該服務器配置一個 MCP 客户端:
spring:
ai:
mcp:
client:
sse:
connections:
author-tools-server:
url: http://localhost:8081在 application.yaml 文件中,我們配置了一個新的客户端,用於連接我們的自定義 MCP 服務器。請注意,我們在這裏使用了 SSE 傳輸類型。
此配置假設 MCP 服務器正在運行在 http://localhost:8081。如果它運行在不同的主機或端口上,則需要確保更新 url。
此外,如果我們在運行時啓用了 MCP 服務器動態添加或刪除工具功能,我們可以註冊一個監聽器來檢測這些工具變更:
@Bean
McpSyncClientCustomizer mcpSyncClientCustomizer() {
return (name, mcpClientSpec) -> {
mcpClientSpec.toolsChangeConsumer(tools -> {
logger.info("Detected tools changes.");
});
};
}在這裏,我們定義了一個類型為 McpSyncClientCustomizer 的 Bean,並使用 toolsChangeConsumer() 方法註冊了一個監聽器。雖然這裏只是為了簡化目的而進行日誌記錄,但在實際應用中,我們可以刷新 ChatClient Bean 或通過編程方式重啓我們的應用程序。
採用這種配置,我們的 MCP 客户端現在可以調用我們自定義服務器提供的工具,以及 Brave Search 和 Filesystem MCP 服務器提供的工具。
5. 與我們的聊天機器人交互
現在我們已經構建了聊天機器人並將其集成到各種MCP服務器中,讓我們與它進行交互並對其進行測試。
我們將使用HTTPie CLI來調用聊天機器人的API端點:
http POST :8080/chat question="How much was Elon Musk's initial offer to buy OpenAI in 2025?"在這裏,我們向聊天機器人發送一個關於在LLM的知識截止日期之後發生的事件的簡單問題。讓我們看看我們得到什麼樣的回覆:
Here, we send a simple question to the chatbot about an event that occurred after the LLM’s knowledge cut-off date. Let’s see what we get as a response:
{
"answer": "Elon Musk's initial offer to buy OpenAI was $97.4 billion. [Source](https://www.reuters.com/technology/openai-board-rejects-musks-974-billion-offer-2025-02-14/)."
}如我們所見,聊天機器人能夠使用配置好的 Brave Search MCP 服務器進行網頁搜索,並提供準確答案和來源。
接下來,讓我們驗證聊天機器人是否能夠使用 Filesystem MCP 服務器執行文件系統操作:
http POST :8080/chat question="Create a text file named 'mcp-demo.txt' with content 'This is awesome!'."我們指示聊天機器人創建一個名為 mcp-demo.txt 的文件,其中包含特定內容。 讓我們看看它是否能夠滿足這個要求:
{
"answer": "The text file named 'mcp-demo.txt' has been successfully created with the content you specified."
}聊天機器人返回成功響應。我們可以驗證文件是否已在指定目錄中創建,具體配置在 application.yaml文件中。
最後,讓我們驗證聊天機器人是否可以調用我們自定義 MCP 服務器提供的工具。我們將通過提及文章標題來查詢作者信息:
http POST :8080/chat question="Who wrote the article 'Testing CORS in Spring Boot?' on Baeldung, and how can I contact them?"讓我們調用API,看看聊天機器人響應中是否包含硬編碼的作者信息:
{
"answer": "The article 'Testing CORS in Spring Boot' on Baeldung was written by John Doe. You can contact him via email at [[email protected]](mailto:[email protected])."
}上述響應驗證了聊天機器人通過自定義 MCP 服務器提供的 getAuthorByArticleTitle() 工具來獲取作者信息的。
我們強烈建議您本地設置代碼庫並使用不同的提示與聊天機器人進行交互。
6. 結論
在本文中,我們探討了模型上下文協議(Model Context Protocol,簡稱MCP)並使用 Spring AI 實現了其客户端-服務器架構。
首先,我們使用 Anthropic 的 Claude 4 Opus 模型構建了一個簡單的聊天機器人,作為我們的 MCP 服務器。
然後,為了為聊天機器人提供網絡搜索能力並使其能夠執行文件系統操作,我們配置了 MCP 客户端,針對 Brave Search API 和 Filesystem 的預構建 MCP 服務器進行了配置。
最後,我們創建了一個自定義的 MCP 服務器,並在我們的 MCP 託管應用程序中配置了其對應的 MCP 客户端。
