1. 概述
Protocol Buffers (Protobuf) 和 JSON 都是流行的數據序列化格式,但它們在可讀性、性能、效率和大小方面存在顯著差異。
在本教程中,我們將比較這兩種格式,並探討它們的優缺點。這將幫助我們根據使用場景做出明智的決策,從而選擇最適合的格式。
2. 可讀性和模式要求
Protocol Buffers(protobuf)需要預定義的模式來定義數據的結構。 這是一個嚴格的要求,如果沒有它,我們的應用程序無法解釋二進制數據。
為了更好地理解,讓我們來看一個示例 schema.proto 文件:
syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
string email = 3;
}
message UserList {
repeated User users = 1;
}進一步來説,如果我們在 base64 編碼中看到一個 Protobuf 消息,它缺乏可讀性:
ChwKBUFsaWNlEB4aEWFsaWNlQGV4YW1wbGUuY29tChgKA0JvYhAZGg9ib2JAZXhhbXBsZS5jb20=我們的應用程序只能將此數據與模式文件結合解釋。
另一方面,如果我們用 JSON 格式表示相同的數據,則無需依賴任何嚴格的模式:
{
"users": [
{
"name": "Alice",
"age": 30,
"email": "[email protected]"
},
{
"name": "Bob",
"age": 25,
"email": "[email protected]"
}
]
}
此外,編碼後的數據完全可讀。
但是,如果我們的項目需要對 JSON 數據進行嚴格驗證,我們可以使用 JSON Schema,這是一種強大的工具,用於定義和驗證 JSON 數據的結構。雖然它提供了顯著的優勢,但使用它是可選的。
3. 模式演進
Protobuf 強制執行嚴格的模式,確保強大的數據完整性,而 JSON 則可以支持 採用模式-讀取 的數據處理方式。 讓我們學習兩種數據格式如何支持底層數據模式的演進,但方式不同。
3.1. 消費端向後兼容性
向後兼容性意味着新的代碼仍然可以讀取由舊代碼寫入的數據。 因此,較新版本必須正確地反序列化使用舊模式序列化的數據。
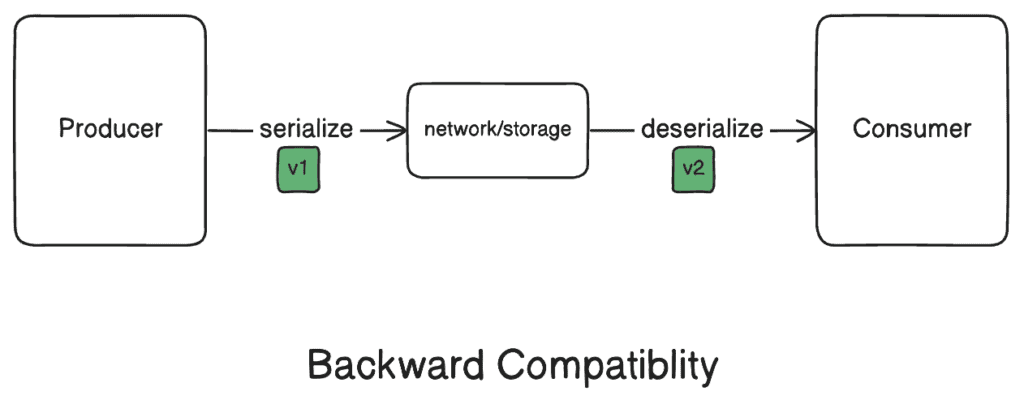
為了確保與 JSON 的向後兼容性,應用程序應設計為在反序列化過程中忽略未識別的字段。 此外,消費者應為未設置的字段提供默認值。 使用 Protocol Buffers,我們可以直接在模式本身中添加默認值,從而增強兼容性並簡化數據處理。
此外,任何 Protocol Buffers 模式更改都應遵循 最佳實踐,以保持向後兼容性。 如果我們添加了一個新字段,則必須使用先前未使用的唯一字段編號。 同樣,我們需要棄用未使用的字段,並將其保留下來,以防止字段編號的重用,從而不會破壞向後兼容性。
雖然我們可以在使用兩種格式的同時保持向後兼容性,但 Protocol Buffers 的機制更正式且嚴格。
3.2. 消費端向前兼容性
向前兼容性意味着舊代碼可以讀取由新代碼寫入的數據。 這要求舊版本正確地反序列化由新方案版本序列化的數據。
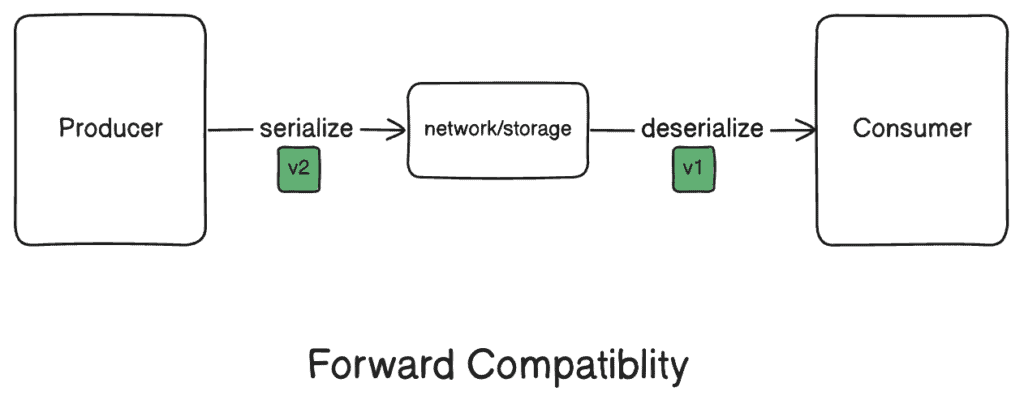
由於舊代碼無法預測數據語義中可能發生的潛在所有更改,因此維護向前兼容性會更加困難。 為了實現向前兼容性,舊代碼必須忽略未知屬性,並依賴新方案來保持原始數據語義。
在 JSON 的情況下,應用程序應設計為顯式忽略未知字段,這很容易通過大多數 JSON 解析器實現。 另一方面,Protocol Buffers 內置了忽略未知字段的功能。 因此,Protocol Buffers 可以有信心隨着新方案的發展而演進,因為未知字段將被忽略。
最後,請注意,在兩種情況下,刪除強制字段將破壞向前兼容性。 因此,推薦的做法是標記字段為棄用,並逐步刪除它們。 在 JSON 的情況下,一種常見做法是在文檔中標記字段為棄用,並告知消費者。 另一方面,Protocol Buffers 允許在方案定義中提供更正式的機制來 標記字段為棄用。
4. 序列化、反序列化與性能
JSON 序列化涉及將對象轉換為基於文本的格式。另一方面,Protobuf 序列化將對象轉換為緊湊的二進制格式,同時遵守來自 .proto 模式文件的定義。
由於 Protobuf 可以引用模式以識別字段名稱,因此在序列化時無需將其與數據一起保留這些名稱。因此,Protobuf 格式比 JSON 格式更節省空間,因為 JSON 格式會保留字段名稱。
設計上,Protobuf 通常在效率和性能方面優於 JSON。 它通常佔用更少的存儲空間,並且通常比 JSON 數據格式更快地完成序列化和反序列化過程。
5. 使用 JSON 的時機
JSON 是 RESTful 服務(尤其是 Web API)中的事實標準。這主要歸功於其豐富的工具、庫生態系統以及與 JavaScript 的內在兼容性。
此外,其基於文本的特性使其易於調試和編輯。因此,使用 JSON 作為配置數據是一個自然的選擇,因為配置應該易於人類理解和編輯。
另一個有趣的用例是在使用 JSON 格式記錄日誌。由於其無模式特性,它提供了在將來自不同應用程序的日誌收集到集中位置的極佳靈活性,而無需維護嚴格的模式。
最後,重要的是要注意,在使用 Protobuf 時,需要專門的模式感知客户端和額外的工具,而對於 JSON,由於 JSON 是一種純文本格式,因此不需要任何特殊客户端。因此,由於 JSON 允許我們以更少的努力引入更改,因此在開發原型或 MVP 解決方案時,我們很可能會受益於 JSON 格式。
6. 使用 Protocol Buffers 的時機
Protocol Buffers 在存儲和網絡傳輸方面相當高效。此外,它們通過定義模式嚴格強制執行數據完整性規則。因此,我們很可能會從中受益,尤其是在此類用例中。
處理實時分析、遊戲和金融系統等應用通常需要超高性能。因此,我們必須評估在這些場景中使用 Protobuf 的可能性,尤其是在內部通信中。
此外,分佈式數據庫系統可以從 Protocol Buffers 的小內存佔用量中受益。因此,Protocol Buffers 是編碼數據和元數據的一種極佳選擇,以實現高效的數據存儲和數據訪問的高性能。
7. 結論
在本文中,我們探討了 JSON 和 Protocol Buffers 數據格式的關鍵差異,旨在幫助我們為應用程序制定知情的編碼策略。
JSON 的可讀性和靈活性使其非常適合用於諸如 Web API、配置文件和日誌記錄等用例。相比之下,Protocol Buffers 提供了卓越的性能和效率,使其適用於實時分析、遊戲和分佈式存儲系統。
