1. 引言
在本文中,我們將探索 Faunia 分佈式數據庫。 我們將瞭解它為我們的應用程序帶來哪些功能,以及我們可以用它做什麼,以及如何與之交互。
注意: 本文使用了 Faunia 查詢語言的舊版本。請參閲 Fauna 的文檔 以獲取查詢語言的最新版本。
2. 什麼是 Fauna?
Fauna 是一個多協議、多模型、多租户、分佈式、事務型數據庫即服務 (DBaaS) 解決方案。 聽起來有些複雜,我們來簡單分析一下。
2.1 數據庫即服務
“數據庫即服務”意味着數據庫由雲服務提供商託管,他們負責所有基礎設施和維護工作,從而使我們只需關注特定領域的細節,例如:集合、索引、查詢等。 這種方式有助於消除管理此類系統的複雜性,同時又能充分利用其功能。
2.2. 分佈式事務數據庫
分佈式意味着數據庫運行在多台服務器上。
這有助於提高效率並同時使其更具容錯性。如果一台服務器發生故障,整個數據庫仍然能夠正確地繼續工作。
事務性意味着數據庫提供對數據有效性的強保證。在一個事務中執行的數據更新要麼成功,要麼失敗,整體不會出現數據處於部分狀態的風險。
作為進一步的措施,Fauna 提供隔離級別,以確保在多節點分佈式環境中執行多個事務的結果始終正確。這對於分佈式數據庫來説至關重要——否則,不同的事務可能在不同的節點上以不同的方式執行,並可能導致不同的結果。
例如,考慮以下事務應用於同一記錄:
- 將值設置為“15”
- 將值增加“3”
如果按照順序執行,最終結果將為“18”。但是,如果反向執行,最終結果將為“15”。如果結果在同一系統中不同節點上不同,這會更加令人困惑,因為這意味着節點之間的數據不一致。
2.3. 多模型數據庫
多模型數據庫意味着它允許我們以不同的方式在同一個數據庫引擎中建模不同類型的數據,並可通過相同的連接訪問。
內部而言,Fauna 是一種文檔數據庫。這意味着它將每個記錄存儲為結構化文檔,使用 JSON 表示任意形狀。這使得 Fauna 能夠作為鍵值存儲使用——文檔只需包含一個字段value——或者作為表格存儲使用——文檔可以包含所需的任何字段,但所有字段都是扁平化的。然而,我們還可以存儲更復雜的文檔,包括嵌套字段、數組等。
// Key-Value document
{
"value": "Baeldung"
}
// Tabular document
{
"name": "Baeldung",
"url": "https://www.baeldung.com/"
}
// Structured document
{
"name": "Baeldung",
"sites": [
{
"id": "cs",
"name": "Computer Science",
"url": "https://www.baeldung.com/cs"
},
{
"id": "linux",
"name": "Linux",
"url": "https://www.baeldung.com/linux"
},
{
"id": "scala",
"name": "Scala",
"url": "https://www.baeldung.com/scala"
},
{
"id": "kotlin",
"name": "Kotlin",
"url": "https://www.baeldung.com/kotlin"
},
]
}我們還擁有一些在關係數據庫中常見的特性。具體來説,我們可以為文檔創建索引,以提高查詢效率,同時可以跨多個集合應用約束,以確保數據的一致性,並一次性執行跨多個集合的查詢。
Fauna 的查詢引擎還支持圖查詢,允許我們構建跨多個集合的複雜數據結構,並像訪問單個數據圖一樣訪問它們。
最後,Fauna 具有時間建模功能,可以讓我們與數據庫在任何時間點進行交互。這意味着我們不僅可以查看記錄隨時間的變化,還可以直接訪問在給定時間點的數據。
<h3><strong>2.4. 多租户數據庫</strong></h3>
<p><strong>多租户數據庫服務器意味着它支持不同用户使用的多個不同數據庫。</strong> 這在用於雲託管的數據庫引擎中非常常見,因為這意味着一個服務器可以支持許多不同的客户。</p>
<p>Fauna 在這一點上採取了稍微不同的方向。 相反於不同的租户代表單個安裝的數據庫引擎中的不同客户,Fauna 使用租户來代表單個客户的不同數據子集。</p>
<p><strong>有可能創建數據庫,這些數據庫本身是其他數據庫的子數據庫。</strong> 我們可以創建訪問這些子數據庫的憑據。 然而,Fauna 的不同之處在於,我們可以對連接到的一個數據庫的子數據庫中的數據執行只讀查詢。 但是,無法訪問父數據庫或兄弟數據庫中的數據。</p>
<p>這使得我們可以為同一父數據庫中的不同服務創建子數據庫,然後管理員用户可以一次查詢所有數據的分析目的非常方便。</p>
2.5. 多協議數據庫
這意味着我們有多種不同的方式來訪問相同的數據。
訪問我們數據庫的標準方式是使用 Fauna 查詢語言 (FQL) 通過提供的驅動程序。這使我們能夠充分利用數據庫引擎的能力,並以我們需要的任何方式訪問所有數據。
此外,Fauna 還暴露了一個 GraphQL 端點,我們可以使用它。它的優勢在於,無論使用什麼編程語言,都可以從任何應用程序中使用它,而無需依賴特定語言的專用驅動程序。然而,並非所有功能都可通過此接口提供。特別是,我們必須在先創建 GraphQL 模式,描述我們數據的形狀,這意味着我們無法在同一集合中創建具有不同形狀的不同記錄。
3. 創建 Fauna 數據庫
現在我們知道 Fauna 能為我們做什麼,接下來我們來創建一個數據庫供我們使用。
如果還沒有賬户,我們需要創建一個。
登錄後,在儀表盤上,我們只需點擊“創建數據庫”鏈接:
這將打開一個用於指定數據庫名稱和區域的面板。我們還可以在創建時預填充數據庫,使用一些示例數據,以便更好地瞭解系統:
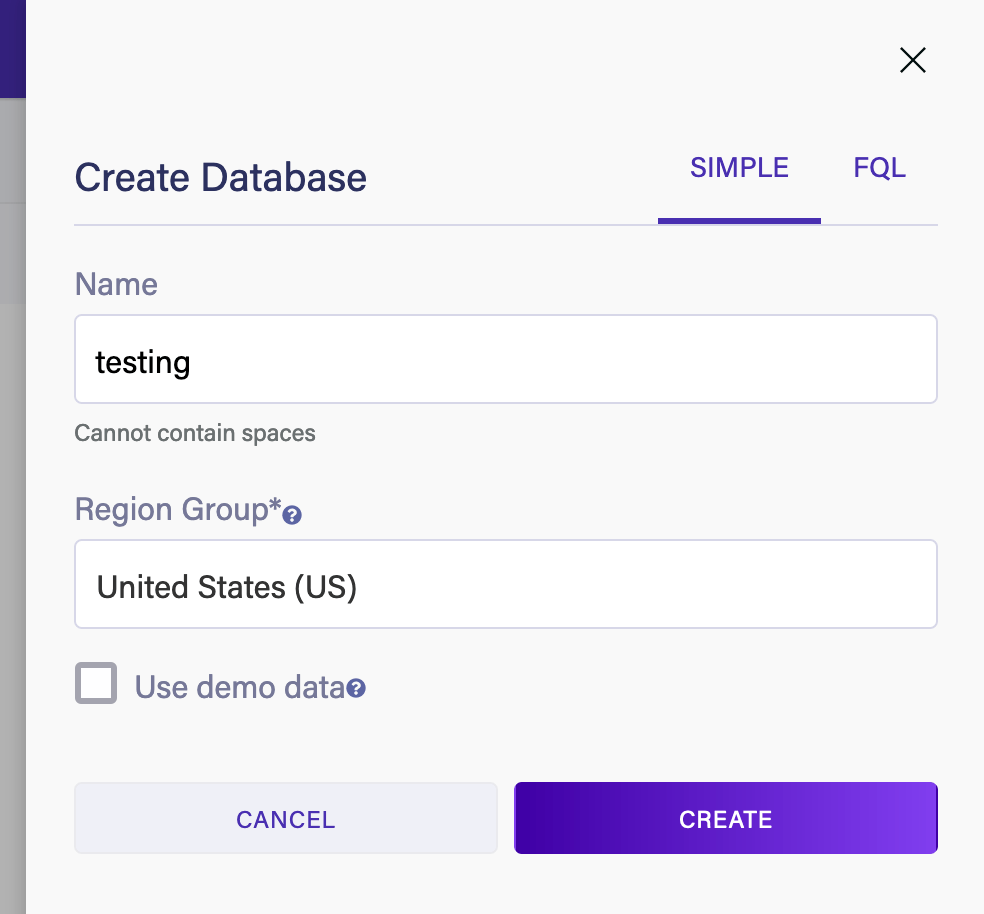
在“區域組”選項中,選擇很重要,因為它不僅影響超出免費限制的費用,還影響我們連接到數據庫的端點。
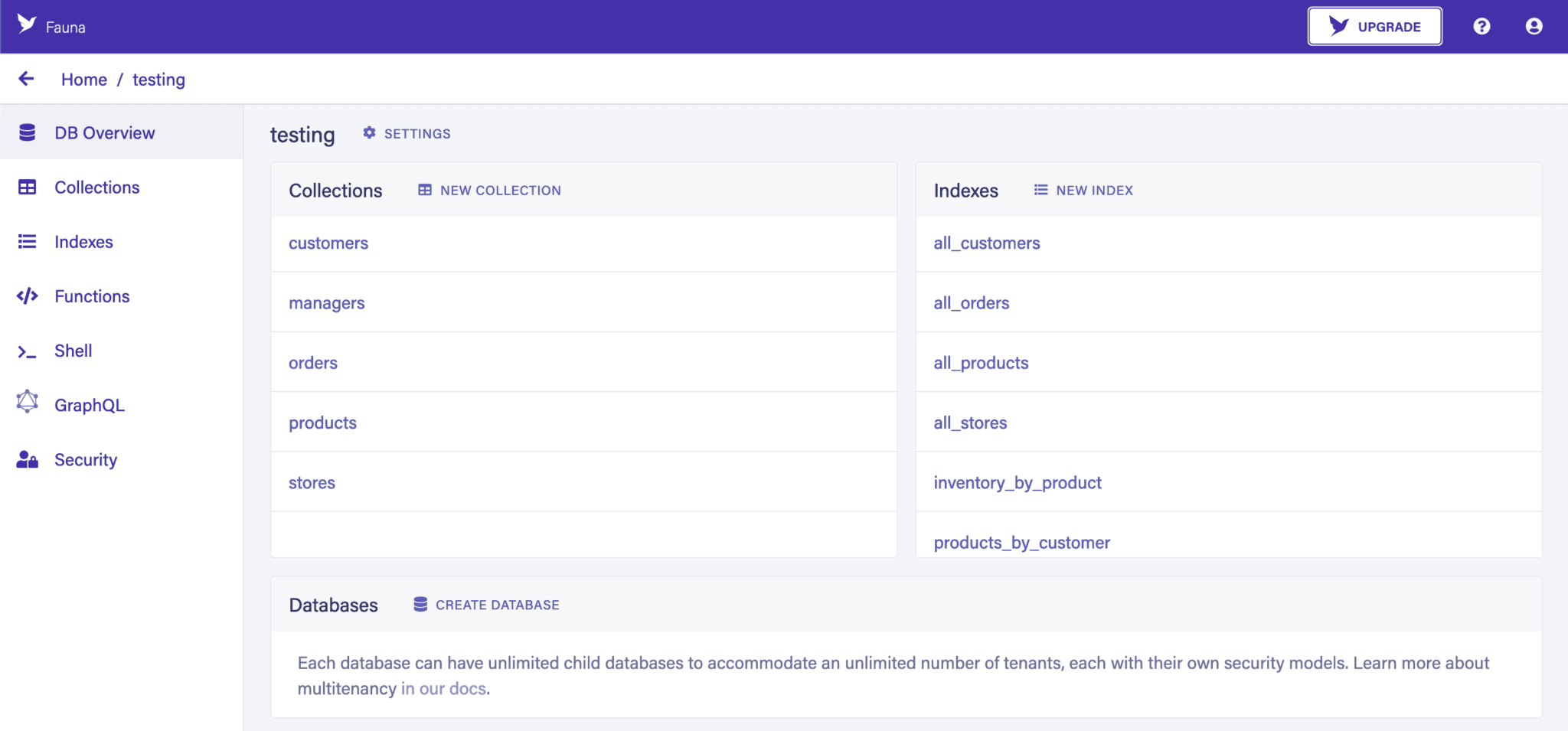
完成這些步驟後,我們就可以使用一個完整的數據庫。如果選擇了演示數據,它將包含一些填充的集合、索引、自定義函數和 GraphQL 模式。如果沒有,數據庫將完全為空,隨時準備好我們創建所需的結構:
最後,為了從外部連接到數據庫,我們需要一個身份驗證密鑰。我們可以從側邊欄的“安全”選項卡中創建它:
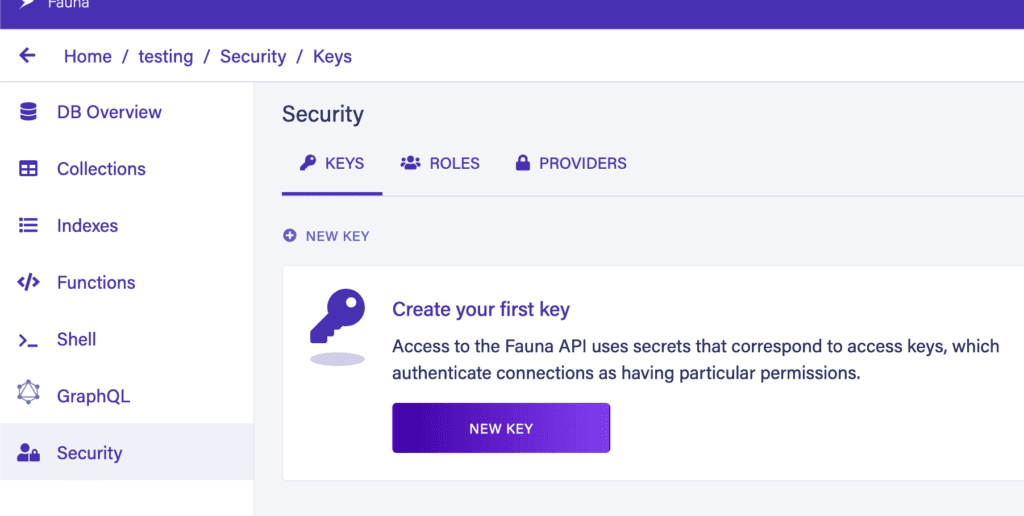
創建新密鑰時,請務必將其複製下來,因為出於安全原因,離開屏幕後將無法再次獲取它。
4. 與Fauna交互
現在我們已經擁有數據庫,就可以開始與之交互。
Fauna 提供兩種不同的方式來從外部讀取和寫入數據庫中的數據:FQL 驅動程序和 GraphQL API。 此外,我們還可以訪問 Fauna Shell,它允許我們在 Web UI 中執行任意命令。
4.1. Faun Shell
Faun Shell 允許我們在 Web UI 中執行任何命令。我們可以使用我們配置好的任何密鑰——這與我們通過該密鑰從外部連接時完全相同,或者使用某些特殊管理員連接:
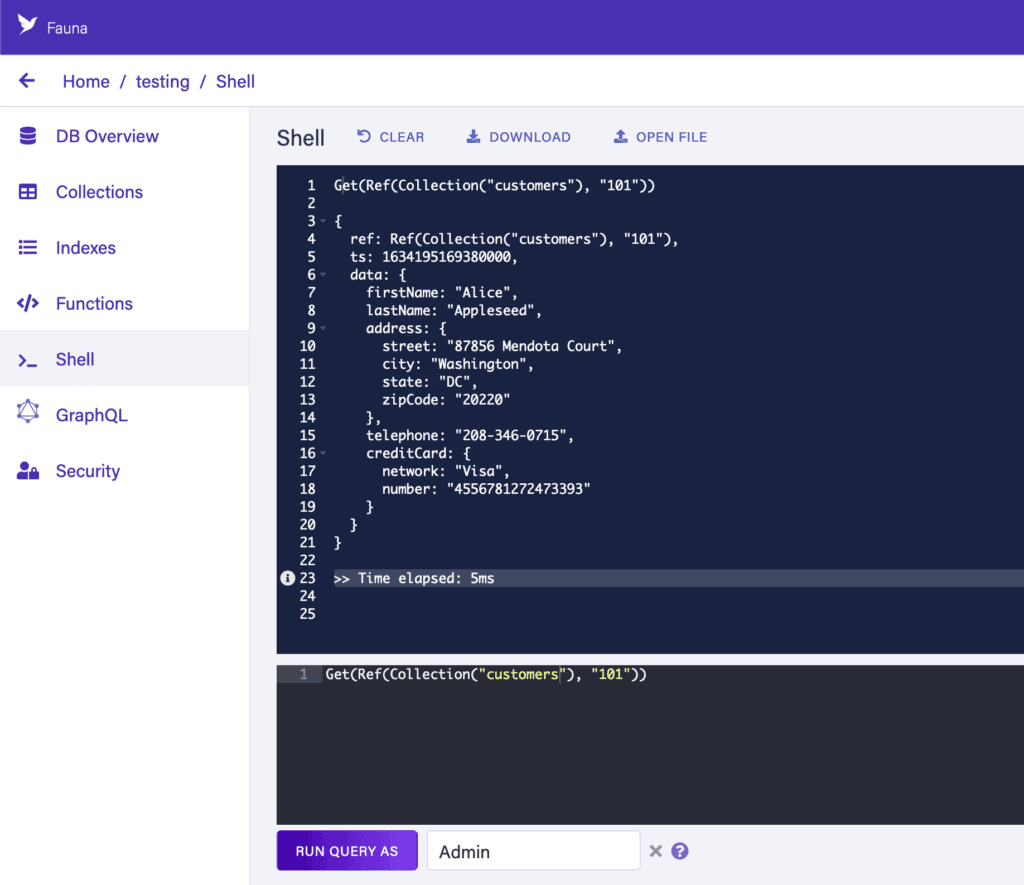
這使得我們能夠以非常低摩擦的方式探索我們的數據並測試我們希望在應用程序中使用查詢。
4.2. 使用 FQL 連接
如果我們希望將應用程序連接到 Fauna 並使用 FQL,則需要使用提供的驅動程序之一——包括 Java 和 Scala 驅動程序。
Java 驅動程序要求我們運行 Java 11 或更高版本。
首先,我們需要添加依賴項。如果使用 Maven,則只需將其添加到 pom.xml 文件中:
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>我們還需要創建一個客户端連接,以便與數據庫進行通信:
FaunaClient client = FaunaClient.builder()
.withEndpoint("https://db.us.fauna.com/")
.withSecret("put-your-authorization-key-here")
.build();請注意,我們需要提供正確的數據庫端點值,該值取決於數據庫創建時所選的區域組,以及我們之前創建的密鑰。
此客户端將作為連接池,根據不同的查詢需求,按需打開新的數據庫連接。這意味着我們可以將其在應用程序啓動時創建一次,並在需要時重用它。
如果我們需要使用不同的密鑰連接,則需要不同的客户端。例如,如果要在同一父數據庫中與多個不同的子數據庫進行交互。
現在我們已經有了客户端,可以使用它向數據庫發送查詢:
client.query(
language.Get(language.Ref(language.Collection("customers"), 101))
).get();4.3. 通過 GraphQL 連接
Fauna 提供了一個完整的 GraphQL API,用於與我們的數據庫交互。這允許我們無需任何特殊驅動程序即可使用數據庫,只需要一個 HTTP 客户端。
為了使用 GraphQL 支持,我們首先需要創建一個 GraphQL 模式(Schema)。這將定義模式本身以及它如何映射到現有的 Fauna 數據庫構造體——例如集合、索引和函數。完成之後,任何具有 GraphQL 意識的客户端(包括甚至只是像 <em >RestTemplate</em> 這樣的 HTTP 客户端)都可以用來調用我們的數據庫。
請注意,這僅允許我們與數據庫中的數據進行交互。如果希望使用任何管理命令——例如創建新的集合或索引——則需要使用 FQL 命令或 Web 管理 UI。
通過 GraphQL 連接 Fauna 需要使用正確的 URL——對於美國區域,它是 https://graphql.us.fauna.com/graphql,並提供我們的認證密鑰作為 Bearer 令牌,在 <em >Authorization</em> 標頭中。 在此時,我們可以將其用作任何正常的 GraphQL 端點,通過向 URL 發送 POST 請求並提供主體中的查詢或 mutation(可選地帶有任何變量)來使用它。
5. 使用 Fauna 從 Spring
現在我們已經瞭解了 Fauna 是什麼以及如何使用它,就可以看到如何將其集成到我們的 Spring 應用程序中。
Fauna 沒有原生 Spring 驅動程序。相反,我們將配置正常的 Java 驅動程序作為 Spring 豆以供在我們的應用程序中使用。
5.1. 生物羣系配置
在我們可以利用生物羣系之前,我們需要進行一些配置。 具體來説,我們需要知道我們的生物羣系數據庫所在的區域——由此我們可以推導出適當的 URL,並且我們需要知道一個密鑰,用於連接到數據庫。
為此,我們將向 application.properties 文件添加 fauna.region 和 fauna.secret 屬性——或者使用任何其他受支持的 Spring 配置方法:
fauna.region=us
fauna.secret=FaunaSecretHere請注意,我們在這裏定義了 Fauna 區域,而不是 URL。這使得我們能夠從同一個設置中正確地推導出 FQL 和 GraphQL 的 URL。 這樣可以避免我們配置這兩個 URL 不同的風險。
5.2. FQL 客户端
如果我們的應用程序計劃使用 FQL,我們可以向 Spring 上下文中添加一個 FaunaClient bean。 這將涉及創建 Spring 配置對象以消費適當的屬性並構造 FaunaClient 對象:
@Configuration
class FaunaClientConfiguration {
@Value("https://db.${fauna.region}.fauna.com/")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
@Bean
FaunaClient getFaunaClient() throws MalformedURLException {
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}
}
這使得我們能夠直接使用 FaunaClient 在應用程序的任何地方,就像我們使用 JdbcTemplate 訪問 JDBC 數據庫一樣。我們還可以在必要時將其封裝在一個更高層次的對象中,以使用領域特定術語。
5.3. GraphQL 客户端
如果我們要使用 GraphQL 來訪問 Fauna,則需要進行一些額外的工作。GraphQL API 調用沒有標準客户端。相反,我們將使用 Spring RestTemplate 向 GraphQL 端點發出標準 HTTP 請求。 如果我們正在構建基於 WebFlux 的應用程序,則較新的 WebClient 同樣可以工作。
要實現這一點,我們將編寫一個封裝 RestTemplate 的類,並可以向 Fauna 發出適當的 HTTP 調用:
@Component
public class GraphqlClient {
@Value("https://graphql.${fauna.region}.fauna.com/graphql")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
private RestTemplate restTemplate = new RestTemplate();
public <T> T query(String query, Class<T> cls) {
return query(query, Collections.emptyMap(), cls);
}
public <T, V> T query(String query, V variables, Class<T> cls) {
var body = Map.of("query", query, "variables", variables);
var request = RequestEntity.post(faunaUrl)
.header("Authorization", "Bearer " + faunaSecret)
.body(body);
var response = restTemplate.exchange(request, cls);
return response.getBody();
}
}此客户端允許我們從應用程序的其他組件中向Fauna發出GraphQL請求。我們有兩個方法,一個只接受GraphQL查詢字符串,另一個則接受一些變量以便使用它。
它們也都接受用於將查詢結果反序列化到指定類型的參數。使用此參數將處理與Fauna的所有細節,從而使我們能夠專注於應用程序的需求,而不是陷入細節。
6. 概述
本文對 Fauna 數據庫進行了簡要介紹,展示了其提供的部分功能,使其成為我們下一次項目的有力選擇,同時還展示了我們如何從應用程序中與之交互
為什麼不探索一下我們提到的這些功能,並在您的下一次項目中應用它們?
